
Il y a beaucoup d'histoires émotionnelles et puissantes cachées dans une foule de données qui ne demandent qu'à être trouvées.
Lorsque ces histoires sont racontées, elles ont le pouvoir de changer de carrière, d’entreprise et de tout un groupe de personnes.
Prenez Whirlpool, par exemple. Ils ont découvert un problème socio-économique qu'ils pourraient exploiter avec leur marque.
Ils ont exploité des données pour trouver une cause sociale à laquelle s'aligner et ont découvert que chaque jour, 4 000 élèves abandonnaient l'école parce qu'ils ne pouvaient pas se permettre de garder leurs vêtements propres.
Whirlpool a fait don de laveuses et de sécheuses aux écoles accueillant les enfants les plus à risque et a effectué un suivi de la fréquentation.
La marque a constaté que 90% de ces étudiants avaient amélioré leur taux de fréquentation et presque le même nombre d'enfants avaient amélioré leur participation en classe. La campagne a été si efficace qu'elle a remporté de nombreux prix, notamment le Grand Prix Cannes Lions de la collecte de données créatives et de la recherche.
Même si les grandes marques peuvent se permettre de recruter des agences de création primées capables de produire des campagnes comme celle-ci, il est hors de question pour la plupart des petites entreprises.
Une des façons d'entrer dans le feu des projecteurs est de trouver des histoires percutantes qui restent à découvrir en raison du fossé qui existe entre les spécialistes du marketing et les experts en données.
J'ai introduit un cadre simple pour le faire qui consiste à recadrer des visualisations déjà populaires. La possibilité de recadrer existe car les spécialistes du marketing et les développeurs opèrent en silos.


En tant que responsable marketing, lorsque vous transférez un projet de données à un développeur, la première chose à faire est de supprimer le contexte.
Le travail du développeur est de généraliser. Toutefois, lorsque vous récupérez leurs résultats, vous devez ajouter le contexte afin de pouvoir les personnaliser.
Sans le contexte de l'utilisateur, le développeur n'est pas en mesure de poser les bonnes questions pouvant conduire à l'établissement de liens émotionnels forts.
Dans cet article, je vais vous donner un exemple pour vous montrer comment créer de puissantes visualisations et des récits de données en combinant ceux qui sont populaires.
Voici notre plan d'action.
- Nous allons reconstruire une visualisation de données populaire à partir du subreddit Les données sont belles.
- Nous allons collecter des données à partir de pages Web publiques (y compris des graphiques mobiles).
- Nous recadrerons la visualisation en posant des questions différentes de celles de l'auteur original.
Notre visualisation recadrée


Voici à quoi ressemble notre visualisation recadrée. Il montre les meilleures attractions Disney classées selon leur degré de plaisir pour différents groupes d’âge.
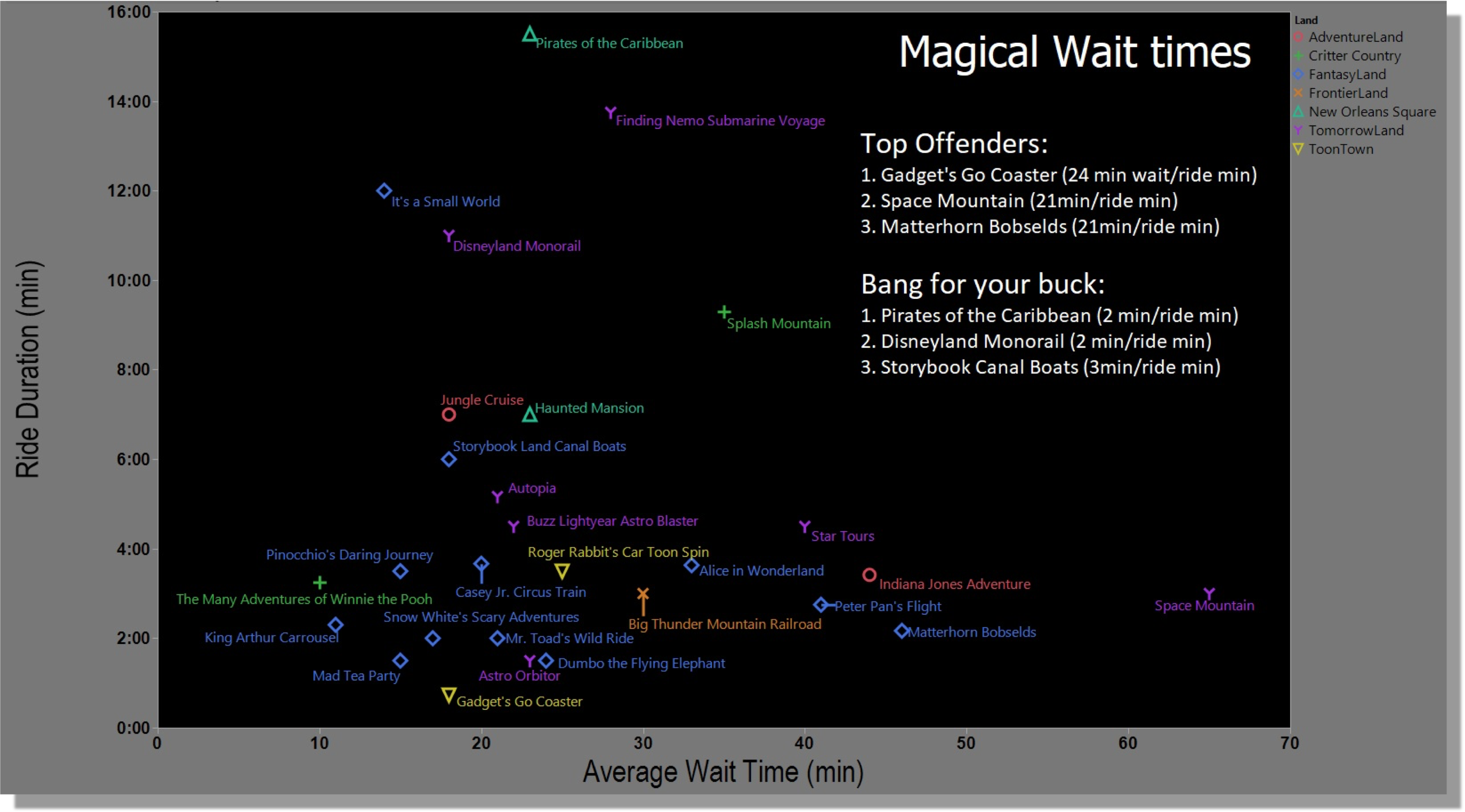

C'est l'original partagé sur Reddit. Il montre les meilleures balades Disney comparées à leur durée et à la durée des files d'attente.
Notre visualisation reconstruite
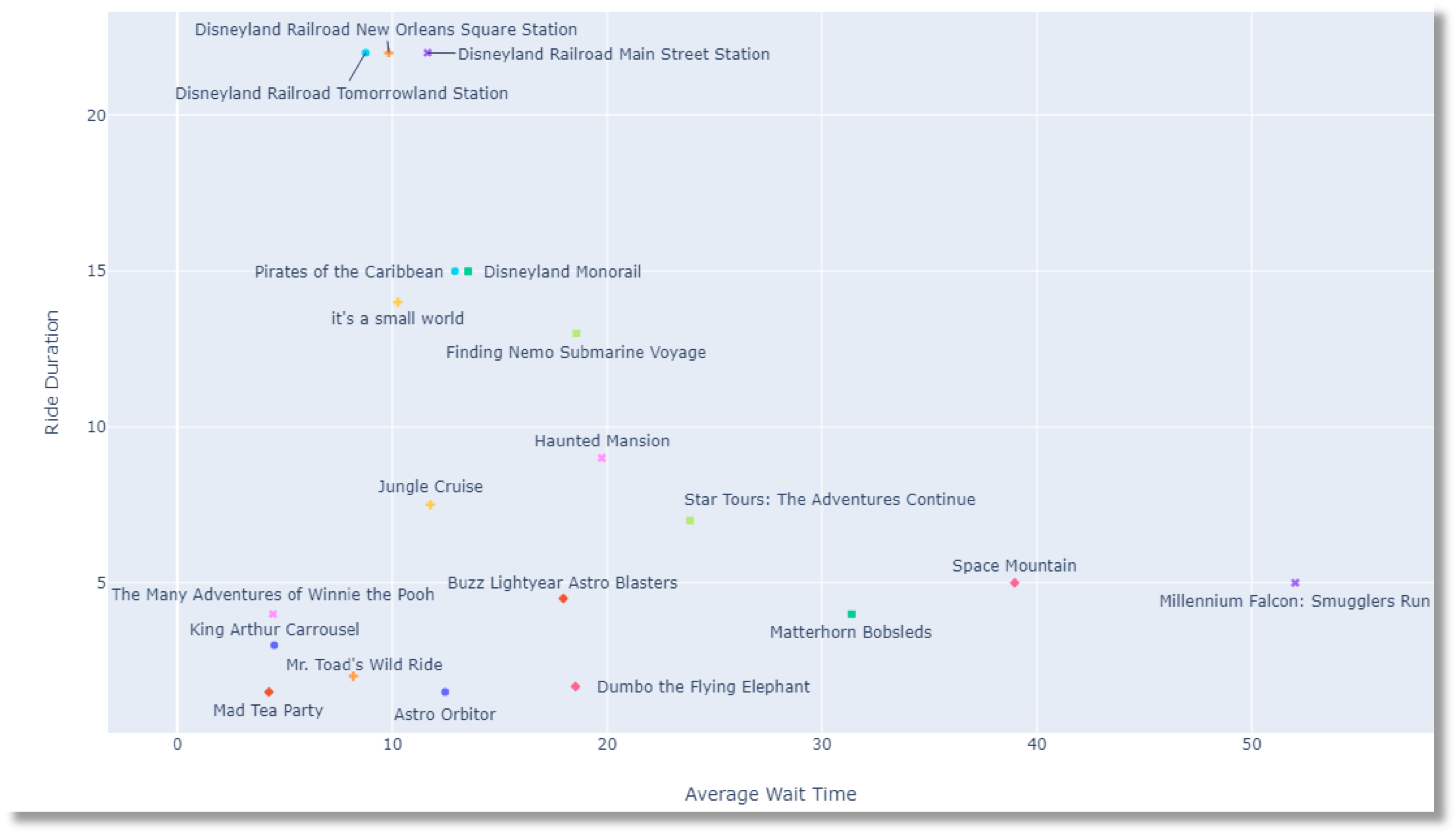

Notre première étape consiste à reconstruire la visualisation originale partagée dans le subreddit. Le scientifique des données a partagé les sources de données qu'il a utilisées, mais pas le code.
Cela nous donne une excellente occasion d'apprendre à extraire des données et de les visualiser en Python.
Je vais partager des extraits de code comme d’habitude, mais vous pouvez trouver tout le code dans cette Cahier de notes Google Colab.
Extraire nos données sources
La visualisation d'origine contient deux jeux de données, l'un avec la durée des trajets et l'autre avec leur temps d'attente moyen.
Commençons par collecter les durées de trajet de cette page https://touringplans.com/disneyland/attractions/duration.
Nous allons compléter ces étapes pour extraire les durées de trajet:
- Utilisez Google Chrome pour obtenir un sélecteur d’élément HTML DOM avec les durées de parcours.
- Utilisez request-html pour extraire les éléments de la page source.
- Utilisez une expression régulière simple pour les nombres de durée.
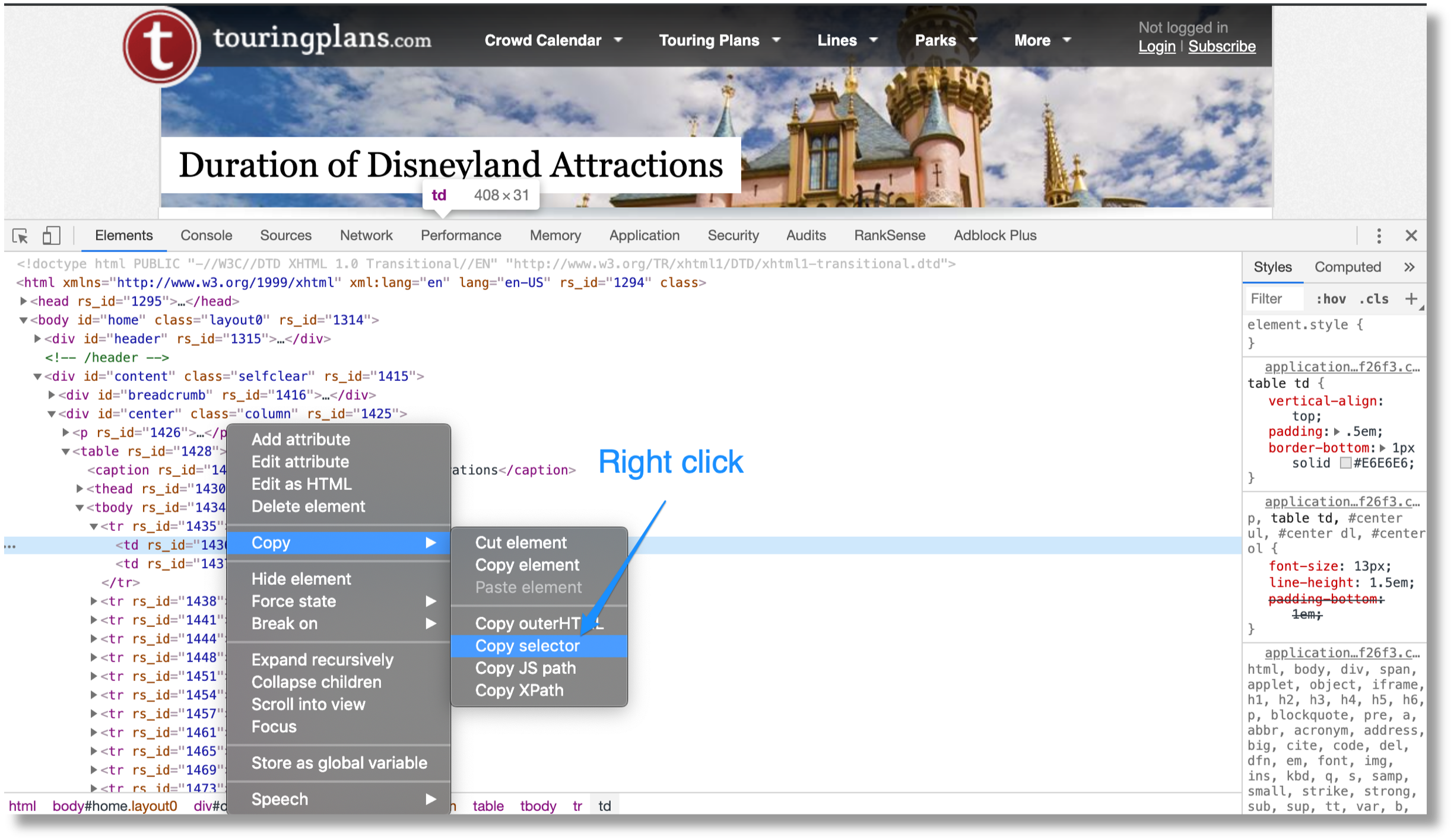

Ensuite, nous devons collecter les temps d’attente moyens à partir de cette page. https://touringplans.com/disneyland/wait-times.
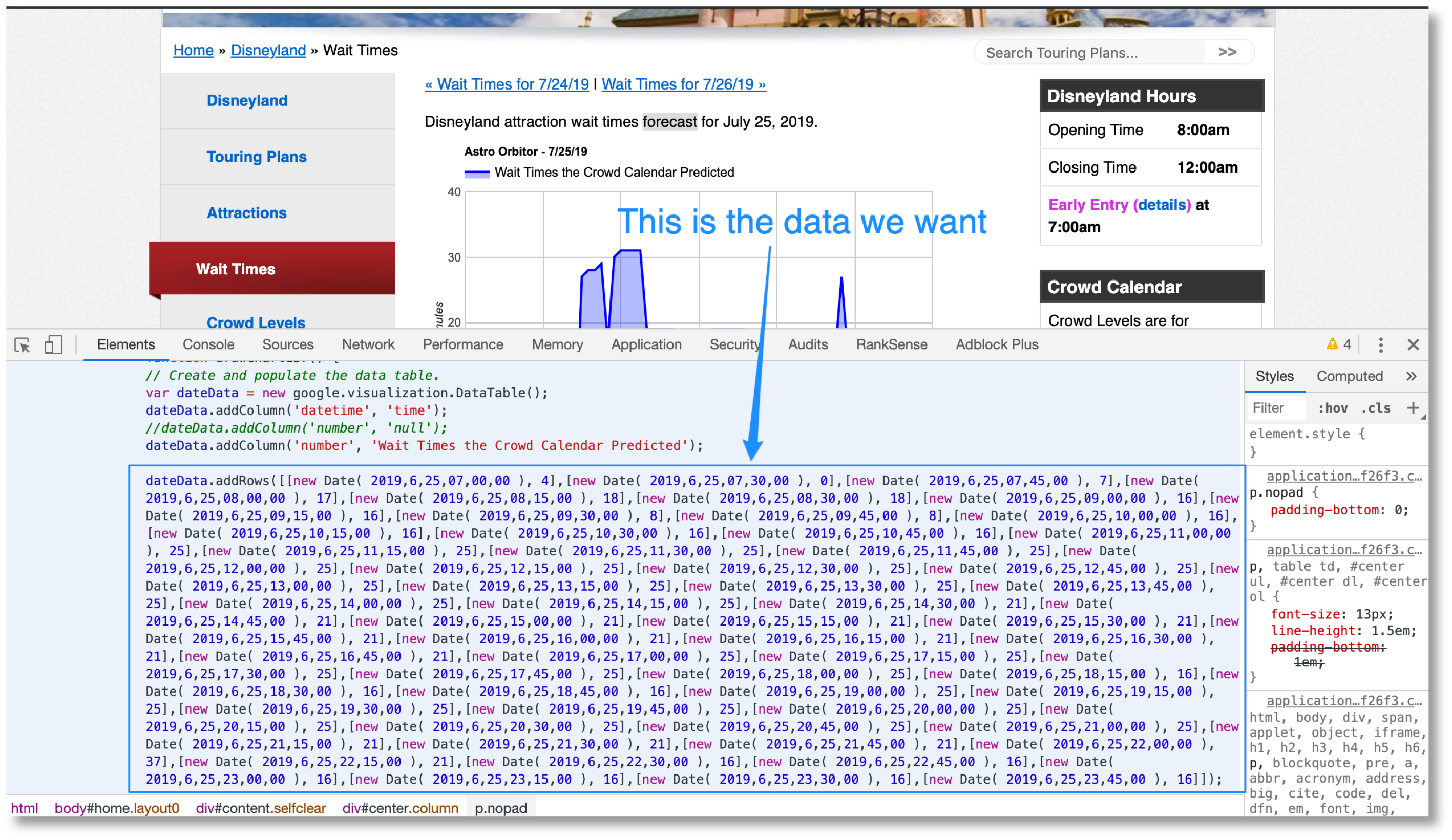

Il s’agit d’une extraction plus complexe car les données souhaitées se trouvent dans les graphiques en mouvement.
Nous allons terminer ces étapes pour extraire les temps d'attente moyens:
- Utilisez request-html pour extraire les extraits de code JavaScript de la page source.
- Utilisez des expressions régulières pour extraire les lignes de données du code JavaScript ainsi que le nom du parcours / titre du graphique.
- Utilisez un modèle Jinja2 pour associer une fonction JavaScript personnalisée qui renvoie les valeurs extraites à l'étape 2.
- Utilisez Py_mini_racer pour exécuter la fonction JavaScript personnalisée et obtenir les données au format Python.
Pour convertir les données JavaScript incorporées dans les graphiques en Python, nous allons effectuer une astuce intelligente.
Nous allons assembler des fonctions JavaScript en utilisant des fragments du code que nous sommes en train de gratter.
Nous allons utiliser des délimiteurs pour définir les fragments à extraire et utiliser un modèle Jinja2 pour les associer dans une fonction JavaScript qui s'exécute correctement. La fonction retournera un dictionnaire avec la durée de nos manèges.
Nous allons exécuter ces fonctions en utilisant une bibliothèque obscure appelée Py_mini_racer. Cette bibliothèque exécute du code JavaScript à partir de Python, renvoyant des objets Python que nous pouvons utiliser.
J'ai essayé d'utiliser le Moteur PyV8 de Google, mais ne peut pas le faire fonctionner. Il semble que le projet a été abandonné.
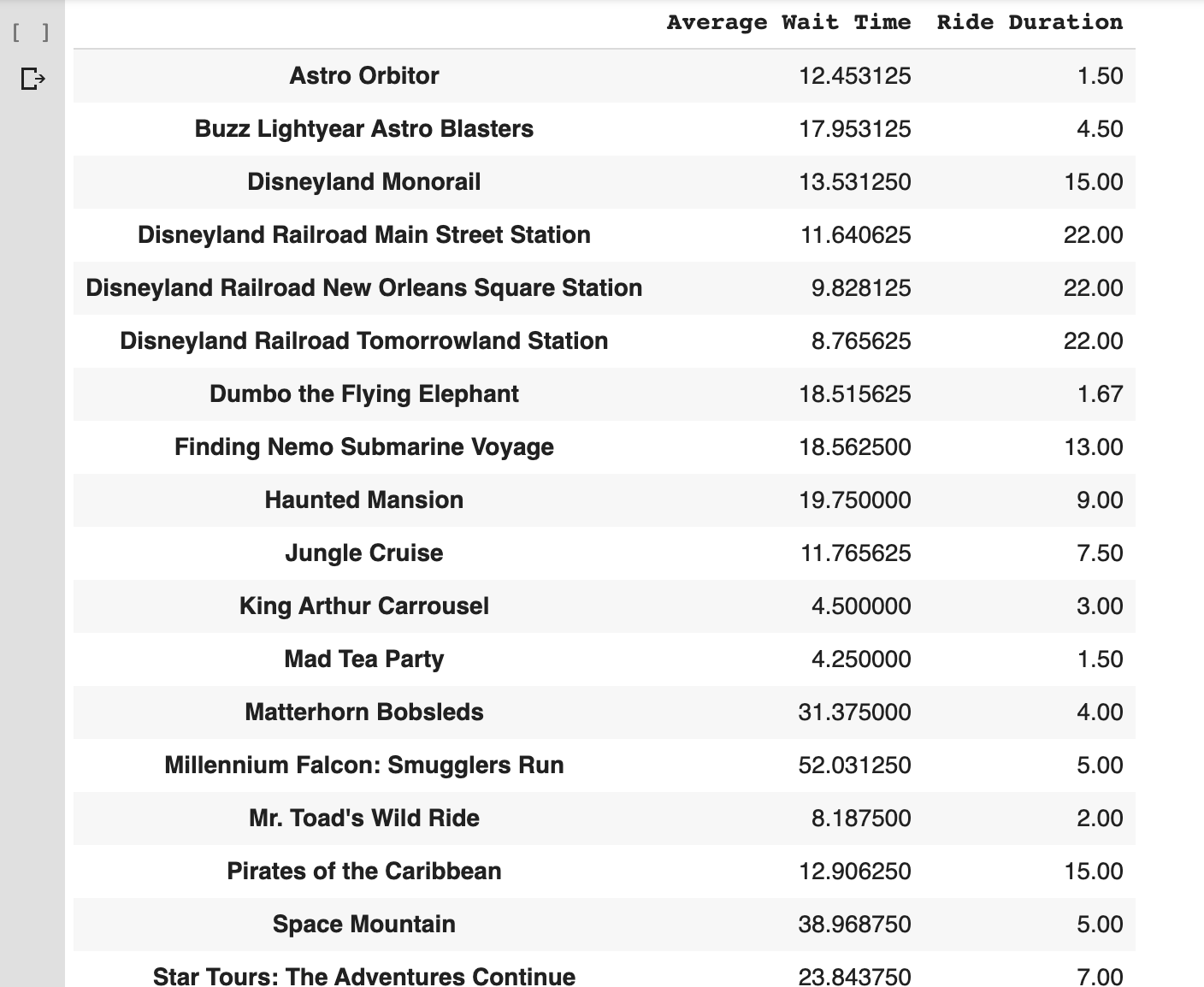
Nous avons maintenant les deux ensembles de données dont nous avons besoin pour produire notre graphique, mais nous devons commencer par traiter certains éléments.
Traitement de nos données source
Nous devons combiner les jeux de données que nous avons grattés, les nettoyer, calculer la moyenne, etc.
Nous allons compléter ces étapes:
- Divisez le jeu de données extrait en deux dictionnaires Python. Un avec les horodatages et l'autre avec les temps d'attente par trajet.
- Filtrez les parcours avec moins de 64 points de données pour conserver le même nombre de lignes de données par parcours.
- Calculez le nombre moyen de temps d'attente par trajet.
- Combinez le temps d'attente moyen par trajet et sa durée dans une trame de données.
- Éliminer les lignes avec des colonnes vides.
Voici à quoi ressemble le bloc de données final.

Visualiser nos données
Nous sommes presque dans la ligne d'arrivée. Dans cette étape, nous allons faire la partie amusante! Visualiser le bloc de données que nous avons créé.
Nous allons compléter ces étapes:
- Convertissez le cadre de données pandas en un dictionnaire orienté ligne. L'axe des abscisses est le temps d'attente moyen et l'axe des ordonnées, la durée du trajet. L'étiquette est le nom de la course.
- Utilisation Complotement générer un nuage de points étiqueté.
Vous devez faire glisser les étiquettes manuellement pour les rendre plus lisibles.


Nous avons enfin une visualisation qui ressemble beaucoup à celle que nous avons trouvée sur Reddit.
Dans notre dernière étape, nous produirons une visualisation originale construite à partir des mêmes données que nous avons collectées pour celle-ci.
Recadrer nos données
Reconstruire la visualisation originale a pris un travail sérieux et nous ne produisons rien de nouveau. Nous aborderons cela dans cette dernière section.
La visualisation originale manquait d'un crochet émotionnel. Et si les manèges ne sont pas amusants pour moi?
Nous allons tirer un ensemble de données supplémentaire: les évaluations par course par différents groupes d'âge. Cela nous aidera à visualiser non pas les meilleures manèges qui auront moins de temps d’attente, mais aussi ceux qui seraient plus amusants pour un groupe d’âge donné.
Nous allons compléter ces étapes pour recadrer la visualisation originale:
- Nous voulons savoir quels groupes d’âge auront le plus de plaisir par trajet.
- Nous allons chercher les cotes de conduite moyennes par groupe d'âge de https://touringplans.com/disneyland/attractions.
- Nous allons calculer un «score de satisfaction» par trajet et par groupe d'âge, qui correspond au nombre de minutes par trajet divisé par le nombre moyen de minutes de temps d'attente.
- Nous allons utiliser Plotly pour afficher un graphique à barres avec les résultats.

Ceci est la page avec nos données supplémentaires.
Nous raclons tout comme nous avons tiré les durées de trajet.
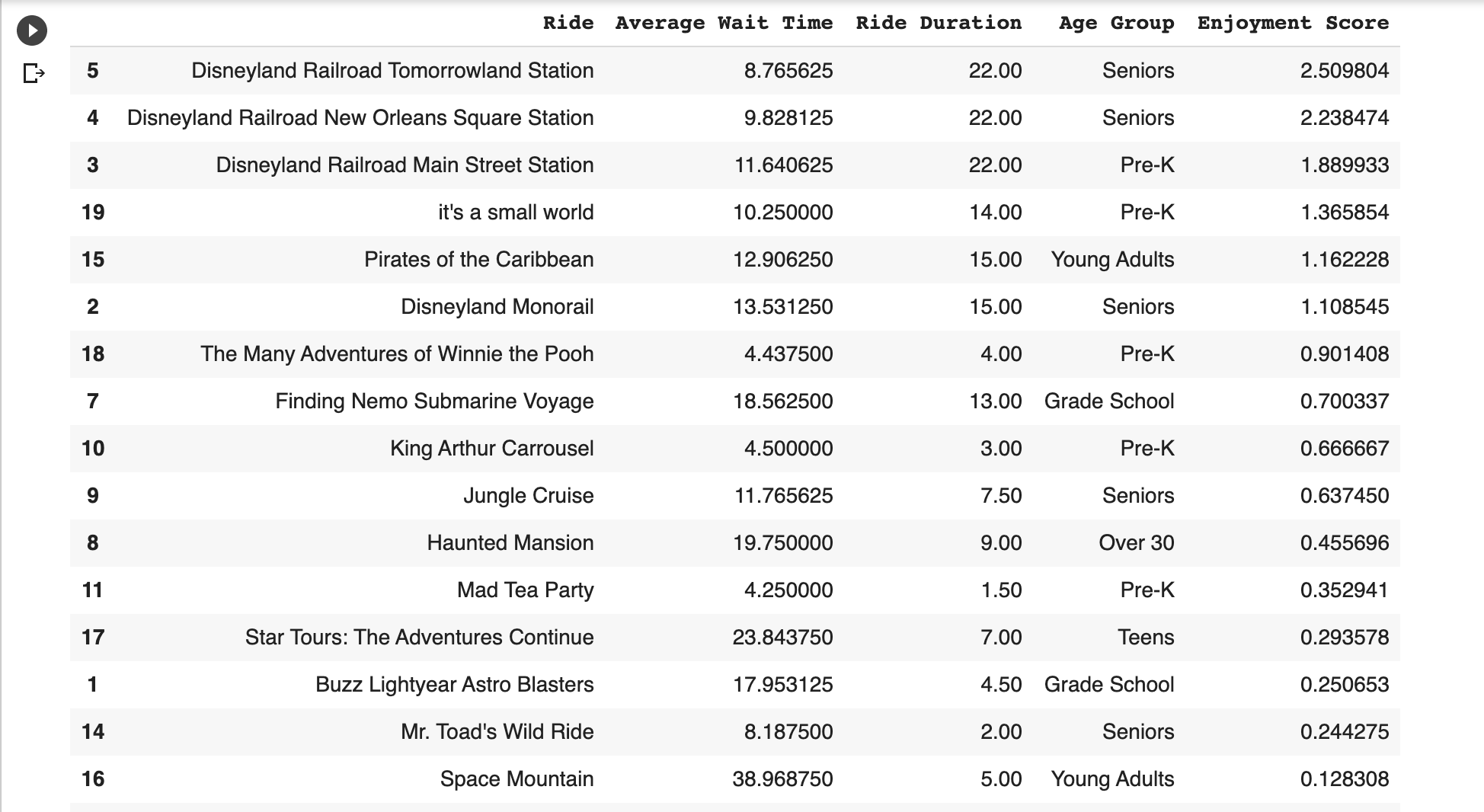
Résumons le bloc de données original en utilisant une nouvelle métrique: un Score de jouissance. 🙂
Nous le définissons comme la durée moyenne par le temps d'attente. Plus le nombre est élevé, plus nous devrions nous amuser, car nous devons attendre moins longtemps.
Voici à quoi ressemble le bloc de données mis à jour avec notre nouvelle métrique Score de jouissance.

Maintenant, voyons le.
Enfin, nous obtenons cette visualisation magnifique et extrêmement précieuse.


Ressources et projets communautaires
En janvier dernier, j'ai reçu un courrier électronique qui a lancé ma «croisade Python». Braintree avait rejeté la demande d’ouverture de compte marchand de RankSense parce qu’ils considéraient le référencement naturel comme une catégorie à haut risque.
Juste à côté des diseuses de bonne aventure, des épouses achetées par correspondance et des programmes «devenez riche rapidement»!
Nous avions travaillé sur l'intégration pendant trois semaines. Je me sentais vraiment en colère et embarrassé.
L'année dernière, je profitais de mon temps au sein de la communauté de la science des données et de l'IA. J'apprenais beaucoup de choses intéressantes et je m'amusais.
Je suis dans l’espace SEO depuis trop longtemps probablement. Malheureusement, ma génération a commis la grande erreur de laisser la spéculation et les tours de magie régir la perception de ce qu'est le référencement.
En conséquence, trop d'entreprises sont devenues la proie de charlatans.
J'ai eu le choix de quitter la communauté du référencement ou d'essayer d'encourager la nouvelle génération à conduire le changement afin que notre communauté puisse être un endroit amusant et fier.
J'ai décidé de rester, mais j'avais peur qu'essayer de conduire le changement seul avec une présence sociale minimale soit impossible.
Heureusement, j'ai regardé ça vidéo puissante, a écrit ce genre de manifesteet d’abandonner la rédaction d’articles pratiques en python tous les mois.
Je suis ravi de constater qu’en moins de six mois, Python est omniprésent dans la communauté du référencement et que l’élan ne cesse de croître.
Je suis vraiment enthousiasmé par notre communauté et le brillant avenir qui nous attend.
Maintenant, laissez-moi continuer à faire la lumière sur les projets impressionnants que nous continuons à lancer chaque mois. Donc, excitant de voir plus de gens rejoindre le mouvement Python. 🔥
Tyler a partagé un projet pour générer automatiquement des méta-descriptions à l'aide d'un programme de synthèse de classement de texte.
J'ai un cahier de notes colab pour générer automatiquement des méta-descriptions avec TextRank!
– Tyler Reardon (@TylerReardon) 20 septembre 2019
Hugo a partagé son premier script qui automatise l'exportation de rapports SEMrush.
Mon tout premier script Python: https://t.co/gyHbhRVtkI
Il vous permet d'automatiser les exportations de rapports organiques Semrush. Je suis ouvert à vos retours et suggestions
– Hugo Akh (@hugodeuxfois) 21 septembre 2019
Jeffrey travaille sur un outil d’intelligence artificielle permettant de casser le blocage de l’écrivain et d’octroyer son code source Python.
Je travaille sur un outil d'écriture qui utilise l'IA pour aider à battre le bloc de l'écrivain! https://t.co/Y4fItfoLgS (Python backend open source à https://t.co/Bk8pG5aHEc)
Je vous remercie! Je trouve le marketing assez difficile / difficile pour moi.
– Jeffrey Shek (@shekkery) 20 septembre 2019
Charly travaille sur un traducteur et classificateur d'URL.
Hey @hamletbatista! Je travaille sur un traducteur / classificateur d'URL construit avec #Python & interagir avec @googlesheets. Ce n'est pas encore 100%, mais notre chat @brightonseo m'a donné l'assurance que je devrais cesser de m'inquiéter de la perfection du code et commencer à le partager!
– Charly Wargnier (@DataChaz) 20 septembre 2019
Davantage de ressources:
Crédits d'image
Toutes les captures d'écran réalisées par l'auteur, octobre 2019
Images in post: fournies par l'auteur


