

Extraits en vedette, également connu sous le nom d'emplacements «position zéro» sur Google, ont récemment reçu leur juste part de gloire et de blâme.
Alors que certaines grandes entreprises comme Forbes Nous nous sommes demandés si Google volait du trafic avec l'extrait en vedette. Les créateurs de contenu comme moi ont trouvé facile d'obtenir plus de trafic, grâce à la possibilité de classer les petits sites sur un extrait en vedette.
Cet article vous donnera une brève idée sur la manière de classer une page dans l'extrait de site de Google, sans créer de lien vers cette page.
Comprendre les types
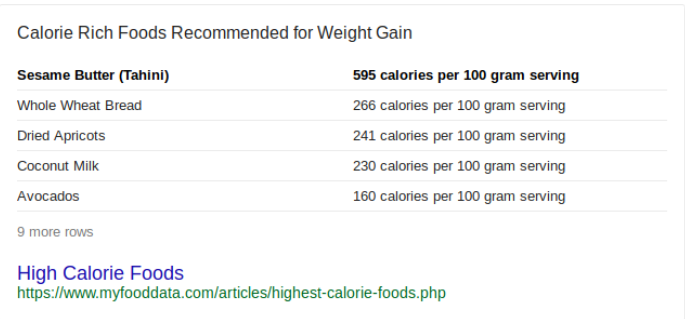
Il existe trois principaux types d'extraits proposés. Comme la plupart de nos clients sont des blogueurs, nous avons tendance à choisir les extraits de paragraphe ou les extraits de liste. L'extrait de table est un autre élément populaire que vous pouvez cibler.
Voici un rapide graphique d’Ahrefs sur le type d’extrait de code et leurs pourcentages.

Cibler les bons mots-clés
Une fois que vous avez finalisé le type d’extrait souhaité, il est temps d’enfoncer profondément recherche de mots clés pour trouver les mots clés qui conviennent à votre blog et aux exigences du type d'extrait recherché.
Si vous optez pour un extrait de paragraphe, vous devrez rechercher des mots-clés principalement liés à ces types:

Si vous essayez de classer pour une liste numérique (liste numérotée ou puces), l’idée serait de structurer votre contenu de manière à ce qu’il offre des guides pas à pas à quelqu'un. Selon notre expérience, Google affiche uniquement une liste numérique sur un extrait de code lorsque le mot clé indique à Google que le chercheur recherche une liste.

Pour les extraits de table, l’idée est d’avoir sur votre site Web des données de schéma structurées qui comparent au moins deux ensembles de données sur la page. Il n’est pas nécessaire de disposer d’un tableau basé sur des colonnes correctement formaté pour pouvoir classer les extraits de tableau tant que la comparaison et le schéma sont présents.
Comprendre le type et cibler les bons mots clés représentera plus de la moitié du travail à effectuer pour classer votre site Web sur l'extrait de code proposé avec zéro lien.
Cependant, vous ne gagnerez pas la bataille en annulant un extrait déjà existant. Cela ne fonctionnera que pour les mots clés pour lesquels Google n'a pas déjà défini le classement des extraits de code.
Pour récupérer des extraits de la compétition existante, vous devez effectuer quelques étapes supplémentaires.
Copier votre concurrent
Certains l'appelleront «être inspiré», mais ce que vous faites est essentiellement de copier la structure d'un article d'extrait vedette existant et d'essayer de l'améliorer (avec le contenu et, si possible, avec des liens).
Qu'est-ce que je veux dire quand je dis, copier la structure d'une page existante et l'améliorer? Si vous souhaitez classer l'extrait en vedette pour le mot clé "meilleures marques de nourriture pour chats" et si celle qui est actuellement classée compte déjà 20, vous devez créer une liste de 25, exactement au même format que le courant utilise.
Une fois que cela est fait, la dernière étape consiste simplement à vous assurer que vous avez un schéma approprié sur la page.
Remarque: Il est très peu probable que cette méthode vous aide à prendre le pas sur un extrait existant, à moins que vous ne figuriez également parmi les dix premiers pour ce mot clé.
Comment trouver des mots-clés pour les extraits en vedette?
Comme vous pouvez l’imaginer, trouver le bon mot-clé à cibler représente la moitié de la bataille en matière de classement sur les extraits vedettes.
j'utilise Semrush, mais n'hésitez pas à utiliser vos propres outils. Voici à quoi ressemble le processus de notre agence.
Supposons, aux fins de cet article, que je dirige un blog pour animaux de compagnie et que je suis intéressé par le classement de plusieurs extraits en vedette.
Je voudrais aller à Semrush et mettre l'un de mes concurrents sur la recherche.
Source: Semrush
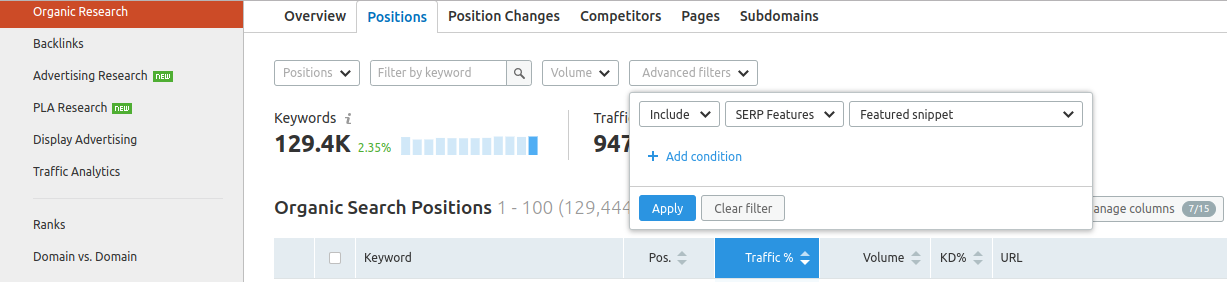
Cliquez maintenant sur «Recherche organique», sélectionnez des positions et, parmi les filtres avancés, sélectionnez – Inclure> Fonctions de recherche> extrait sélectionné.
Source: Semrush
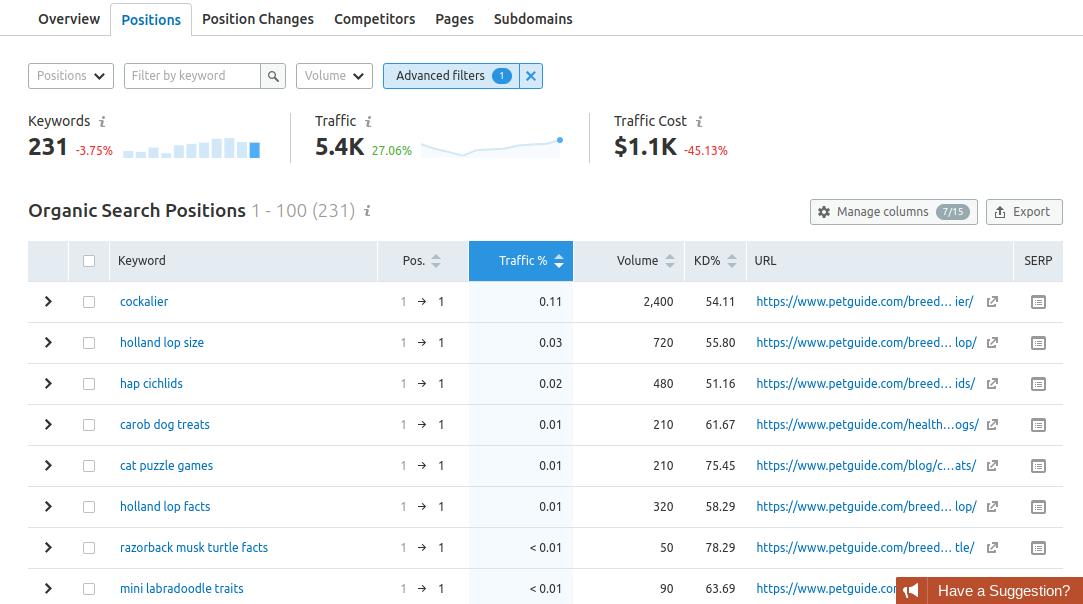
Cela vous donnera une énorme liste de mots-clés qui sont actuellement classés comme extraits sélectionnés. Comme vous pouvez le constater, nous avons trouvé environ 231 possibilités de cibler ici:
Source: Semrush
Il est temps d'ajouter une autre condition à nos filtres avancés. Choisissons inclure> nombre de mots> supérieur à cinq. Voici à quoi ressemble le nouveau résultat:
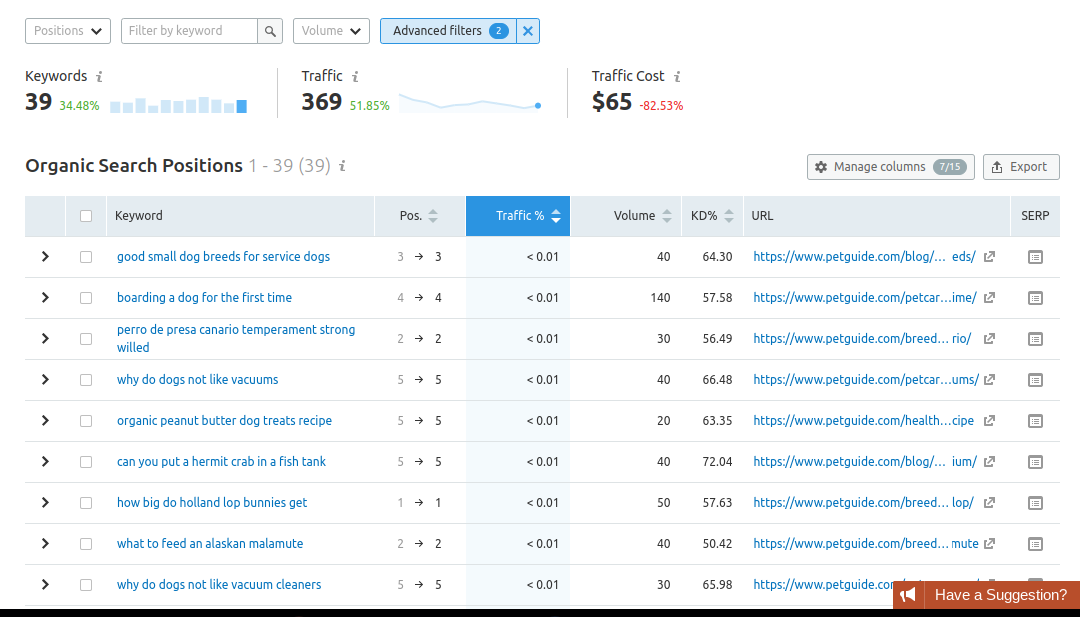
Source: SEMrush
A partir de là, organisez simplement les mots-clés par volume, puis sélectionnez ceux qui correspondent à votre marché cible. Comme pour toute recherche de mots clés, vous devrez rechercher des mots clés peu concurrentiels et dont le volume de recherche est modéré. Personnellement, j'essaierais de choisir des mots clés comportant moins de 500 recherches mensuelles.
Assurez-vous de suivre les trois étapes initiales dont nous avons discuté. Vous aurez presque toujours une chance plus élevée de vous classer sur un extrait en suivant cette stratégie.
Khalid Farhan publie des blogs sur le marketing Internet sur KhalidFarhan.com. Il peut être trouvé sur Twitter @iamkhalidfarhan.
Lecture connexe

Une nouvelle étude révèle que les étoiles d’évaluation Google constituent une preuve sociale de votre marque, augmentant ainsi le CTR de votre site de plus de 35%.

Le puissant moteur de toute entreprise est sa concurrence. Trois outils de recherche compétitifs qui fournissent des informations hautement exploitables.

Google n'a jamais confirmé son existence, mais de nombreux référenceurs pensent que Google Sandbox existe. Alors, existe-t-il en 2019? Si oui, comment éviter d'être affecté?

Désormais, l’outil gratuit «génère automatiquement les meilleurs sites concurrents qu’il utilise comme base pour un rapport d’analyse de la concurrence plus approfondi», a déclaré le président d’Alex Alexa.com, Andrew Ramm.


