
Robots.txt est l’un des fichiers les plus simples sur un site Web, mais c’est aussi l’un des plus faciles à gâcher. Un seul personnage hors de propos peut faire des ravages sur votre SEO et empêchez les moteurs de recherche d’accéder à du contenu important sur votre site.
C’est pourquoi les erreurs de configuration de robots.txt sont extrêmement courantes, même parmi les utilisateurs expérimentés. SEO professionnels.
Dans ce guide, vous apprendrez:
Qu'est-ce qu'un fichier robots.txt?
Un fichier robots.txt indique aux moteurs de recherche où ils peuvent et ne peuvent pas aller sur votre site.
En premier lieu, il répertorie tout le contenu que vous souhaitez verrouiller en dehors des moteurs de recherche tels que Google. Vous pouvez également dire à certains moteurs de recherche (pas Google) Comment ils peuvent explorer le contenu autorisé.
note importante
La plupart des moteurs de recherche sont obéissants. Ils n’ont pas l’habitude de casser une entrée. Cela dit, certains n'hésitent pas à choisir quelques verrous métaphoriques.
Google n'est pas l'un de ces moteurs de recherche. Ils obéissent aux instructions d'un fichier robots.txt.
Sachez simplement que certains moteurs de recherche l'ignorent complètement.
À quoi ressemble un fichier robots.txt?
Voici le format de base d’un fichier robots.txt:
Plan du site: [URL location of sitemap] Agent utilisateur: [bot identifier] [directive 1] [directive 2] [directive ...] Agent utilisateur: [another bot identifier] [directive 1] [directive 2] [directive ...]
Si vous n’avez jamais vu l’un de ces fichiers auparavant, cela peut sembler décourageant. Cependant, la syntaxe est assez simple. En bref, vous attribuez des règles aux robots en indiquant leur agent utilisateur suivi par les directives.
Explorons ces deux composants plus en détail.
User-agents
Chaque moteur de recherche s'identifie avec un agent utilisateur différent. Vous pouvez définir des instructions personnalisées pour chacune d’elles dans votre fichier robots.txt. Il y a des centaines d'agents utilisateurs, mais en voici quelques unes utiles pour SEO:
- Google: Googlebot
- Google images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
Sidenote.
Tous les agents utilisateurs sont sensibles à la casse dans le fichier robots.txt.
Vous pouvez également utiliser le caractère générique étoile (*) pour attribuer des directives à tous les agents utilisateurs.
Par exemple, supposons que vous vouliez empêcher tous les robots, à l'exception de Googlebot, d'explorer votre site. Voici comment vous le feriez:
Agent utilisateur: * Interdit: / Agent utilisateur: Googlebot Autoriser: /
Sachez que votre fichier robots.txt peut inclure des directives pour autant d’agents d’utilisateur que vous le souhaitez. Cela dit, chaque fois que vous déclarez un nouvel agent utilisateur, cela agit comme une table rase. En d’autres termes, si vous ajoutez des directives pour plusieurs agents d’utilisateur, les directives déclarées pour le premier agent d’utilisateur ne s’appliquent pas aux deuxième, troisième, quatrième, etc.
L'exception à cette règle est lorsque vous déclarez le même agent d'utilisateur plus d'une fois. Dans ce cas, toutes les directives pertinentes sont combinées et suivies.
IMPORTANT REMARQUE
Les robots d'exploration ne suivent que les règles déclarées sous le ou les agents utilisateurs qui s'applique le plus précisément à eux. C’est pourquoi le fichier robots.txt ci-dessus bloque l’exploration du site par tous les robots sauf Googlebot (et les autres robots Google). Googlebot ignore la déclaration d'agent utilisateur moins spécifique.
Les directives
Les directives sont des règles que vous souhaitez que les agents utilisateurs déclarés respectent.
Directives supportées
Voici les directives actuellement prises en charge par Google, ainsi que leurs utilisations.
Refuser
Utilisez cette directive pour indiquer aux moteurs de recherche de ne pas accéder aux fichiers et aux pages qui se trouvent sous un chemin spécifique. Par exemple, si vous souhaitez empêcher tous les moteurs de recherche d'accéder à votre blog et à ses publications, votre fichier robots.txt peut ressembler à ceci:
Agent utilisateur: * Interdire: / blog
Sidenote.
Si vous ne parvenez pas à définir un chemin après la directive d'annulation, les moteurs de recherche l'ignoreront.
Autoriser
Utilisez cette directive pour permettre aux moteurs de recherche d'analyser un sous-répertoire ou une page, même dans un répertoire autrement non autorisé. Par exemple, si vous souhaitez empêcher les moteurs de recherche d'accéder à toutes les publications de votre blog, à l'exception d'une seule, votre fichier robots.txt peut alors ressembler à ceci:
Agent utilisateur: * Interdire: / blog Autoriser: / blog / allowed-post
Dans cet exemple, les moteurs de recherche peuvent accéder à / blog / allowed-post. Mais ils ne peuvent pas accéder à:
/ blog / autre-post/ blog / yet-another-post/blog/download-me.pdf
Google et Bing prennent en charge cette directive.
Sidenote.
Comme avec la directive interdire, si vous ne parvenez pas à définir un chemin après la directive allow, les moteurs de recherche l'ignoreront.
une note sur les règles contradictoires
À moins que vous ne soyez prudent, les directives d'annulation et d'autorisation peuvent facilement entrer en conflit. Dans l'exemple ci-dessous, nous interdisons l'accès à /Blog/ et permettant l'accès à /Blog.
Agent utilisateur: * Interdit: / blog / Autoriser: / blog
Dans ce cas, le URL / blog / post-titre / semble être à la fois rejeté et autorisé. Alors qui gagne?
Pour Google et Bing, la règle est que la directive contenant le plus de caractères l'emporte. Ici, c’est la directive interdire.
Interdit: / blog / (6 caractères)Autoriser: / blog (5 personnages)
Si les directives autoriser et interdire ont la même longueur, la directive la moins restrictive l'emporte. Dans ce cas, ce serait la directive d'autorisation.
Sidenote.
Ici, /Blog (sans la barre oblique finale) est toujours accessible et analysable.
Cruciale, ce n'est que le cas pour Google et Bing. D'autres moteurs de recherche écoutent la première directive correspondante. Dans ce cas, cela est interdit.
Plan du site
Utilisez cette directive pour spécifier l'emplacement de votre plan Sitemap sur les moteurs de recherche. Si vous ne connaissez pas bien les sitemaps, ils incluent généralement les pages que vous souhaitez que les moteurs de recherche explorent et indexent.
Voici un exemple de fichier robots.txt utilisant la directive sitemap:
Plan du site: https://www.domain.com/sitemap.xml Agent utilisateur: * Interdit: / blog / Autoriser: / blog / post-title /
Quelle est l’importance d’inclure votre ou vos sitemap (s) dans votre fichier robots.txt? Si vous avez déjà envoyé votre candidature via la console de recherche, il est quelque peu redondant pour Google. Cependant, il indique aux autres moteurs de recherche tels que Bing où trouver votre sitemap, donc c’est toujours une bonne pratique.
Notez qu'il n'est pas nécessaire de répéter la directive sitemap plusieurs fois pour chaque agent utilisateur. Cela ne s'applique pas à un seul. Il est donc préférable d’inclure les directives de sitemap au début ou à la fin de votre fichier robots.txt. Par exemple:
Plan du site: https://www.domain.com/sitemap.xml Agent utilisateur: Googlebot Interdit: / blog / Autoriser: / blog / post-title / Agent utilisateur: Bingbot Interdit: / services /
Google les soutiens la directive sitemap, tout comme Ask, Bing et Yahoo.
Sidenote.
Vous pouvez inclure autant de sitemaps que vous le souhaitez dans votre fichier robots.txt.
Directives non supportées
Voici les directives qui sont n'est plus supporté par Google– dont certains, techniquement, ne l'ont jamais été.
Délai d'attente
Auparavant, vous pouviez utiliser cette directive pour spécifier un délai d'analyse en secondes. Par exemple, si vous souhaitez que Googlebot attend 5 secondes après chaque analyse, définissez le délai d'analyse sur 5 comme suit:
Agent utilisateur: Googlebot Délai d'attente: 5
Google ne prend plus en charge cette directive, mais Bing et Yandex faire.
Cela dit, soyez prudent lorsque vous définissez cette directive, surtout si vous avez un grand site. Si vous définissez un délai d’exploration de 5 secondes, vous empêchez les robots d’exploiter 17 280 URL par jour au maximum. Ce n'est pas très utile si vous avez des millions de pages, mais cela pourrait économiser de la bande passante si vous avez un petit site Web.
Noindex
Cette directive n'a jamais été officiellement prise en charge par Google. Cependant, jusqu'à récemment, Google pensait qu'il existait un «code qui gère les règles non prises en charge et non publiées (telles que noindex)». Ainsi, si vous souhaitez empêcher Google d'indexer tous les articles de votre blog, vous pouvez utiliser la directive suivante:
Agent utilisateur: Googlebot Noindex: / blog /
Cependant, le 1er septembre 2019, Google a précisé que cette directive n'est pas supportée. Si vous souhaitez exclure une page ou un fichier des moteurs de recherche, utilisez la balise meta robots ou x-robots. HTTP en-tête à la place.
Pas de suivi
Il s'agit d'une autre directive que Google n'a jamais officiellement prise en charge. Elle permettait aux moteurs de recherche de ne pas suivre les liens sur les pages et les fichiers par un chemin spécifique. Par exemple, si vous souhaitez empêcher Google de suivre tous les liens de votre blog, vous pouvez utiliser la directive suivante:
Agent utilisateur: Googlebot Nofollow: / blog /
Google a annoncé que cette directive n'était pas officiellement prise en charge le 1er septembre 2019. Si vous souhaitez maintenant ne plus suivre tous les liens d'une page, vous devez utiliser la balise méta des robots ou l'en-tête x-robots. Si vous souhaitez empêcher Google de suivre des liens spécifiques sur une page, utilisez l'attribut rel = “nofollow”.
Avez-vous besoin d'un fichier robots.txt?
Avoir un fichier robots.txt n’est pas crucial pour beaucoup de sites Web, surtout les plus petits.
Cela dit, il n’ya aucune bonne raison de ne pas en avoir un. Il vous donne plus de contrôle sur les endroits où les moteurs de recherche peuvent et ne peuvent pas aller sur votre site Web, ce qui peut vous aider dans les domaines suivants:
- Prévenir l'exploration de dupliquer le contenu;
- Garder les sections d'un site Web privées (par exemple, votre site intermédiaire);
- Empêcher l'exploration des pages de résultats de recherche internes;
- Prévenir la surcharge du serveur;
- Empêcher le gaspillage de Google “budget d'analyse. "
- Prévenir images, vidéosEt des fichiers de ressources apparaissant dans les résultats de recherche Google.
Notez que bien que Google n’indexe généralement pas les pages Web bloquées dans le fichier robots.txt, Il n’existe aucun moyen de garantir l’exclusion des résultats de la recherche à l’aide du fichier robots.txt..
Comme Google ditSi le contenu est lié à d’autres endroits sur le Web, il peut toujours apparaître dans les résultats de recherche Google.
Comment trouver votre fichier robots.txt
Si vous avez déjà un fichier robots.txt sur votre site Web, il sera accessible à l'adresse suivante: domaine.com/robots.txt. Accédez au URL dans votre navigateur. Si vous voyez quelque chose comme ceci, alors vous avez un fichier robots.txt:

Comment créer un fichier robots.txt
Si vous ne possédez pas déjà un fichier robots.txt, il est facile de le créer. Ouvrez simplement un document .txt vierge et commencez à taper des directives. Par exemple, si vous souhaitez interdire à tous les moteurs de recherche d’analyser votre / admin / répertoire, cela ressemblerait à quelque chose comme ça:
Agent utilisateur: * Interdit: / admin /
Continuez à élaborer les directives jusqu’à ce que vous soyez satisfait de ce que vous avez. Enregistrez votre fichier sous le nom «robots.txt».
Alternativement, vous pouvez également utiliser un générateur robots.txt comme celui-là.
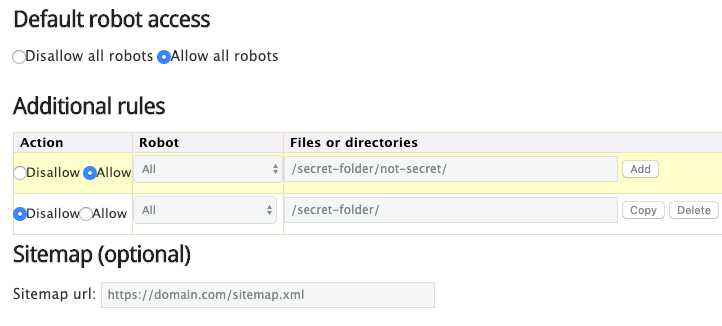
L'avantage d'utiliser un outil comme celui-ci est qu'il minimise les erreurs de syntaxe. C’est bien parce qu’une erreur peut entraîner une SEO catastrophe pour votre site – il est donc utile de pécher par excès de prudence.
L’inconvénient est qu’ils sont quelque peu limités en termes de personnalisation.
Où placer votre fichier robots.txt
Placez votre fichier robots.txt dans le répertoire racine du sous-domaine auquel il s’applique. Par exemple, pour contrôler le comportement d’exploration sur domain.com, le fichier robots.txt doit être accessible à l’adresse suivante: domaine.com/robots.txt.
Si vous souhaitez contrôler l’exploration sur un sous-domaine tel que blog.domain.com, le fichier robots.txt doit être accessible à l’adresse suivante: blog.domain.com/robots.txt.
Meilleures pratiques du fichier Robots.txt
Gardez cela à l'esprit pour éviter les erreurs courantes.
Utilisez une nouvelle ligne pour chaque directive
Chaque directive doit être placée sur une nouvelle ligne. Sinon, les moteurs de recherche seront confondus.
Mauvais:
Agent utilisateur: * Interdit: / répertoire / Interdit: / autre-répertoire /
Bien:
Agent utilisateur: * Interdit: / répertoire / Interdit: / autre-répertoire /
Utiliser des caractères génériques pour simplifier les instructions
Vous pouvez non seulement utiliser des caractères génériques (*) pour appliquer des directives à tous les agents utilisateur, mais également URL modèles lors de la déclaration de directives. Par exemple, si vous souhaitez empêcher les moteurs de recherche d'accéder aux URL de catégorie de produit paramétrées sur votre site, vous pouvez les répertorier comme suit:
Agent utilisateur: * Interdit: / produits / t-shirts? Interdit: / produits / hoodies? Interdit: / produits / vestes? …
Mais ce n’est pas très efficace. Il serait préférable de simplifier les choses avec un caractère générique comme celui-ci:
Agent utilisateur: * Interdit: / produits / *?
Cet exemple empêche les moteurs de recherche d'analyser toutes les URL du sous-dossier / product / qui contiennent un point d'interrogation. En d'autres termes, toute URL de catégorie de produit paramétrée.
Utilisez “$” pour spécifier la fin d'un URL
Inclure le symbole «$» pour marquer la fin d’un URL. Par exemple, si vous souhaitez empêcher les moteurs de recherche d'accéder à tous les fichiers .pdf de votre site, votre fichier robots.txt peut ressembler à ceci:
Agent utilisateur: * Interdit: /*.pdf
Dans cet exemple, les moteurs de recherche ne peuvent accéder aux URL se terminant par .pdf. Cela signifie qu’ils ne peuvent pas accéder à /file.pdf, mais à /file.pdf?id=68937586 car cela ne se termine pas par “.pdf”.
Utilisez chaque utilisateur-agent une seule fois
Si vous spécifiez le même agent utilisateur à plusieurs reprises, cela ne dérange pas Google. Il combinera simplement toutes les règles des différentes déclarations en une et les suivra toutes. Par exemple, si vous aviez les directives et agents utilisateur suivants dans votre fichier robots.txt…
Agent utilisateur: Googlebot Interdit: / a / Agent utilisateur: Googlebot Interdit: / b /
… Googlebot ne serait pas analyser l'un ou l'autre de ces sous-dossiers.
Cela dit, il est judicieux de déclarer chaque agent utilisateur une seule fois, car cela crée moins de confusion. En d’autres termes, vous êtes moins susceptible de faire des erreurs critiques en gardant les choses ordonnées et simples.
Utilisez la spécificité pour éviter les erreurs non intentionnelles
L'omission de fournir des instructions spécifiques lors de la définition des directives peut entraîner des erreurs facilement omises pouvant avoir un impact catastrophique sur votre système. SEO. Par exemple, supposons que vous avez un site multilingue et que vous travaillez sur une version allemande qui sera disponible dans le sous-répertoire / de /.
Parce que ce n’est pas tout à fait prêt, vous voulez empêcher les moteurs de recherche d’y accéder.
Le fichier robots.txt ci-dessous empêchera les moteurs de recherche d'accéder à ce sous-dossier et à tout ce qu'il contient:
Agent utilisateur: * Interdit: / de
Mais cela empêchera également les moteurs de recherche d’analyser les pages ou les fichiers commençant par / de.
Par exemple:
/ robes de créateurs //delivery-information.html/ depeche-mode / t-shirts //definitely-not-for-public-viewing.pdf
Dans ce cas, la solution est simple: ajoutez une barre oblique finale.
Agent utilisateur: * Interdit: / de /
Utilisez des commentaires pour expliquer votre fichier robots.txt aux humains
Les commentaires aident à expliquer votre fichier robots.txt aux développeurs, voire même à votre avenir. Pour inclure un commentaire, commencez la ligne par un dièse (#).
# Ceci indique à Bing de ne pas explorer notre site. Agent utilisateur: Bingbot Interdit: /
Les robots ignorent tout sur les lignes commençant par un hachage.
Utilisez un fichier robots.txt distinct pour chaque sous-domaine.
Robots.txt contrôle uniquement le comportement d’exploration sur le sous-domaine où il est hébergé. Si vous souhaitez contrôler l’exploration dans un sous-domaine différent, vous aurez besoin d’un fichier robots.txt distinct.
Par exemple, si votre site principal est installé sur domain.com et votre blog est assis sur blog.domain.com, vous auriez alors besoin de deux fichiers robots.txt. L'un doit aller dans le répertoire racine du domaine principal et l'autre dans le répertoire racine du blog.
Exemple de fichiers robots.txt
Vous trouverez ci-dessous quelques exemples de fichiers robots.txt. Celles-ci sont principalement d’inspiration, mais si l’on en trouve une qui correspond à vos exigences, copiez-le dans un document texte, enregistrez-le sous le nom “robots.txt” et chargez-le dans le répertoire approprié.
All-Access pour tous les robots
Agent utilisateur: * Refuser:
Sidenote.
A défaut de déclarer un URL après qu'une directive rend cette directive redondante. En d'autres termes, les moteurs de recherche l'ignorent. C’est pourquoi cette directive d’annulation n’a aucun effet sur le site. Les moteurs de recherche peuvent toujours analyser toutes les pages et tous les fichiers.
Pas d'accès pour tous les robots
Agent utilisateur: * Interdit: /
Bloquer un sous-répertoire pour tous les robots
Agent utilisateur: * Interdit: / dossier /
Bloquer un sous-répertoire pour tous les robots (avec un seul fichier autorisé)
Agent utilisateur: * Interdit: / dossier / Autoriser: / répertoire / page.html
Bloquer un fichier pour tous les robots
Agent utilisateur: * Interdit: /this-is-a-file.pdf
Bloquer un type de fichier (PDF) pour tous les robots
Agent utilisateur: * Interdit: /*.pdf
Bloquer toutes les URL paramétrées pour Googlebot uniquement
Agent utilisateur: Googlebot Interdit: / *?
Comment vérifier votre fichier robots.txt pour les erreurs
Les erreurs de Robots.txt peuvent facilement glisser à travers le filet, il est donc utile de garder un œil ouvert sur les problèmes.
Pour ce faire, recherchez régulièrement les problèmes liés à robots.txt dans le rapport «Couverture» de Console de recherche. Vous trouverez ci-dessous certaines des erreurs que vous pouvez voir, ce qu’elles signifient et comment les corriger.
Besoin de vérifier les erreurs liées à une page donnée?
Coller un URL dans Google URL Outil d'inspection dans la console de recherche. S'il est bloqué par le fichier robots.txt, vous devriez voir quelque chose comme ceci:
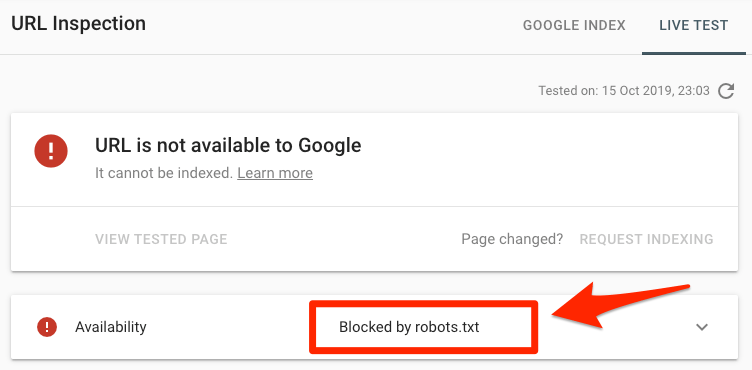
Soumis URL bloqué par robots.txt
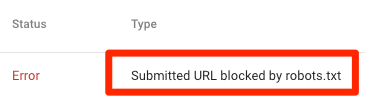
Cela signifie qu'au moins une des URL des plans de votre site soumis est bloquée par le fichier robots.txt.
Si vous créé votre sitemap correctement et exclu canonisé, noindexed, et redirigé pages, puis aucune page soumise ne doit être bloquée par robots.txt. Si tel est le cas, recherchez quelles pages sont affectées, puis ajustez votre fichier robots.txt en conséquence pour supprimer le bloc de cette page.
Vous pouvez utiliser Le test de robots.txt de Google pour voir quelle directive bloque le contenu. Faites attention en faisant ceci. Il est facile de faire des erreurs qui affectent d’autres pages et fichiers.
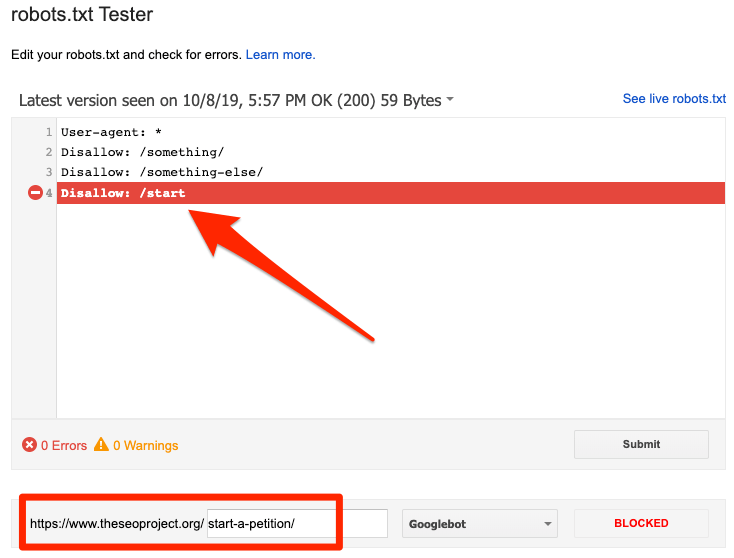
Bloqué par robots.txt
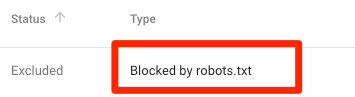
Cela signifie que votre fichier est bloqué par le fichier robots.txt qui n'est pas encore indexé dans Google.
Si ce contenu est important et doit être indexé, supprimez le bloc d'analyse dans le fichier robots.txt. (Cela vaut également la peine de s’assurer que le contenu n’est pas non indexé). Si vous avez bloqué le contenu du fichier robots.txt dans l’intention de l’exclure de l’index de Google, supprimez le bloc d’exploration et utilisez plutôt une balise méta ou un en-tête x-robots. C’est le seul moyen de garantir l’exclusion du contenu de l’index de Google.
Sidenote.
La suppression du bloc d'analyse lors d'une tentative d'exclusion d'une page des résultats de la recherche est cruciale. Si vous ne le faites pas, Google ne verra pas le tag noindex ni HTTP en-tête, donc il restera indexé.
Indexé, bien que bloqué par robots.txt
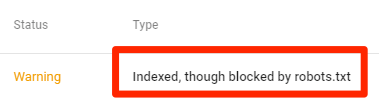
Cela signifie qu'une partie du contenu bloqué par robots.txt est toujours indexée dans Google.
Encore une fois, si vous essayez d’exclure ce contenu des résultats de recherche de Google, le fichier robots.txt n’est pas la bonne solution. Supprimez le bloc d’exploration et utilisez plutôt un balise meta robots ou balise x ‑ robots HTTP entête pour empêcher l'indexation.
Si vous avez bloqué ce contenu par accident et que vous souhaitez le conserver dans l'index de Google, supprimez le bloc d'analyse dans le fichier robots.txt. Cela peut aider à améliorer la visibilité du contenu dans la recherche Google.
FAQ
Voici quelques questions fréquemment posées qui ne rentrent pas naturellement dans notre guide. Faites-nous savoir dans les commentaires si quelque chose manque, et nous mettrons à jour la section en conséquence.
Quelle est la taille maximale d’un fichier robots.txt?
500 kilo-octets (grossièrement).
Où est le fichier robots.txt dans WordPress?
Même endroit: domaine.com/robots.txt.
Comment modifier le fichier robots.txt dans WordPress?
Soit manuellement, soit en utilisant l’un des les nombreux WordPress SEO plugins comme Yoast qui vous permet de modifier le fichier robots.txt à partir du backend de WordPress.
Que se passe-t-il si j'autorise l'accès au contenu non indexé dans le fichier robots.txt?
Google ne verra jamais la directive noindex car il ne peut pas explorer la page.
DYK bloquer une page à la fois avec un fichier robots.txt interdit Et un noindex dans la page n'a pas beaucoup de sens car Googlebot ne peut pas "voir" le noindex? pic.twitter.com/N4639rCCWt– Gary “理” Illyes (@methode) 10 février 2017
Dernières pensées
Robots.txt est un fichier simple mais puissant. Utilisez-le judicieusement, et cela peut avoir un impact positif sur SEO. Utilisez-le au hasard et, eh bien, vous vivrez à le regretter.
Vous avez plus de questions? Laisser un commentaire ou ping moi sur Twitter.


