
Dans de nombreux cas, ce qu’un crawler SEO marque comme une erreur fatale nécessite une attention immédiate – mais parfois, ce n’est pas du tout une erreur.
Cela peut se produire même avec les outils d’exploration de référencement les plus populaires tels que Semrush Site Audit, Ahrefs Site Audit, Sitebulb et Screaming Frog.
Comment faire la différence pour éviter de donner la priorité à un correctif qui n’a pas besoin d’être fait ?
Voici quelques exemples concrets de tels avertissements et erreurs, avec des explications sur les raisons pour lesquelles ils peuvent être un problème pour votre site Web.
1. Problèmes d’indexation (Pages Noindex sur le Site)
Tout robot d’indexation SEO mettra en évidence et vous avertira des pages non indexables sur le site. Selon le type de robot, les pages noindex peuvent être marquées comme des avertissements, des erreurs ou des informations.
Voici comment ce problème est marqué dans Ahrefs Site Audit :
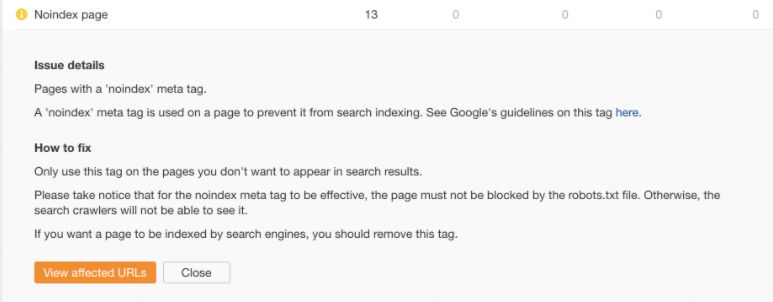 Capture d’écran de l’audit du site Ahrefs, septembre 2021
Capture d’écran de l’audit du site Ahrefs, septembre 2021Le rapport de couverture de la console de recherche Google peut également marquer les pages non indexables comme des erreurs (si le site contient des pages non indexables dans le plan du site soumis) ou comme exclues, même s’il ne s’agit pas de problèmes réels.
Publicité
Continuer la lecture ci-dessous
Il ne s’agit, encore une fois, que de l’information indiquant que ces URL ne peuvent pas être indexées.
Voici à quoi cela ressemble dans GSC :
 Capture d’écran de la console de recherche Google, septembre 2021
Capture d’écran de la console de recherche Google, septembre 2021Le fait qu’une URL comporte une balise « noindex » ne signifie pas nécessairement qu’il s’agit d’une erreur. Cela signifie seulement que la page ne peut pas être indexée par Google et d’autres moteurs de recherche.
La balise « noindex » est l’une des deux directives possibles pour les robots, l’autre étant d’indexer la page.
Publicité
Continuer la lecture ci-dessous
Pratiquement tous les sites Web contiennent des URL qui ne devraient pas être indexées par Google.
Celles-ci peuvent inclure, par exemple, des pages de balises (et parfois des pages de catégories), des pages de connexion, des pages de réinitialisation de mot de passe ou une page de remerciement.
Votre tâche, en tant que professionnel du référencement, consiste à examiner les pages noindex sur le site et à décider si elles doivent effectivement être bloquées de l’indexation ou si la balise « noindex » a pu être ajoutée par accident.
2. Méta description trop courte ou vide
Les robots d’indexation vérifieront également les méta-éléments du site, y compris les méta-descriptions. Si le site n’a pas de méta descriptions ou si elles sont trop courtes (généralement moins de 110 caractères), le robot d’exploration le marquera comme un problème.
Voici à quoi cela ressemble dans Ahrefs :
 Capture d’écran de l’audit du site Ahrefs, septembre 2021
Capture d’écran de l’audit du site Ahrefs, septembre 2021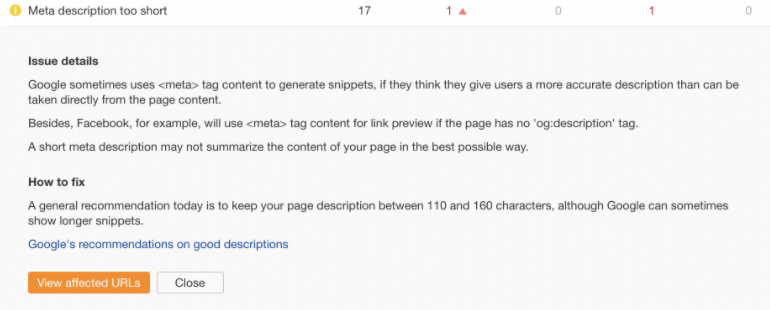
Voici comment Screaming Frog l’affiche :
 Capture d’écran de Screaming Frog, septembre 2021
Capture d’écran de Screaming Frog, septembre 2021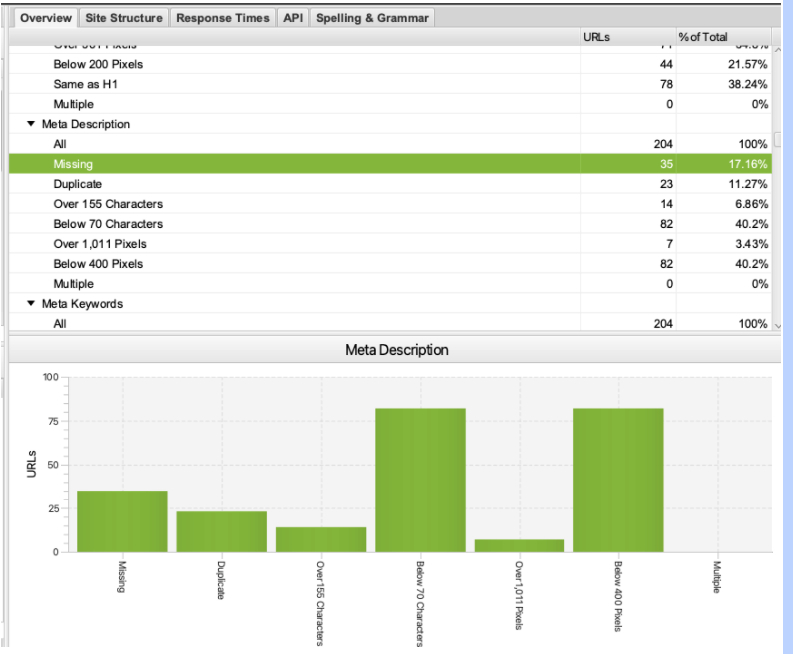
Selon la taille du site, il n’est pas toujours possible et/ou faisable de créer des méta descriptions uniques pour toutes ses pages Web. Vous n’en aurez peut-être pas besoin non plus.
Un bon exemple de site où cela n’a peut-être pas de sens est un énorme site de commerce électronique avec des millions d’URL.
En fait, plus le site est grand, moins cet élément est important.
Le contenu de l’élément meta description, contrairement au contenu de la balise title, n’est pas pris en compte par Google et n’influence pas les classements.
Les extraits de recherche utilisent parfois la méta description mais sont souvent réécrits par Google.
Voici ce que Google a à dire à ce sujet dans leur référencement avancé Documentation:
« Les extraits sont automatiquement créés à partir du contenu de la page. Les extraits sont conçus pour mettre en valeur et prévisualiser le contenu de la page qui correspond le mieux à la recherche spécifique d’un utilisateur : cela signifie qu’une page peut afficher différents extraits pour différentes recherches. »
En tant que référenceur, vous devez garder à l’esprit que chaque site est différent. Utilisez votre bon sens SEO pour décider si les méta-descriptions sont effectivement un problème pour ce site Web spécifique, ou si vous pouvez ignorer l’avertissement en toute sécurité.
Publicité
Continuer la lecture ci-dessous
3. Méta mots-clés manquants
Les méta-mots-clés ont été utilisés il y a plus de 20 ans pour indiquer aux moteurs de recherche tels qu’Altavista les phrases-clés pour lesquelles une URL donnée voulait être classée.
Cela a cependant été fortement abusé. Les méta-mots-clés étaient une sorte d' »aimant de spam », donc la majorité des moteurs de recherche ont abandonné la prise en charge de cet élément.
Screaming Frog vérifie toujours s’il y a des méta-mots-clés sur le site, par défaut.
Comme il s’agit d’un élément de référencement obsolète, 99% des sites n’utilisent plus de méta-mots-clés.
Voici à quoi cela ressemble dans Screaming Frog :
 Capture d’écran de Screaming Frog, septembre 2021
Capture d’écran de Screaming Frog, septembre 2021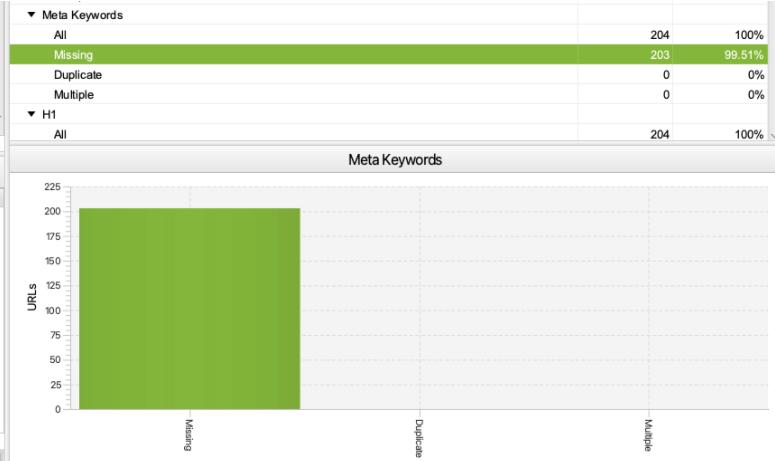
Les nouveaux professionnels du référencement ou les nouveaux clients peuvent être confus en pensant que si un robot d’exploration marque quelque chose comme manquant, cet élément doit en fait être ajouté au site. Mais ce n’est pas le cas ici !
Publicité
Continuer la lecture ci-dessous
S’il manque des méta-mots clés sur le site que vous auditez, recommander de les ajouter est un gaspillage.
4. Images de plus de 100 Ko
Il est important d’optimiser et de compresser les images utilisées sur le site afin qu’un gigantesque logo PNG pesant 10 Mo n’ait pas besoin d’être chargé sur chaque page Web.
Cependant, il n’est pas toujours possible de compresser toutes les images à moins de 100 Ko.
Screaming Frog mettra toujours en évidence et vous avertira des images de plus de 100 Ko. Voici à quoi cela ressemble dans l’outil :
 Capture d’écran de Screaming Frog, septembre 2021
Capture d’écran de Screaming Frog, septembre 2021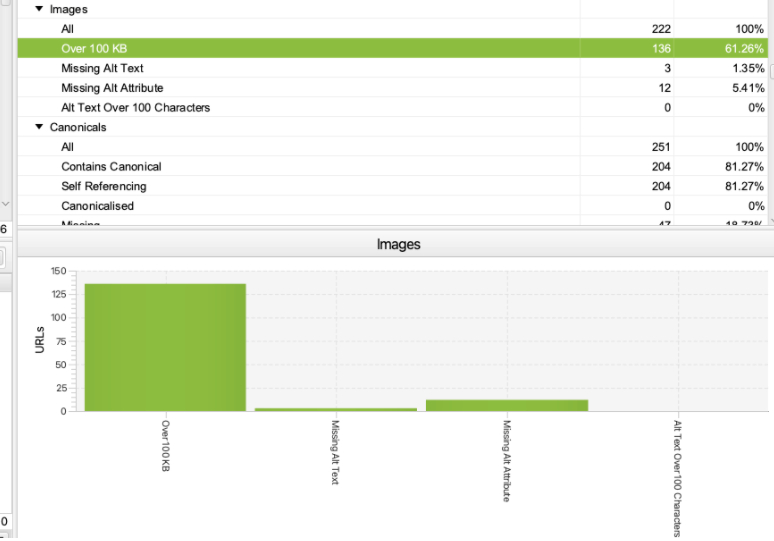
Le fait que le site ait des images de plus de 100 Ko ne signifie pas nécessairement que le site a des problèmes d’optimisation d’image ou est très lent.
Publicité
Continuer la lecture ci-dessous
Lorsque vous voyez cette erreur, assurez-vous de vérifier la vitesse et les performances globales du site dans Google PageSpeed Insights et le rapport Google Search Console Core Web Vitals.
Si le site se porte bien et réussit l’évaluation Core Web Vitals, il n’est généralement pas nécessaire de compresser davantage les images.
Conseil: Ce que vous pouvez faire avec ce rapport Screaming Frog est de trier les images par taille du plus lourd au plus léger pour vérifier s’il y a des images vraiment énormes sur des pages Web spécifiques.
5. Pages à faible contenu ou à faible nombre de mots
Selon les paramètres du robot d’indexation SEO, la plupart des outils d’audit SEO mettront en évidence les pages de moins de 50 à 100 mots en tant que pages à faible contenu.
Voici à quoi ressemble ce problème dans Ahrefs :
 Capture d’écran de l’audit du site Ahrefs, septembre 2021
Capture d’écran de l’audit du site Ahrefs, septembre 2021
Screaming Frog, en revanche, considère les pages de moins de 200 mots comme des pages à faible contenu par défaut (vous pouvez modifier ce paramètre lors de la configuration du crawl).
Publicité
Continuer la lecture ci-dessous
Voici comment Screaming Frog rapporte cela :
 Capture d’écran de Screaming Frog, septembre 2021
Capture d’écran de Screaming Frog, septembre 2021
Ce n’est pas parce qu’une page Web contient peu de mots qu’il s’agit d’un problème ou d’une erreur.
Il existe de nombreux types de pages censées avoir un faible nombre de mots, notamment certaines pages de connexion, des pages de réinitialisation de mot de passe, des pages de balises ou une page de contact.
Le robot d’exploration marquera ces pages comme étant à faible contenu, mais ce n’est pas un problème qui empêchera le site de bien se classer dans Google.
Publicité
Continuer la lecture ci-dessous
Ce que l’outil essaie de vous dire, c’est que si vous voulez qu’une page Web donnée soit bien classée dans Google et génère beaucoup de trafic organique, cette page Web devra peut-être être assez détaillée et approfondie.
Cela inclut souvent, entre autres, un nombre élevé de mots. Mais il existe différents types d’intentions de recherche et la profondeur du contenu n’est pas toujours ce que les utilisateurs recherchent pour satisfaire leurs besoins.
Lorsque vous examinez des pages à faible nombre de mots signalées par le robot d’exploration, demandez-vous toujours si ces pages sont vraiment censées contenir beaucoup de contenu. Dans de nombreux cas, ils ne le sont pas.
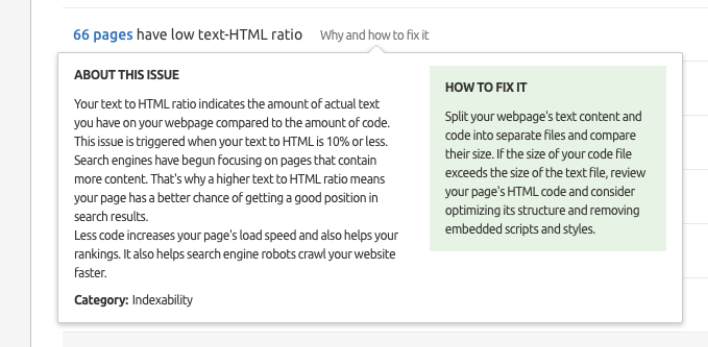
6. Faible rapport HTML-texte
Semrush Site Audit vous alertera également sur les pages qui ont un faible ratio texte-HTML.
Voici comment Semrush rapporte cela :
 Capture d’écran de Semrush Site Audit, septembre 2021
Capture d’écran de Semrush Site Audit, septembre 2021Cette alerte est censée vous montrer :
Publicité
Continuer la lecture ci-dessous
- Pages qui peuvent avoir un faible nombre de mots.
- Pages potentiellement construites de manière complexe et contenant un énorme fichier de code HTML.
Cet avertissement confond souvent les professionnels du référencement moins expérimentés ou nouveaux, et vous aurez peut-être besoin d’un professionnel du référencement technique expérimenté pour déterminer s’il y a lieu de s’inquiéter.
De nombreuses variables peuvent affecter le rapport HTML-texte et ce n’est pas toujours un problème si le site a un rapport HTML-texte faible/élevé. Il n’existe pas de rapport HTML-texte optimal.
En tant que professionnel du référencement, ce sur quoi vous pouvez vous concentrer est de vous assurer que la vitesse et les performances du site sont optimales.
7. Plan du site XML non indiqué dans robots.txt
Robots.txt, en plus d’être le fichier contenant les directives du robot d’exploration, est également l’endroit où vous pouvez spécifier l’URL du plan du site XML afin que Google puisse l’explorer et indexer le contenu facilement.
Les robots d’indexation tels que Semrush Site Audit vous avertiront si le plan du site XML n’est pas indiqué dans robots.txt.
Publicité
Continuer la lecture ci-dessous
Voici comment Semrush rapporte cela :
 Capture d’écran de Semrush Site Audit, septembre 2021
Capture d’écran de Semrush Site Audit, septembre 2021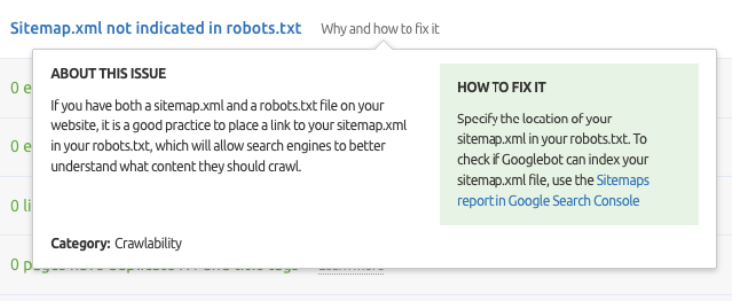
À première vue, cela ressemble à un problème sérieux même si dans la plupart des cas, ce n’est pas parce que :
- Google n’a généralement pas de problèmes pour explorer et indexer des sites plus petits (moins de 10 000 pages).
- Google n’aura pas de problèmes à explorer et à indexer d’énormes sites s’ils ont une bonne structure de liens internes.
- Un sitemap XML n’a pas besoin d’être indiqué dans robots.txt s’il est correctement soumis dans Google Search Console.
- Un plan de site XML n’a pas besoin d’être indiqué dans robots.txt s’il se trouve à l’emplacement standard, c’est-à-dire /sitemap.xml (dans la plupart des cas).
Avant de marquer cela comme un problème prioritaire dans votre audit SEO, assurez-vous qu’aucun de ces points n’est vrai pour le site que vous auditez.
Bonus : l’outil signale une erreur critique liée à quelques URL sans importance
Même si l’outil affiche un problème réel, comme une page 404 sur le site, il se peut que ce ne soit pas un problème sérieux si l’une des millions de pages Web du site renvoie le statut 404 ou s’il n’y a pas de liens pointant vers cette page 404 .
Publicité
Continuer la lecture ci-dessous
C’est pourquoi, lors de l’évaluation des problèmes détectés par le robot d’exploration, vous devez toujours vérifier à combien de pages Web ils se rapportent et lesquelles.
Vous devez donner le contexte de l’erreur.
Sitebulb, par exemple, vous montrera le pourcentage d’URL auquel une erreur donnée se rapporte.
Voici un exemple d’URL interne redirigeant vers une URL cassée renvoyant 4XX ou 5XX signalée par Sitebulb :
 Capture d’écran de Sitebulb Website Crawler, septembre 2021
Capture d’écran de Sitebulb Website Crawler, septembre 2021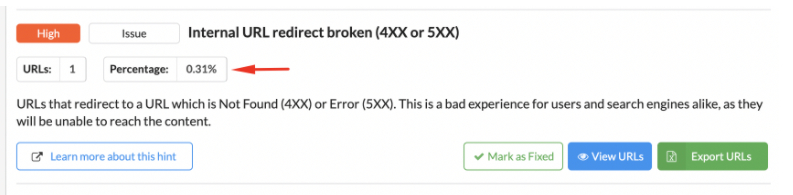
Cela ressemble à un problème assez grave, mais il ne concerne qu’une seule page Web sans importance, ce n’est donc certainement pas un problème prioritaire.
Publicité
Continuer la lecture ci-dessous
Réflexions finales et conseils
Les crawlers SEO sont des outils indispensables pour les professionnels techniques du référencement. Cependant, ce qu’ils révèlent doit toujours être interprété dans le contexte du site Web et de vos objectifs pour l’entreprise.
Il faut du temps et de l’expérience pour pouvoir faire la différence entre un pseudo-problème et un vrai. Heureusement, la plupart des robots offrent des explications détaillées sur les erreurs et les avertissements qu’ils affichent.
C’est pourquoi c’est toujours une bonne idée – en particulier pour les professionnels du référencement débutants – de lire ces explications et la documentation du crawler. Assurez-vous de bien comprendre ce que signifie un problème donné et s’il vaut vraiment la peine de passer à un correctif.
Davantage de ressources:
Image en vedette : Pro Symbols/Shutterstock


