

Le classement dans les moteurs de recherche nécessite un site Web avec un référencement technique sans faille et un contenu pertinent et de qualité. Heureusement, le plugin Yoast SEO s’occupe de (presque) tout sur votre site WordPress. Néanmoins, si vous voulez vraiment tirer le meilleur parti de votre site Web et continuer à surclasser la concurrence, des connaissances de base en référencement technique sont indispensables. Dans cet article, nous expliquerons l’un des concepts les plus importants du référencement technique : la crawlabilité.
C’est quoi le crawler encore ?
Un moteur de recherche comme Google se compose d’un robot d’exploration, d’un index et d’un algorithme. Le robot d’exploration suit les liens. Lorsque le robot d’exploration de Google, également connu sous le nom de Googlebot, trouve votre site Web, il le rend, le lit et enregistre le contenu dans l’index.
Un robot d’exploration suit les liens sur le Web. Un robot est également appelé robot, bot ou araignée. Il fait le tour d’Internet 24h/24 et 7j/7. Une fois arrivé sur un site Web, il enregistre la version HTML dans une gigantesque base de données appelée l’index. Cet index est mis à jour chaque fois que le robot d’exploration visite votre site Web et en trouve une version nouvelle ou révisée. Selon l’importance que Google accorde à votre site et le nombre de modifications que vous y apportez, le robot d’exploration revient plus ou moins souvent.
Lire la suite : Les bases du référencement : que fait Google »
Et qu’est-ce que la crawlabilité ?
L’exploration a à voir avec les possibilités qu’a Google d’explorer votre site Web. Vous pouvez bloquer les robots d’exploration sur votre site. Il existe plusieurs façons de bloquer un robot d’exploration de votre site Web. Si votre site Web ou une page de votre site Web est bloqué, vous dites au robot d’exploration de Google : « Ne venez pas ici ». Votre site ou la page correspondante n’apparaîtra pas dans les résultats de recherche dans la plupart de ces cas.
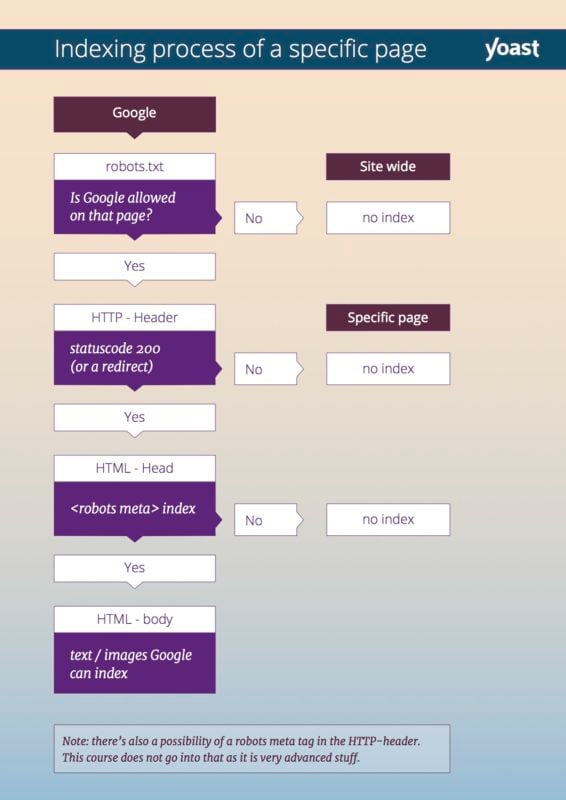
Certains éléments peuvent empêcher Google d’explorer (ou d’indexer) votre site Web :
- Si votre fichier robots.txt bloque le robot d’exploration, Google n’accédera pas à votre site Web ou à votre page Web spécifique.
- Avant d’explorer votre site Web, le robot d’exploration examinera l’en-tête HTTP de votre page. Cet en-tête HTTP contient un code d’état. Si ce code d’état indique qu’une page n’existe pas, Google n’explorera pas votre site Web. Dans le module sur les en-têtes HTTP de notre formation SEO technique, nous vous dirons tout à ce sujet.
- Si la balise meta robots sur une page spécifique empêche le moteur de recherche d’indexer cette page, Google explorera cette page, mais ne l’ajoutera pas à son index.
Cet organigramme peut vous aider à comprendre le processus suivi par les robots lorsqu’ils tentent d’indexer une page :
Vous voulez tout savoir sur la crawlabilité ?
Bien que la crawlabilité ne soit que la base du référencement technique (elle concerne tout ce qui permet à Google d’indexer votre site), c’est déjà assez avancé pour la plupart des gens. Néanmoins, si vous bloquez – peut-être même sans le savoir ! – les robots de votre site, vous ne serez jamais bien classé dans Google. Donc, si vous êtes sérieux au sujet du référencement, cela devrait vous intéresser.
Si vous voulez vraiment comprendre tous les aspects techniques de la crawlabilité, vous devriez consulter notre formation SEO technique. Ce cours de référencement vous apprendra à détecter les problèmes techniques de référencement et à les résoudre (avec notre plugin Yoast SEO). Yoast SEO Academy est inclus sans frais supplémentaires dans votre abonnement Premium
Continuez à lire : Qu’est-ce que le référencement technique : 8 aspects que tout le monde devrait connaître »


