
Au cours des derniers mois, Google a annoncé que deux systèmes en cours de recherche dans la recherche Google étaient également en source ouverte. Tout le monde peut voir comment ils travaillent.
Certaines parties de Google Search faisant appel à des sources d'approvisionnement ouvertes de Google ne sont pas envisageables, même il y a un an.
Comme prévu, les guides ultimes ne manquent pas pour optimiser votre site pour BERT. Vous ne pouvez pas.
BERT aide Google à mieux comprendre l'intention de certaines requêtes et n'a rien à voir avec le contenu de la page annoncé.
Si vous avez lu mon l'apprentissage en profondeur articles, vous devez non seulement avoir une compréhension pratique du fonctionnement de BERT, mais également savoir comment l'utiliser à des fins de référencement automatisation de la classification d'intention.
Développons ceci et couvrons un autre cas d’utilisation: la synthèse de texte à la pointe de la technologie.
Nous pouvons utiliser la synthèse de texte automatisée pour générer des méta-descriptions que nous pouvons renseigner sur des pages qui n'en ont pas.
Pour illustrer cette technique puissante, je vais télécharger et résumer automatiquement mes dernier article et comme d’habitude, je partagerai des extraits de code Python que vous pourrez suivre et adapter à votre propre site ou à ceux de vos clients.
Voici notre plan d'action:
- Discuter de la synthèse de texte automatisée.
- Découvrez comment trouver du code SOTA à la pointe de la technologie que nous pouvons utiliser pour la synthèse.
- Téléchargez le code de résumé du texte et préparez l'environnement.
- Télécharger mon dernier article et grattez uniquement le contenu principal de la page.
- Utilisez la synthèse de texte abstractive pour générer le résumé de texte.
- Passez en revue les concepts derrière PreSumm.
- Discutez de certaines des limitations.
- Enfin, je partagerai des ressources pour en apprendre davantage et pour des projets communautaires.
Résumé de texte pour produire des méta-descriptions
Lorsque nous avons des pages riches en contenu, nous pouvons utiliser la synthèse de texte automatisée pour produire des méta-descriptions à grande échelle.
Il existe deux approches principales pour la synthèse de texte en fonction du résultat:
- Extractif: Nous avons divisé le texte en phrases et les avons classés en fonction de leur efficacité en tant que résumé de l’article entier. Le résumé contiendra toujours des phrases trouvées dans le texte.
- Abstractive: Nous générons des phrases potentiellement nouvelles qui capturent l’essence du texte.
En pratique, il est généralement judicieux d'essayer les deux approches et de choisir celle qui donne les meilleurs résultats pour votre site.
Comment trouver un code SOTA pour la synthèse de texte
Mon endroit préféré pour trouver du code et des documents de pointe est Papiers avec code.
Si vous parcourez la Section de l'état de l'art, vous pouvez trouver la recherche la plus performante pour de nombreuses catégories.
Si nous restreignons notre recherche à Résumé du texte, on peut trouver ce papier: Résumé de texte avec des codeurs prédéfinis, qui s'appuie sur le BERT.
De là, nous pouvons facilement trouver des liens vers le document de rechercheet surtout le code qui met en œuvre la recherche.
![]()
![]()

Il est également judicieux de consulter le classement mondial au cas où un document de qualité supérieure serait publié.
Télécharger le résumé et configurer l'environnement
Créez un bloc-notes dans Google Colab pour suivre les étapes suivantes.
Le code original trouvé dans le référentiel du chercheur ne facilite pas l’utilisation du code pour générer des résumés.
Vous pouvez sentir la douleur simplement en lisant ceci Question de Github. 😅
Nous allons utiliser un version fourchue du repo et quelques étapes simplifiées que j’ai adaptées de ce cahier.
Commençons par cloner le référentiel.
! git clone https://github.com/mingchen62/PreSumm.gitPuis installez les dépendances.
! pip install torch == 1.1.0 pytorch_transformers tensorboardX multi-processus pyrougeEnsuite, nous devons télécharger les modèles pré-formés.
Ensuite, nous devons décompresser et les déplacer vers des répertoires organisés.
Après cette étape, le logiciel de synthèse devrait être prêt.
Téléchargeons l’article que nous voulons résumer ensuite.
Créer un fichier texte à résumer
Comme je l'ai mentionné, nous résumerons mon dernier message. Laissons-le télécharger et nettoyons le code HTML pour ne conserver que le contenu de l'article.
Commençons par créer les répertoires nécessaires à la sauvegarde de notre fichier d’entrée ainsi que des résultats des résumés.
! mkdir / content / PreSumm / bert_data_test /
! mkdir / content / PreSumm / bert_data / cnndm
% cd / content / PreSumm / bert_data / cnndmMaintenant, téléchargeons l’article et extrayons le contenu principal. Nous allons utiliser un Sélecteur CSS ne gratter que le corps du poteau.

La sortie de texte est sur une ligne, nous allons la scinder avec le code suivant.
text = text.splitlines (True) # conserver les nouvelles lignesJ'ai supprimé la première ligne contenant le code de l'annonce sponsorisée et les dernières lignes contenant des métadonnées d'article.
text = text[1:-5] #remove sponsor code et meta dataEnfin, je peux écrire le contenu de l'article dans un fichier texte à l'aide de ce code.
avec open ("python-data-stories.txt", "a") en tant que f:
f.écritures (texte)Après cela, nous sommes prêts à passer à l’étape de synthèse.
Générer le résumé du texte
Nous allons générer un résumé abstractif, mais avant de pouvoir le générer, nous devons modifier le fichier. résumer.py.
Afin de garder les choses simples, j'ai créé un fichier de correctif avec les modifications que vous pouvez télécharger avec le code suivant.
! wget https://gist.githubusercontent.com/hamletbatista/f2741a3a74e4c5cc46ce9547b489ec36/raw/ccab9cc3376901b2f6b0ba0c4bbd03fa48c1b159/summarizer.patchVous pouvez consulter les modifications qu'il va apporter ici. Les lignes rouges seront supprimées et les lignes vertes seront ajoutées.
J'ai emprunté ces modifications au cahier lié ci-dessus et elles nous permettent de transmettre des fichiers à résumer et de voir les résultats.
Vous pouvez appliquer les modifications en utilisant ceci.
! patch <summary.patchNous avons une dernière étape préparatoire. Le code suivant télécharge certains tokenizer nécessaires au synthétiseur.
importer nltk
nltk.download ('punkt')Enfin, générons notre résumé avec le code suivant.
#CNN_DM abstractive
% cd / content / PreSumm / src
! python summaryizer.py -model test -mode test -sep_optim true -use_interval true -visible_gpus -1 -max_pos 512 -max_src_nsents 100 -max_length 200 -alpha 0,95 -min_length 50 -result_path ../results/abs_bert_cnndm_sampleVoici à quoi ressemble la sortie partielle.
Maintenant, passons en revue nos résultats.
! ls -l / content / PreSumm / resultsCela devrait montrer.
Voici le résumé du candidat.
! head /content/PreSumm/results/abs_bert_cnndm_sample.148000.candidate[UNK] [UNK] [UNK] : il y a beaucoup d'histoires émotionnelles et puissantes cachées dans une foule de données qui n'attendent que d'être trouvéeselle dit que la campagne a été si efficace qu'elle a remporté de nombreux prix, y compris le grand prix des lions de cannes pour la collecte créative de données.
[UNK]: nous allons reconstruire une visualisation de données populaire à partir du subreddit data is beautiful
Certains jetons aiment [UNK] et besoin d'explication. [UNK] représente un mot du vocabulaire BERT. Vous pouvez les ignorer. est un séparateur de phrases.
Comment fonctionne PreSumm
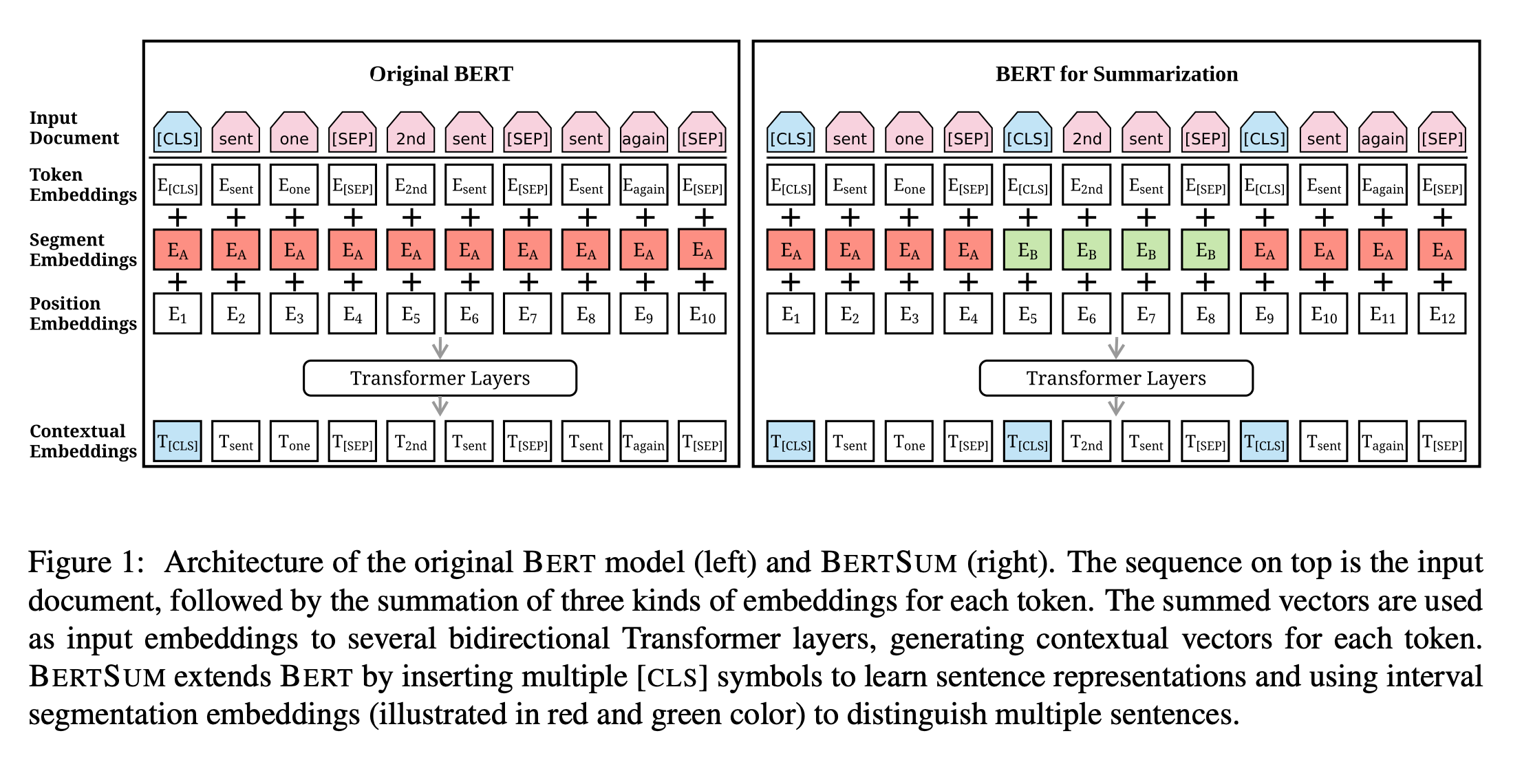

La plupart des techniques de résumé de texte extractives traditionnelles reposent sur la copie de parties du texte jugées utiles pour être incluses dans le résumé.
Cette approche, bien que efficace pour de nombreux cas d'utilisation, est plutôt restrictive dans la mesure où il se pourrait qu'aucune phrase ne soit utile pour résumer le texte.
Dans mes articles précédents sur l'apprentissage approfondi, j'ai comparé une approche de correspondance de texte traditionnelle / naïve avec la recherche d'une entreprise par son nom dans une rue.
Oui, ça marche, mais c'est plutôt limitant quand on le compare à ce qu'un système GPS vous permet de faire.
J'ai expliqué que le pouvoir d'utiliser des imbriqués repose sur le fait qu'ils fonctionnent comme des coordonnées dans l'espace. Lorsque vous utilisez des coordonnées, comme dans le système GPS, le nom de la chose importe peu (ou la langue que vous utilisez pour la nommer), c’est toujours le même endroit.
BERT a l'avantage supplémentaire que le même mot peut avoir des coordonnées complètement différentes selon le contexte. Par exemple, le mot «Washington» dans l'État de Washington et le pont George Washington signifient des choses complètement différentes et seraient codés différemment.
Mais l'avantage le plus puissant de BERT et de systèmes similaires réside dans le fait que les tâches PNL ne sont pas apprises de toutes pièces, elles partent d'un modèle linguistique pré-formé.
En d'autres termes, le modèle comprend au moins les nuances de la langue, comme la manière d'organiser les sujets, les adverbes, les prépositions, etc. avant de se mettre au diapason d'une tâche spécifique, telle que la réponse à des questions.
Les chercheurs de PreSumm énumèrent trois contributions principales de leurs travaux de synthèse:
- Ils ont adapté l'architecture neuronale BERT pour apprendre facilement les représentations de phrases complètes. Pensez aux mots incorporés pour les phrases afin d’identifier facilement les phrases similaires.
- Ils montrent clairement les avantages de l’utilisation de modèles linguistiques pré-formés pour les tâches de synthèse. Voir mes commentaires sur pourquoi c'est bénéfique
- Leurs modèles peuvent être utilisés comme blocs de construction pour de meilleurs modèles de synthèse.
Limitations PreSumm
Ce tweet met en évidence l'une des limites évidentes de PreSumm et de systèmes similaires reposant sur des modèles pré-formés. Leur style d'écriture est fortement influencé par les données utilisées pour les former.
PreSumm est formé aux articles CNN et DailyMail. Les résumés ne sont pas particulièrement efficaces lorsqu'ils sont utilisés pour générer des résumés de chapitres d'ouvrages de fiction.
PreSumm: synthèse de texte avec des codeurs prédéfinis
"des résultats à la pointe de la technologie dans tous les domaines, à la fois en termes d'extraction et d'abstraction"
abdos: https://t.co/oNV5YmLC6n
(barebones) Colab: https://t.co/5K7UXUH7SLVous pouvez vraiment dire que les synthétiseurs sont formés aux nouveaux jeux de données… pic.twitter.com/hsLVs3du2f
– Jonathan Fly 👾 (@jonathanfly) 2 septembre 2019
Pour le moment, la solution semble consister à recycler le modèle à l'aide de jeux de données de votre domaine.
Ressources pour en savoir plus et projets communautaires
C'est un excellent amorce sur la synthèse de texte classique.
J'ai couvert le résumé du texte il y a quelques mois lors d'un DeepCrawl séminaire en ligne. À ce moment-là, les chercheurs de PreSumm ont publié une version antérieure de leurs travaux axée uniquement sur la synthèse de texte extractive. Ils l'ont appelé BERTSum.
J'avais à peu près les mêmes idées, mais il est intéressant de voir à quelle vitesse ils ont amélioré leur travail pour couvrir à la fois les approches abstraites et extractives. De plus, réalisez des performances de pointe dans les deux catégories.
Progrès étonnants.
En parlant de progrès, la communauté SEO de Python continue de m'envoyer en l'air avec les nouveaux projets cool sur lesquels tout le monde travaille et publie chaque mois.
Voici quelques exemples notables. N'hésitez pas à cloner leurs référentiels, à voir ce que vous pouvez améliorer ou à adapter à vos besoins et à renvoyer vos améliorations!
Bulles: https://t.co/q1T7s0TW94
Extrayez les données de la console de recherche et affichez-les avec Bokeh (par les URL, par section avec regex et par sujet avec la classification en cluster TF-IDF). Enfin, il affiche un tableau des opportunités que vous pouvez télécharger (URL avec des positions hautes et un CTR bas) pic.twitter.com/CImGVkayVI– Natzir Turrado (@ natzir9) 29 octobre 2019
este? https://t.co/1q7UaEstbi
– Natzir Turrado (@ natzir9) 29 octobre 2019
Construire un petit robot + surveiller les changements de contenu. Prenant plus de temps que prévu, j'espère pouvoir partager bientôtish! pic.twitter.com/7hYewZsEBR
– Charly Wargnier (@DataChaz) 29 octobre 2019
Davantage de ressources:
Crédits d'image
Toutes les captures d'écran réalisées par l'auteur, octobre 2019
Image dans le post: Résumé de texte avec des codeurs prédéfinis


