
Mon plan initial était de couvrir ce sujet: «Comment créer un bot pour automatiser vos tâches sans esprit à l'aide de Python et BigQuery». J'ai fait quelques légers changements de parcours, mais j'espère que l'intention initiale reste la même!
L’inspiration pour cet article vient de ce tweet de JR Oakes. 🙂
Je pense avoir juste l'inspiration que je cherchais pour mon prochain @sejournal colonne "Comment construire un bot pour automatiser vos tâches insensées en utilisant #python et @bigquery"🤓 Merci JR! https://t.co/dQqULIH2p2
– Hameau 🇩🇴 (@hamletbatista) 12 juillet 2019
Comme Uber a publié un version mise à jour de Ludwig et Google a également annoncé la possibilité d’exécuter des modèles Tensorflow dans BigQuery. J’ai pensé que le timing ne pourrait pas être meilleur.
Dans cet article, nous allons revenir sur le problème de la classification d'intention Je me suis adressé avant, mais nous allons remplacer notre encodeur original par un encodeur à la pointe de la technologie: BERT, qui signifie Représentations de codeurs bidirectionnels à partir de transformateurs.
Ce petit changement nous aidera à améliorer la précision du modèle d’une précision de test combinée de 0,66 à 0,89 tout en utilisant le même jeu de données et sans codage personnalisé!

Voici notre plan d'action:
- Nous reconstruirons le modèle de classification d'intention que nous avons construit dans la première partie, mais nous exploiterons les données de pré-formation à l'aide d'un encodeur BERT.
- Nous allons le tester à nouveau avec les questions que nous avons extraites de Google Search Console.
- Nous allons télécharger nos requêtes et nos données de prédiction d'intention vers BigQuery.
- Nous allons connecter BigQuery à Google Data Studio afin de regrouper les questions par intention et d’extraire des informations exploitables que nous pourrons utiliser pour hiérarchiser les efforts de développement de contenu.
- Nous passerons en revue les nouveaux concepts sous-jacents qui aident BERT à obtenir des performances bien meilleures que celles de notre modèle précédent.
Configuration de Google Colaboratory
Comme dans la première partie, nous allons courir Ludwig de l'intérieur Google Colaboratory afin d'utiliser leur runtime GPU gratuit.
Commencez par exécuter ce code pour vérifier la version de Tensorflow installée.
importer tensorflow en tant que tf; print (tf .__ version__)
Assurez-vous que notre ordinateur utilise la bonne version attendue par Ludwig et qu’il prend également en charge le runtime GPU.
Je reçois la 1.14.0, ce qui est bien comme Ludwig a besoin au moins 1.14.0
Sous l'élément de menu Runtime, sélectionnez Python 3 et GPU.
Vous pouvez confirmer que vous avez un GPU en tapant:
! Nvidia-smi
Au moment d'écrire ces lignes, vous devez installer certaines bibliothèques système avant d'installer la dernière version de Ludwig (0.2). J'ai eu des erreurs qu'ils ont ensuite résolu.
! apt-get install libgmp-dev libmpfr-dev libmpc-dev
Lorsque l'installation a échoué pour moi, j'ai trouvé la solution à partir de ce StackOverflow réponse, ce qui n’a même pas été accepté!
! pip installe ludwig
Tu devrais obtenir:
Gmpy-1.17 ludwig-0.2 installé avec succès
Préparer le jeu de données pour la formation
Nous allons utiliser le même ensemble de données de classification des questions que nous avons utilisé dans le premier article.
Une fois que vous vous êtes connecté à Kaggle et que vous avez téléchargé le jeu de données, vous pouvez utiliser le code pour le charger dans un dataframe dans Colab.
Configuration de l'encodeur BERT
Au lieu d'utiliser le codeur CNN parallèle que nous avons utilisé dans la première partie, nous allons utiliser le codeur BERT récemment ajouté à Ludwig.
Cet encodeur exploite des données pré-entraînées, ce qui lui permet d’être plus performant que notre précédent encodeur tout en nécessitant beaucoup moins de données d’entraînement. Je vais expliquer comment cela fonctionne en termes simples à la fin de cet article.
Commençons par télécharger un modèle de langage pré-entraîné. Nous allons télécharger les fichiers pour le modèle BERT-Base, Uncased.
J'ai d'abord essayé les plus gros modèles, mais quelques obstacles ont été rencontrés en raison de leurs besoins en mémoire et des limitations de Google Colab.
! wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip
Décompressez le avec:
! unzip uncased_L-12_H-768_A-12.zip
Le résultat devrait ressembler à ceci:
Archive: uncased_L-12_H-768_A-12.zip création: uncased_L-12_H-768_A-12 / gonflement: uncased_L-12_H-768_A-12 / bert_model.ckpt.meta gonflage: uncased_L-12_H-768_A-12 / bert_model.ckpt.data-00000-of-00001 gonflement: uncased_L-12_H-768_A-12 / vocab.txt gonflement: uncased_L-12_H-768_A-12 / bert_model.ckpt.index gonflement: uncased_L-12_H-768_A-12 / bert_config.json
Nous pouvons maintenant constituer le fichier de définition du modèle.
Comparons-le à celui que nous avons créé dans la première partie.
J'ai fait un certain nombre de changements. Voyons-les.
J'ai essentiellement changé l'encodeur de parallel_cnn à Bert et ajouté des paramètres supplémentaires Champs obligatoires par bert: config_path, checkpoint_path, word_tokenizer, word_vocab_file, padding_symbol et unknown_symbol.
La plupart des valeurs proviennent du modèle de langage que nous avons téléchargé.
J'ai ajouté quelques paramètres supplémentaires que j'ai déterminés de manière empirique: batch_size, learning_rate et word_sequence_length_limit.
Les valeurs par défaut que Ludwig utilise pour ces paramètres ne fonctionnent pas pour le codeur BERT car elles sont bien différentes des données pré-entraînées. J'ai trouvé des valeurs de travail dans le Documentation BERT.
Le processus de formation est le même que nous avons fait précédemment. Cependant, nous devons installer flux de tenseur premier.
! pip installer bert-tensorflow
! expérience ludwig --data_csv Question_Classification_Dataset.csv --model_definition_file model_definition.yaml
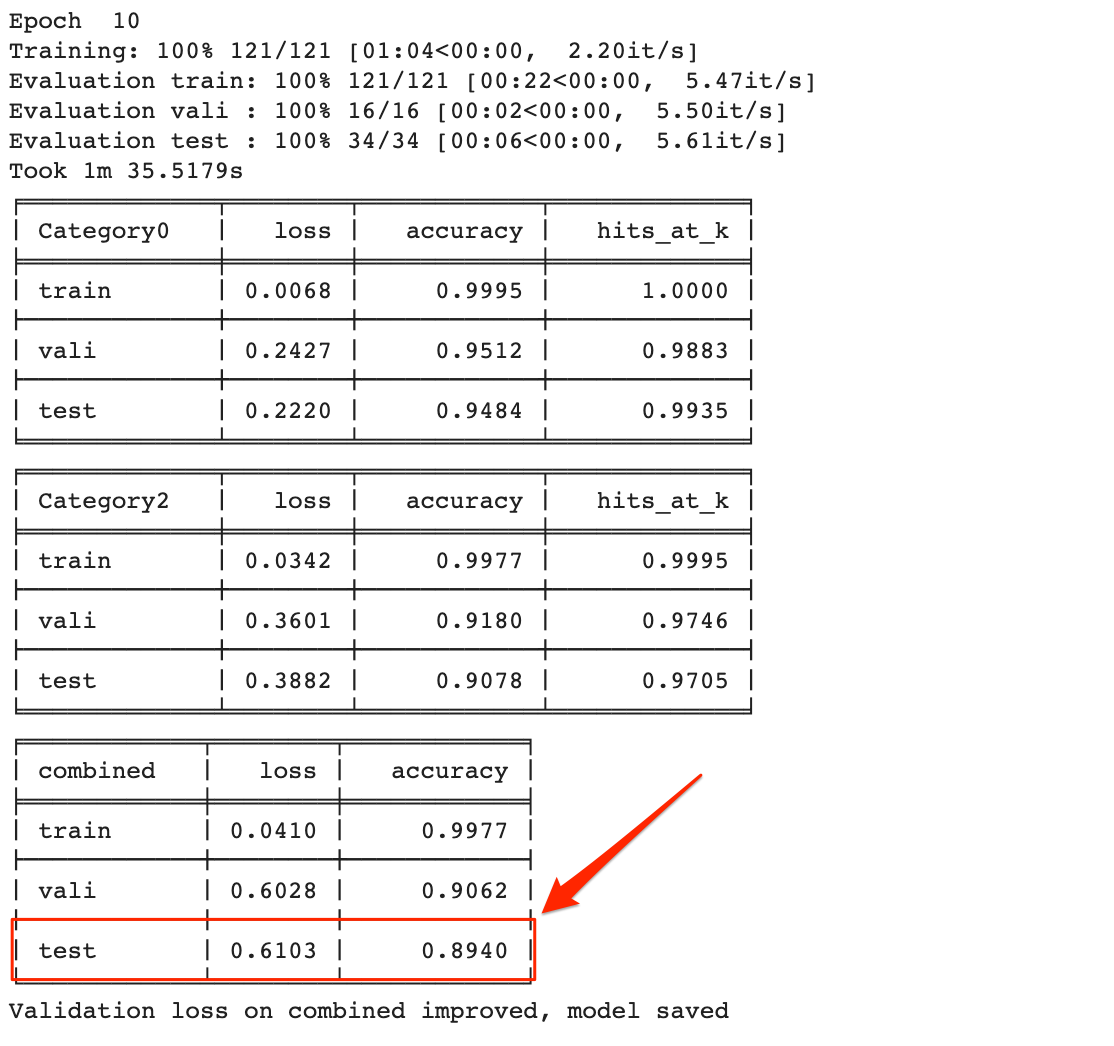
Nous avons battu la performance de notre modèle précédent après seulement deux époques.


L'amélioration finale était de 0,89 précision de test combiné après 10 périodes. Notre modèle précédent a pris 14 époques pour atteindre .66.
C’est assez remarquable étant donné que nous n’avons écrit aucun code. Nous avons seulement changé certains paramètres.
Il est incroyable et excitant de constater à quelle vitesse la recherche en apprentissage en profondeur s’améliore et est maintenant accessible.
Pourquoi BERT se comporte si bien
L'utilisation de BERT présente deux principaux avantages par rapport aux codeurs traditionnels:
- Le mot bidirectionnel embarque.
- Le modèle linguistique mis à profit par l’apprentissage par transfert.
Embeddings de mots bidirectionnels
Lorsque j'ai expliqué les vecteurs de mots et les imbrications dans la première partie, je faisais référence à l'approche traditionnelle (j'ai utilisé une analogie GPS des coordonnées dans un espace imaginaire).
Les approches traditionnelles d’incorporation de mots attribuent l’équivalent d’une coordonnée GPS à chaque mot.
Examinons les différentes significations du mot «Washington» pour expliquer pourquoi cela pourrait poser problème dans certains scénarios.
- George Washington (personne)
- Etat de Washington)
- Washington D.C. (Ville)
- Pont George Washington (pont)
Le mot «Washington» ci-dessus représente des choses complètement différentes et un système qui assigne les mêmes coordonnées quel que soit le contexte ne sera pas très précis.
Si nous sommes dans le bureau de Google à New York et que nous souhaitons visiter «Washington», nous devons fournir plus de contexte.
- Envisageons-nous de visiter le mémorial George Washington?
- Avons-nous prévu de conduire vers le sud pour visiter Washington, DC?
- Planifions-nous un voyage de cross-country dans l'État de Washington?
Comme vous pouvez le constater dans le texte, les mots qui l'entourent fournissent un contexte permettant de définir plus clairement ce que “Washington” pourrait signifier.
Si vous lisez de gauche à droite, le mot George peut indiquer que vous parlez de la personne, et si vous lisez de droite à gauche, le mot D.C. pourrait indiquer que vous faites référence à la ville.
Mais vous devez lire de gauche à droite et de droite à gauche pour vous dire que vous voulez réellement visiter le pont.
BERT fonctionne en encodant différents mots incorporés pour chaque utilisation de mot et s'appuie sur les mots environnants pour accomplir cela. Il lit les mots du contexte bidirectionnellement (de gauche à droite et de droite à gauche).
Pour en revenir à notre analogie GPS, imaginez un bloc de New York avec deux cafés Starbucks dans la même rue. Si vous voulez en savoir un, il serait beaucoup plus facile d’y faire référence par les entreprises qui sont avant et / ou après.
Apprentissage par transfert
L'apprentissage par transfert est probablement l'un des concepts les plus importants de l'apprentissage en profondeur aujourd'hui. Cela rend de nombreuses applications pratiques, même lorsque vous devez vous entraîner sur de très petits jeux de données.
Traditionnellement, l'apprentissage par transfert était principalement utilisé pour les tâches de vision par ordinateur.
Vous avez généralement des groupes de recherche de grandes entreprises (Google, Facebook, Stanford, etc.) qui forment un modèle de classification d'images sur un grand ensemble de données comme celui d'Imagenet.
Ce processus prendrait des jours et coûterait généralement très cher. Mais, une fois la formation terminée, la dernière partie du modèle formé est remplacée et reconvertie sur de nouvelles données pour effectuer des tâches similaires mais nouvelles.
Ce processus s'appelle réglage fin et fonctionne extrêmement bien. Le réglage peut prendre des heures ou des minutes en fonction de la taille des nouvelles données et est accessible à la plupart des entreprises.
Revenons à notre analogie GPS pour comprendre cela.
Supposons que vous souhaitiez vous rendre de l'État de Washington à New York et que quelqu'un que vous connaissez se rende dans le Michigan.
Au lieu de louer une voiture pour aller jusqu'au bout, vous pouvez partir en randonnée, vous rendre au Michigan, puis louer une voiture pour aller de Michigan à Washington, à un coût et en un temps de conduite beaucoup plus bas.
BERT est l’un des premiers modèles de réussite de l’apprentissage par transfert appliqué en PNL (traitement du langage naturel). Il existe plusieurs modèles pré-formés dont la formation prend généralement plusieurs jours, mais vous pouvez affiner le réglage en heures, voire en minutes, si vous utilisez des TPU Google Cloud.
Automatisation des informations sur les intentions avec BigQuery & Data Studio
Maintenant que nous avons un modèle formé, nous pouvons tester de nouvelles questions que nous pouvons récupérer à partir de la console de recherche Google à l'aide du rapport que j'ai créé sur. partie un.
Nous pouvons exécuter le même code que précédemment pour générer les prédictions.
Cette fois, je souhaite également les exporter vers un fichier CSV et les importer dans BigQuery.
test_df.join (prévisions)[["Query", "Clicks", "Impressions", "Category0_predictions", "Category2_predictions"]].to_csv ("intent_predictions.csv")
Commencez par vous connecter à Google Cloud.
! gcloud auth login --no-launch-browser
Ouvrez la fenêtre d'autorisation dans un onglet séparé et copiez le jeton dans Colab.
Créez un compartiment dans Google Cloud Storage et copiez-y le fichier CSV. J'ai nommé mon seau bert_intent_questions.
Cette commande chargera notre fichier CSV dans notre compartiment.
! gsutil cp -r intention_predictions.csv gs: // bert_intent_questions
Vous devez également créer un jeu de données dans BigQuery pour importer le fichier. J'ai nommé mon jeu de données bert_intent_questions
! bq load --autodetect --source_format = CSV bert_intent_questions.intent_predictions gs: //bert_intent_questions/intent_predictions.csv
Une fois nos prévisions établies dans BigQuery, nous pouvons le connecter à Data Studio et créer un rapport extrêmement précieux pour nous aider à visualiser les intentions les plus prometteuses.
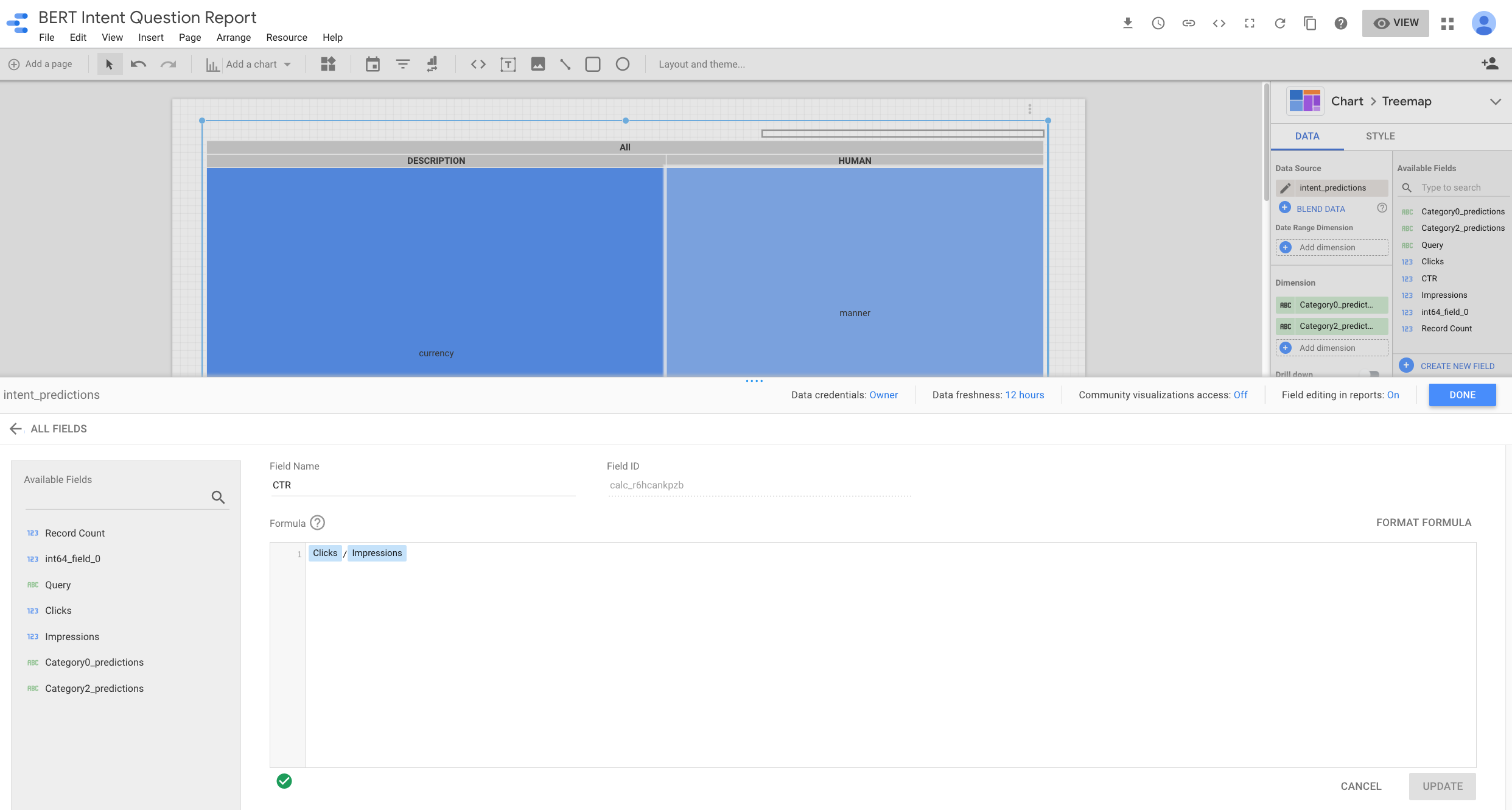

Après avoir connecté Data Studio à notre jeu de données BigQuery, j'ai créé un nouveau champ: CTR en divisant les impressions et les clics.
Comme nous regroupons les requêtes en fonction de leurs intentions prédites, nous pouvons rechercher des opportunités de contenu pour lesquelles nous avons des intentions avec des impressions de recherche élevées et un nombre de clics faible. Ce sont les carrés bleus plus clairs.


Comment fonctionne le processus d'apprentissage
Je souhaite aborder ce dernier sujet fondamental pour développer l’idée de codeur / décodeur que j’ai brièvement évoquée dans la première partie.
Jetons un coup d’œil aux tableaux ci-dessous qui nous aident à visualiser le processus de formation.
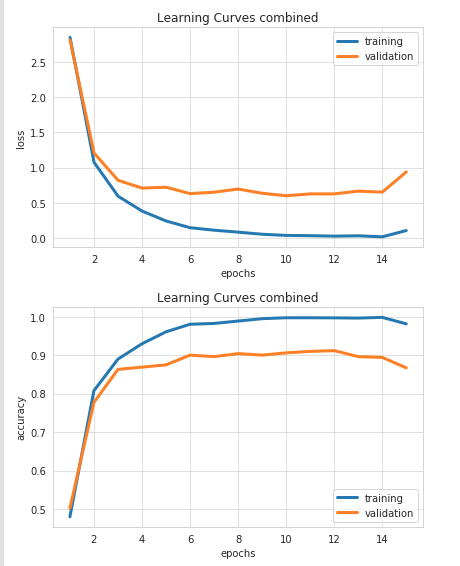

Mais que se passe-t-il exactement ici? Comment le modèle d'apprentissage automatique est-il capable d'exécuter les tâches sur lesquelles nous nous entraînons?
Le premier graphique montre comment l'erreur / la perte diminue chaque étape de l'entraînement (ligne bleue).
Mais, plus important encore, l'erreur diminue également lorsque le modèle est testé sur des données «invisibles». Vient ensuite un point où aucune amélioration supplémentaire n’a lieu.
J'aime penser que ce processus de formation supprime le bruit / les erreurs de l'entrée par essais et erreurs, jusqu'à ce qu'il ne vous reste plus que l'essentiel pour la tâche à accomplir.
Certaines recherches aléatoires sont impliquées pour savoir ce qu’il faut supprimer et ce qu’il faut conserver, mais comme le résultat / comportement idéal est connu, la recherche aléatoire peut être extrêmement sélective et efficace.
Disons à nouveau que vous voulez conduire de New York à Washington et que toutes les routes sont couvertes de neige. Le codeur, dans ce cas, jouerait le rôle d'un camion souffleuse à neige avec la tâche de tracer une route pour vous.
Il a les coordonnées GPS de la destination et peut l’utiliser pour indiquer sa distance ou sa fermeture, mais il doit déterminer comment s'y rendre par essais et erreurs intelligents. Le décodeur serait notre voiture suivant les routes créées par la souffleuse à neige pour ce voyage.
Si la souffleuse se déplace trop vers le sud, elle peut indiquer qu'elle va dans la mauvaise direction car elle s'éloigne de la destination GPS finale.
Note sur le surajustement
Une fois la souffleuse terminée, il est tentant de mémoriser tous les virages nécessaires pour y arriver, mais cela rendrait notre voyage inflexible dans le cas où nous devions faire des détours et ne pas avoir de routes tracées pour cela.
Donc, mémoriser n'est pas bon et s'appelle surapprentissage en termes d'apprentissage en profondeur. Idéalement, la souffleuse à neige définirait plus d’un moyen d’atteindre notre destination.
En d'autres termes, nous avons besoin d'itinéraires aussi généralisés que possible.
Nous accomplissons cela en conservant des données pendant le processus de formation.
Nous utilisons des ensembles de données de test et de validation pour que nos modèles soient aussi génériques que possible.
Note sur Tensorflow pour BigQuery
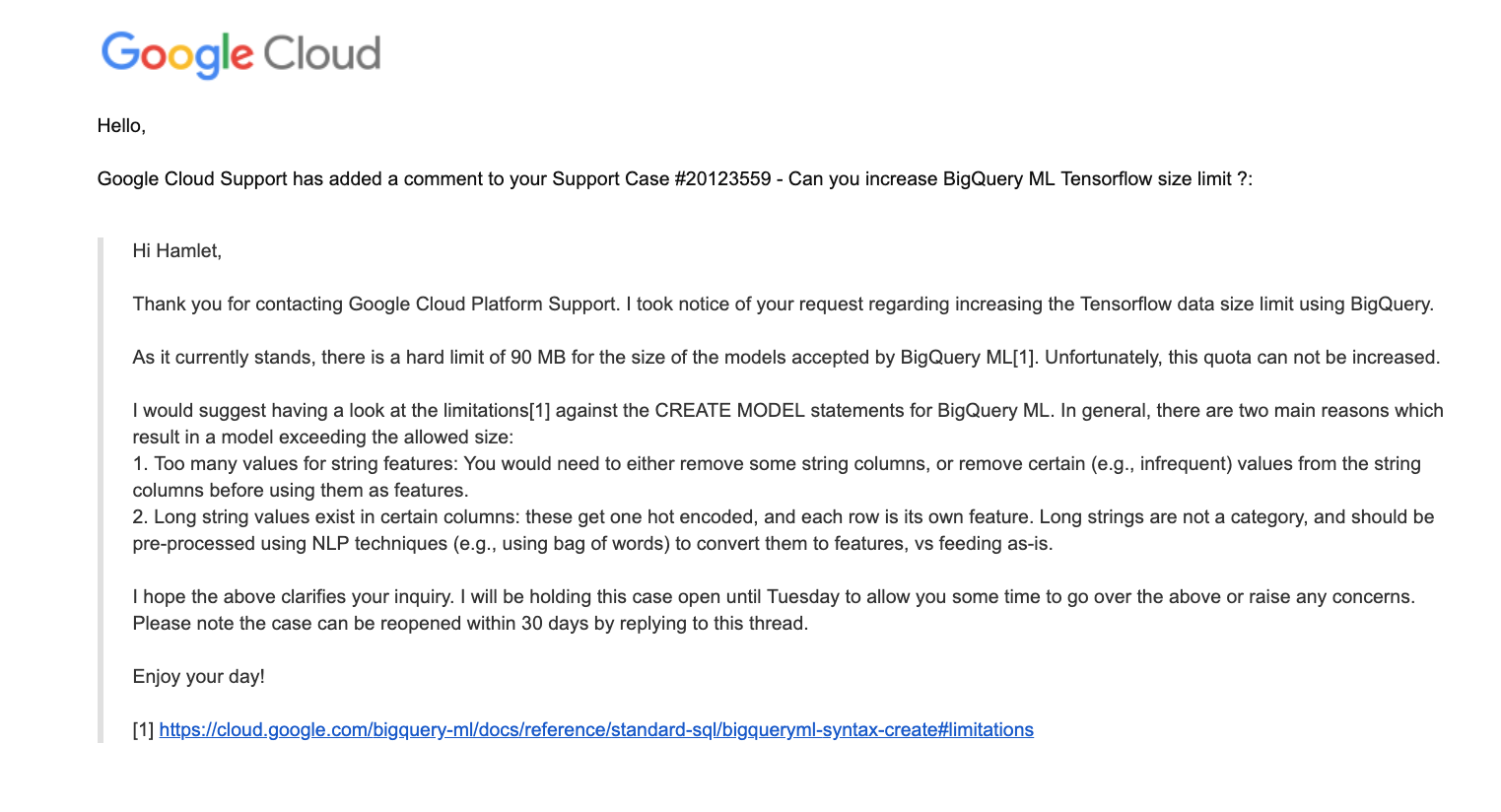
J'ai essayé d'exécuter nos prévisions directement à partir de BigQuery, mais je me suis heurté à un obstacle lorsque j'ai essayé d'importer notre modèle entraîné.
! bq requête --use_legacy_sql = false "CRÉER UN MODÈLE bert_intent_questions.BERT OPTIONS (MODEL_TYPE = 'TENSORFLOW', MODEL_PATH = 'gs: // bert_intent_questions / *') "
BigQuery s'est plaint de la taille du modèle dépassait leur limite.
En attente de la requête bqjob_r594b9ea2b1b7fe62_0000016c34e8b072_1 ... (0s) La taille totale est au moins: 1319235047; La taille maximale autorisée est: 268435456
J'ai sollicité leur soutien et ils ont proposé des suggestions. Je les partage ici au cas où quelqu'un trouverait le temps de les tester.

Ressources pour en savoir plus
Lorsque j'ai commencé à suivre des cours en profondeur, je n'ai vu ni BERT ni aucune des dernières architectures de réseau de neurones à la pointe de la technologie.
Cependant, la fondation que j'ai reçue m'a permis de trouver rapidement de nouveaux concepts et de nouvelles idées. L'un des articles que j'ai trouvé les plus utiles pour apprendre les nouvelles avancées était celui-ci: Les illustrés BERT, ELMo et co. (Comment NLP Cracked Transfer Learning).
J'ai aussi trouvé celui-ci très utile: Paper Dissected: BERT: pré-formation de transformateurs bidirectionnels profonds pour la compréhension du langage », a expliqué et cet autre de la même publication: Papier disséqué: «XLNet: formation préalable autorégressive généralisée pour la compréhension du langage», explique.
BERT a récemment été battu par un nouveau modèle appelé XLNet. J'espère pouvoir le couvrir dans un futur article quand il sera disponible dans Ludwig.
L'élan Python dans la communauté SEO continue de croître. Voici quelques exemples:
Paul Shapiro a amené Python sur la scène MozCon plus tôt ce mois-ci. Il partagé les scripts il a discuté lors de son entretien.
J'ai été agréablement surpris quand j'ai partagé un extrait de code sur Twitter et Tyler Reardon, un collègue SEO, a rapidement repéré un bug que j'ai raté parce qu'il a créé un code similaire indépendamment.
Grand bravo à @TylerReardon qui a repéré un bug dans mon code assez rapidement! Il est déjà fixé https://t.co/gvypIOVuBp
Je pensais comparer l'adresse IP du journal et celle du DNS, mais je comparais deux fois l'adresse IP du journal! 😅
Nous avons un super #python #SEO communauté
– Hameau 🇩🇴 (@hamletbatista) 25 juillet 2019
Michael Weber a partagé son génial prédicteur de classement qui utilise un classificateur de perceptron multicouche et Antoine Eripret partagé un super précieux moniteur de changement robot.txt!
Je devrais également mentionner que JR a fourni une pièce très utile en Python pour opensource.com qui montre Cas d'utilisation pratique de l'API Google Natural Language.
Plus de ressources:
Crédits d'image
Toutes les captures d'écran réalisées par l'auteur, juillet 2019


