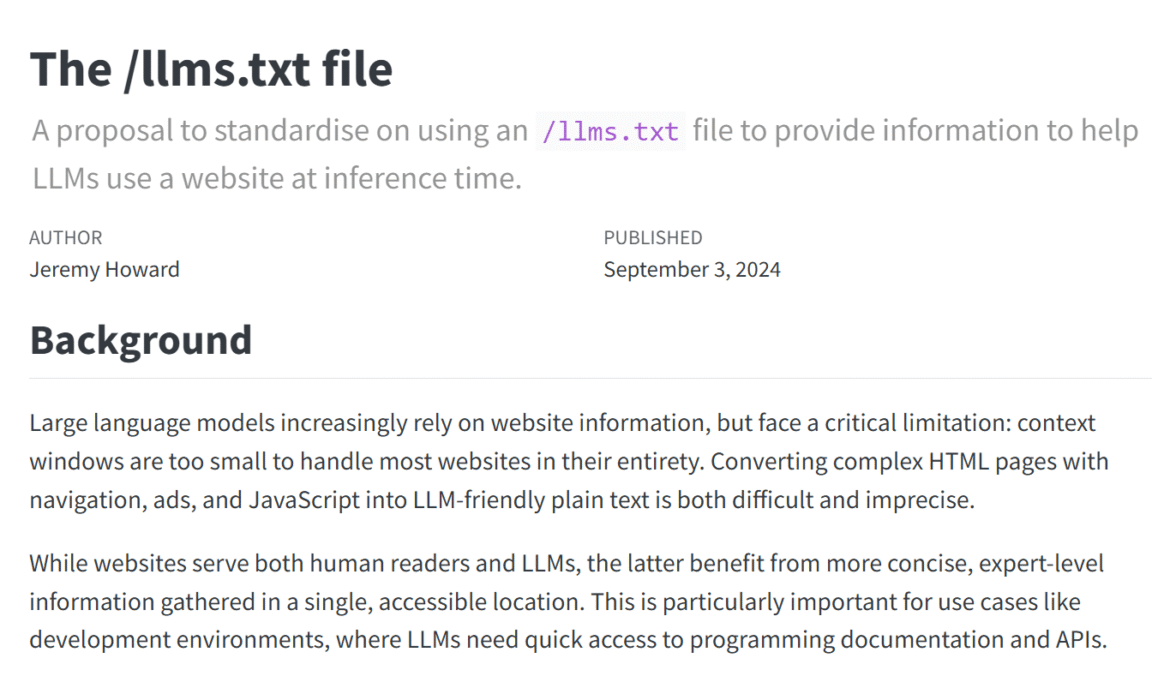
Les développeurs et les spécialistes du marketing sont invités à ajouter des fichiers LLMS.txt à leurs sites pour aider les modèles de grande langue (LLM) à «comprendre» leur contenu.
Mais qu'est-ce que LLMS.TXT, qui l'utilise, et – plus important encore – vous en souciez-vous?
LLMS.TXT est une norme proposée pour aider les LLM à accéder et à interpréter le contenu structuré à partir de sites Web. Vous pouvez lire la proposition complète sur llmstext.org.
En un mot, c'est un fichier texte conçu pour dire aux LLMS où trouver le bonnes choses: Documentation de l'API, politiques de retour, taxonomies de produits et autres ressources riches en contexte. L'objectif est de supprimer l'ambiguïté en donnant aux modèles de langage une carte organisée du contenu de grande valeur, afin qu'ils n'aient pas à deviner ce qui compte.
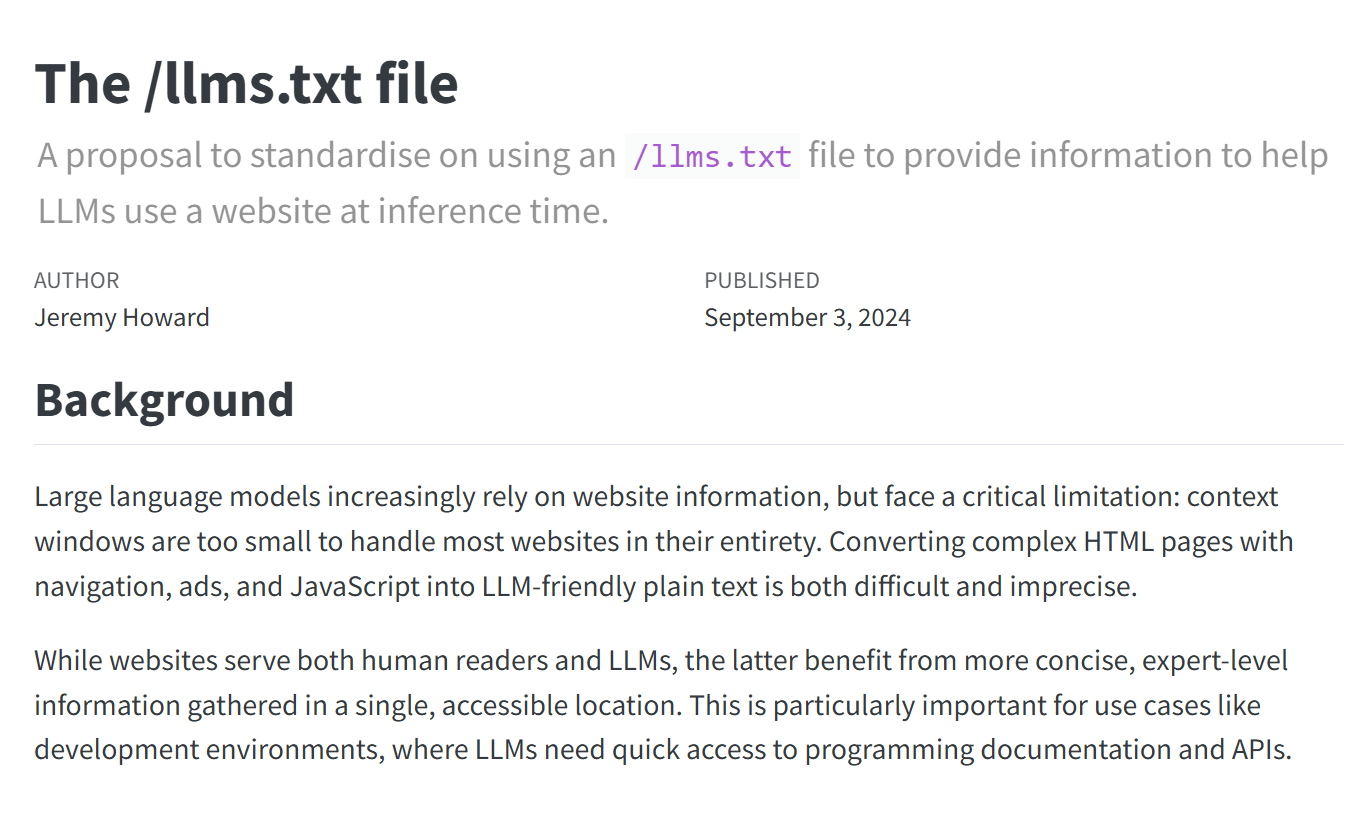
Une capture d'écran de la norme proposée sur https://llmstxt.org/.
En théorie, cela semble être une bonne idée. Nous utilisons déjà des fichiers comme robots.txt et sitemap.xml pour aider les moteurs de recherche à comprendre ce qu'il y a sur un site et où chercher. Pourquoi ne pas appliquer la même logique aux LLMS?
Mais surtout, Aucun fournisseur LLM majeur ne prend actuellement en charge LLMS.TXT. Pas ouvert. Pas anthropique. Pas google.
Comme je l'ai dit dans l'intro, llms.txt est un proposé standard. Je pourrais également proposer une norme (appelons-le s'il vous plaît-send-me-trafic-robot-overlords.txt), mais à moins que les principaux fournisseurs de LLM ne conviennent de l'utiliser, il n'a pas de sens.
C'est là que nous sommes avec LLMS.TXT: C'est une idée spéculative sans adoption officielle.
Ne dors pas sur robots.txt
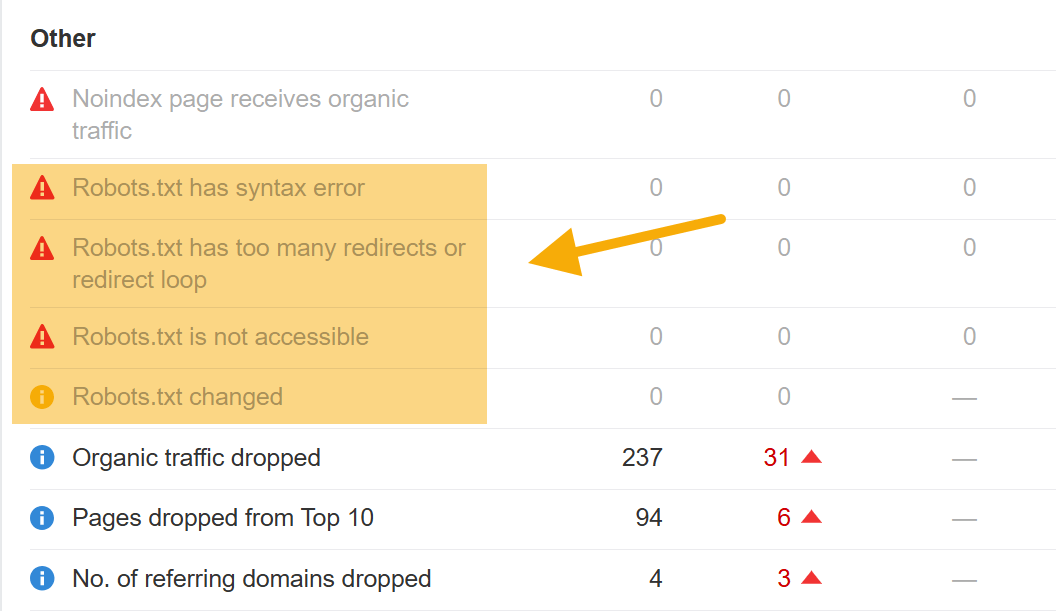
LLMS.TXT peut ne pas avoir un impact sur votre visibilité en ligne, mais Robots.txt le fait certainement.
Vous pouvez utiliser l'audit du site d'Ahrefs pour surveiller des centaines de problèmes de référencement techniques communs, y compris des problèmes avec votre fichier robots.txt qui pourraient sérieusement entraver votre visibilité (ou même empêcher votre site d'être rampé).
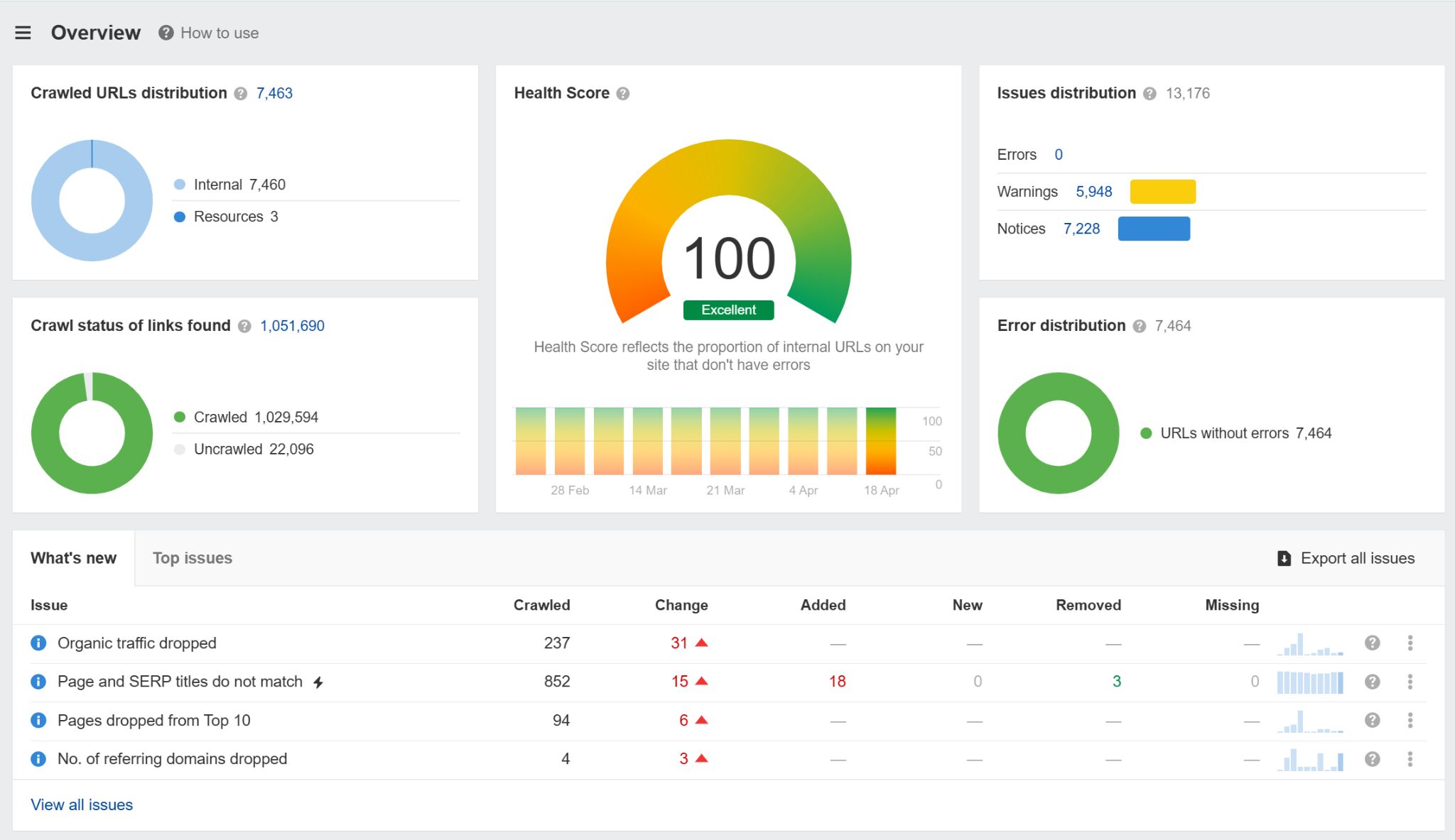
Voici à quoi ressemble un fichier llms.txt dans la pratique. Il s'agit d'une capture d'écran du fichier llms.txt réel d'Anthropic:
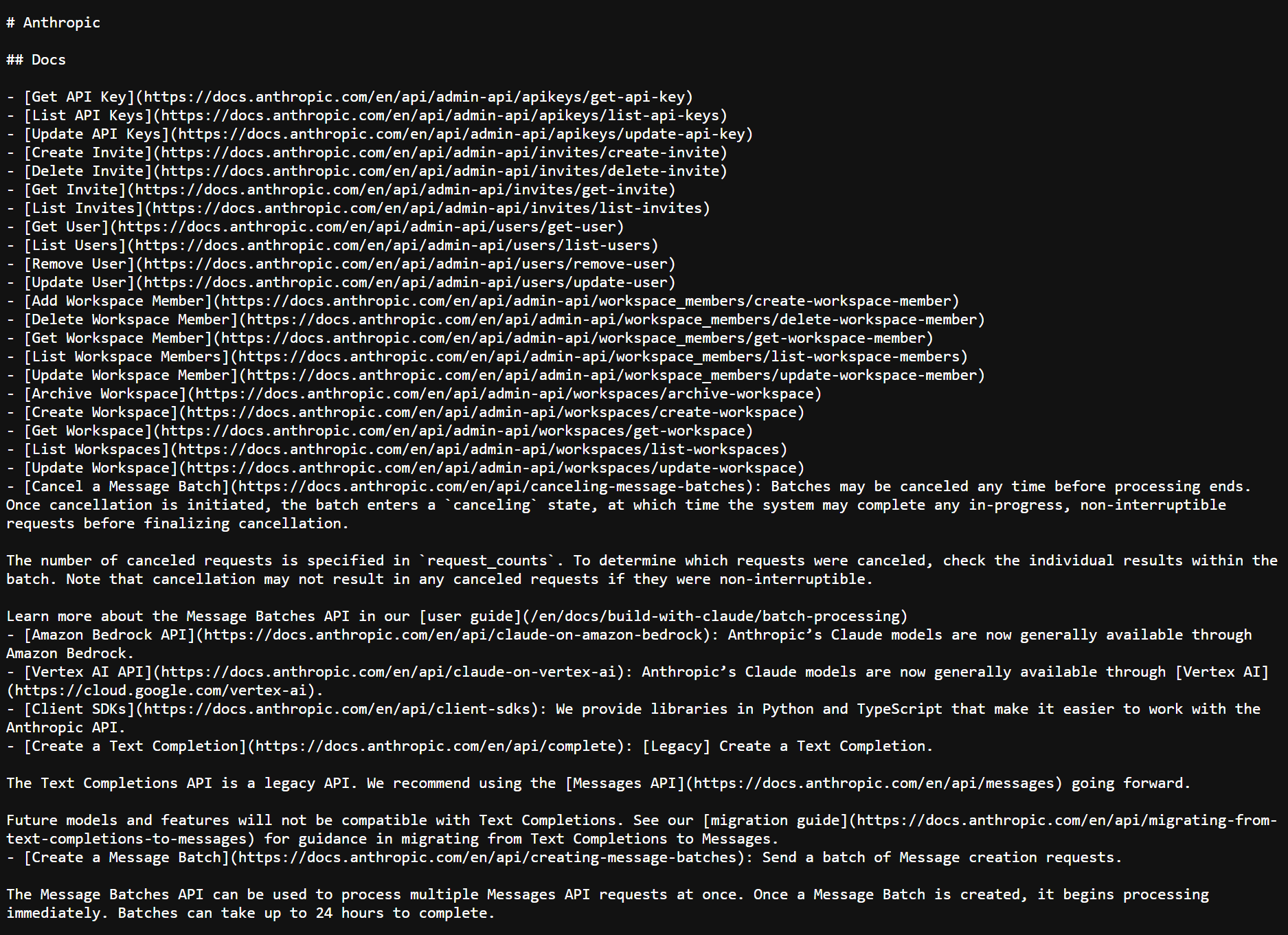
À la base, LLMS.TXT est un document Markdown (une sorte de fichier texte spécialement formaté). Il utilise des en-têtes H2 pour organiser des liens vers des ressources clés. Voici un échantillon de structure que vous pourriez utiliser:
# llms.txt ## Docs - /api.md A summary of API methods, authentication, rate limits, and example requests. - /quickstart.md A setup guide to help developers start using the platform quickly. ## Policies - /terms.md Legal terms outlining service usage. - /returns.md Information about return eligibility and processing. ## Products - /catalog.md A structured index of product categories, SKUs, and metadata. - /sizing-guide.md A reference guide for product sizing across categories.
Vous pouvez faire votre propre LLMS.txt en quelques minutes:
- Commencez par un fichier de marque de base.
- Utilisez H2S pour regrouper les ressources par type.
- Lien vers un contenu structuré et convivial.
- Gardez-le à jour.
- Hébergez-le dans votre domaine racine: https://yourdomain.com/llms.txt
Vous pouvez le créer vous-même ou utiliser un générateur LLMS.TXT gratuit (comme celui-ci) pour le faire pour vous.
J'ai lu sur certains développeurs expérimentant également des métadonnées spécifiques à LLM dans leurs fichiers LLMS.TXT, comme les budgets de jetons ou les formats de fichiers préférés (mais il n'y a aucune preuve que cela est respecté par les robots ou les modèles LLM).
Vous pouvez voir une liste de sociétés utilisant LLMS.TXT sur Directory.llmstxt.cloud – Un index entre communautaire des fichiers publics.txt publics.txt.
Voici quelques exemples:
- Mintlify: plateforme de documentation du développeur.
- Tinybird: API de données en temps réel.
- CloudFlare: répertorie les documents de performance et de sécurité.
- Anthropic: publie une carte de marque complète de ses documents API.
Mais qu'en est-il des grands joueurs?
Jusqu'à présent, Aucun fournisseur LLM majeur n'a officiellement adopté LLMS.TXT Dans le cadre de leur protocole de robot:
- Openai (gptbot): Honors Robots.txt mais n'utilise pas officiellement llms.txt.
- Anthropic (Claude): Publie ses propres llms.txt, mais ne déclare pas que ses robots utilisent la norme.
- Google (Gemini / Bard): Utilise Robots.txt (via User-Agent: Google-Extended) pour gérer le comportement de crawl AI, sans mention de la prise en charge LLMS.TXT.
- Meta (lama): Pas de robot ou de conseils public, et aucune indication de l'utilisation de LLMS.TXT.
Cela met en évidence un point important: la création d'un LLMS.txt n'est pas la même chose que de l'appliquer dans le comportement du robot. À l'heure actuelle, la plupart des vendeurs LLM traitent LLMS.TXT comme une idée intéressante, et non quelque chose qu'ils ont accepté de prioriser et de suivre.
À mon avis, non, pas encore.
Il n'y a aucune preuve que LLMS.TXT améliore la récupération de l'IA, augmente le trafic ou améliore la précision du modèle. Et aucun fournisseur ne s'est engagé à l'analyser.
Mais c'est aussi très facile à installer. Si vous avez déjà un contenu structuré comme les pages de produits ou les documents de développeur, la compilation d'un LLMS.txt est triviale. Il s'agit d'un fichier Markdown, hébergé sur votre propre site Web. Il n'y a peut-être aucun avantage observé, mais il n'y a pas non plus de risque. Si les LLM le suivent éventuellement comme une norme, il pourrait y avoir un petit avantage à être des adoptants précoces.
Je pense que llms.txt gagne du terrain parce que nous voulons tous influencer la visibilité de LLM, mais nous n'avons pas les outils pour le faire. Alors nous nous accrochons sur des idées qui sentir comme le contrôle.
Mais dans mon point de vue personnel, llms.txt est une solution à la recherche d'un problème. Les moteurs de recherche rampent et comprennent déjà votre contenu en utilisant des normes existantes comme Robots.txt et SiteMap.xml. Les LLM utilisent une grande partie de la même infrastructure.
Comme John Mueller de Google l'a récemment dit dans un article Reddit:
AFAIK Aucun des services d'IA n'a dit qu'ils utilisent LLMS.TXT (et vous pouvez dire quand vous regardez vos journaux de serveur qu'ils ne le vérifient même pas). Pour moi, c'est comparable à la balise Meta Meta Meta – c'est ce qu'un propriétaire de site prétend que son site concerne… (le site est-il vraiment comme ça? Eh bien, vous pouvez le vérifier. À ce moment-là, pourquoi ne pas simplement vérifier le site directement?)

En désaccord avec moi, ou vous souhaitez partager un exemple contraire? Envoyez-moi un message sur LinkedIn ou X.


