
Guider les moteurs de recherche pour explorer et indexer votre site Web comme vous le souhaitez peut être une tâche ardue. Bien que robots.txt gère l’accessibilité de votre contenu aux robots, il ne leur dit pas s’ils doivent indexer le contenu ou non.
C’est ce que les balises méta des robots et la balise x ‑ robots HTTP en-tête sont pour.
Voyons ce qu’il faut faire depuis le début. Vous ne pouvez pas contrôler l’indexation avec le fichier robots.txt. C’est une idée fausse commune.
La règle noindex de robots.txt n'a jamais été officiellement prise en charge par Google. Et en juillet 2019, il a été officiellement obsolète.
Dans ce guide, vous apprendrez:
Une méta-tag robots est un HTML extrait qui indique aux moteurs de recherche comment analyser ou indexer une page donnée. Il est placé dans le
section d’une page Web, et ressemble à ceci:La balise meta robots est couramment utilisée pour empêcher l’affichage de pages dans les résultats de recherche, bien qu’elle ait d’autres utilisations (plus de détails ultérieurement).
Il est possible que vous souhaitiez empêcher les moteurs de recherche d’indexer différents types de contenu:
- Pages fines avec peu ou pas de valeur pour l'utilisateur;
- Pages dans l'environnement de transfert;
- Pages d'administration et de remerciement;
- Résultats de recherche interne;
- PPC pages de destination;
- Pages sur les promotions à venir, les concours ou les lancements de produits;
- Dupliquer le contenu (utiliser balises canoniques suggérer la meilleure version pour l'indexation);
En règle générale, plus votre site Web est grand, plus vous aurez à gérer l’exploration et l’indexation. Vous souhaitez également que Google et les autres moteurs de recherche explorent et indexent vos pages le plus efficacement possible. Combinant correctement les directives de niveau page avec robots.txt et plans du site est crucial pour SEO.
Les méta tags des robots sont constitués de deux attributs: Nom et contenu.
Toi doit spécifiez des valeurs pour chacun de ces attributs. Voyons ce qu’il en est.
le Nom valeurs d'attribut et d'agent utilisateur
le Nom attribut spécifie quels robots doivent suivre ces instructions. Cette valeur est également appelée utilisateur-agent (UA) car les chenilles doivent être identifiées avec leurs UA demander une page. Votre UA reflète le navigateur que vous utilisez, mais les agents utilisateurs de Google sont, par exemple, Googlebot ou Googlebot-image.
le UA La valeur «robots» s’applique à tous les robots. Vous pouvez également ajouter autant de balises méta de robots à la liste.
section que vous avez besoin. Par exemple, si vous souhaitez empêcher vos images de s'afficher dans une recherche d'images Google ou Bing, ajoutez les balises META suivantes:Sidenote.
Les attributs de nom et de contenu ne sont pas sensibles à la casse. Les attributs «Googlebot-Image», «msnbot-media» et «Noindex» fonctionnent également pour les exemples ci-dessus.
le contenu directives d'attribut et d'analyse / d'indexation
le contenu Cet attribut fournit des instructions sur la manière d’analyser et d’indexer des informations sur la page. S'il n'y a pas de balise Meta robots disponible, les robots l'interprètent comme un index et le suivent. Cela leur donne la permission d'afficher la page dans les résultats de la recherche et d'explorer tous les liens de la page (sauf indication contraire avec rel = balise "nofollow").
Ce qui suit sont les valeurs prises en charge pour le contenu attribut par Google:
tout
La valeur par défaut de «index, follow», inutile d’utiliser cette directive.
noindex
Indique aux moteurs de recherche de ne pas indexer la page. Cela l'empêche de s'afficher dans les résultats de recherche.
pas de suivi
Empêche les robots d'explorer tous les liens de la page. Veuillez noter que ces URL peuvent toujours être indexables, en particulier si des backlinks pointent vers elles.
aucun
La combinaison de noindex, nofollow. Évitez d’utiliser cela comme un autre moteur de recherche (par exemple, Bing) ne supporte pas cela.
noarchive
Empêche Google d’afficher une copie en cache de la page dans le SERP.
ne pas traduire
Empêche Google de proposer une traduction de la page dans le SERP.
noimageindex
Empêche Google d'indexer les images intégrées à la page.
indisponible_après:
Indique à Google de ne pas afficher une page dans les résultats de recherche après une date / heure spécifiée. Fondamentalement un noindex directive avec une minuterie. La date / heure doit être spécifiée à l'aide de la touche RFC Format 850.
nosnippet
Opte de tous les extraits de texte et vidéo dans la SERP. Cela fonctionne aussi comme noarchive en même temps.
IMPORTANT REMARQUE
Depuis octobre 2019, Google propose des options plus granulaires pour contrôler si et comment vous souhaitez afficher vos extraits dans les résultats de la recherche. Ceci est en partie dû à la Directive européenne sur le droit d'auteur, Qui a d'abord été mis en œuvre par la France avec son nouvelle loi sur le droit d'auteur.
Surtout, cette législation affecte déjà tout propriétaires de sites Web. Comment? Parce que Google n'affiche plus les extraits (texte, image ou vidéo) de votre site aux utilisateurs situés en France, à moins que vous n'utilisiez leurs nouvelles balises méta de robots.
Nous discutons ci-dessous comment chacune de ces nouvelles balises fonctionne. Cela dit, si cela concerne votre entreprise et que vous recherchez une solution rapide, ajoutez les éléments suivants: HTML extrait à chaque page de votre site pour indiquer à Google que vous ne souhaitez aucune restriction sur vos extraits:
Notez que si vous utilisez Yoast SEO, ce morceau de code est ajouté automatiquement sur chaque page sauf si vous avez ajouté noindex ou nosnippet directives.
max-snippet:
Spécifie un nombre maximal de caractères que Google peut afficher dans leurs extraits de texte. Si vous utilisez 0, les extraits de texte seront désactivés. -1 ne déclare aucune limite pour l'aperçu du texte.
La balise suivante définira la limite à 160 caractères (similaire à la longueur de méta description standard):
max-image-preview:
Indique à Google si et quelle est la taille d'une image qu'il peut utiliser pour les extraits d'image. Cette directive a trois valeurs possibles:
- aucun aucun extrait d'image ne sera affiché
- standard – un aperçu de l'image par défaut peut être affiché
- large – l'aperçu de l'image le plus grand possible peut-être affiché
max-video-preview:
Définit un nombre maximal de secondes pour un extrait de vidéo. Comme pour l'extrait de texte, 0 désactive complètement l'option, -1 ne place aucune limite.
La balise suivante permettrait à Google d'afficher un maximum de 15 secondes:
une note rapide sur l'utilisation d'un data-nosnippet HTML attribut
Parallèlement aux nouvelles directives sur les robots introduites en octobre 2019, Google a également introduit le data-nosnippet HTML attribut. Vous pouvez l'utiliser pour baliser des parties de texte que vous ne souhaitez pas que Google utilise comme extrait de code.
Cela peut être fait dans HTML sur les éléments div, span et section. Data-nosnippet est considéré comme un attribut booléen, ce qui signifie qu'il est valide avec ou sans valeur.
Ceci est du texte dans un paragraphe qui peut être affiché sous forme d'extraità l'exclusion de cette partie
Cela n'apparaîtra pas dans un extraitEt ce ne sera pas non plus
Utilisation de ces directives
La plupart des référenceurs n’ont pas besoin d’aller au-delà des directives noindex et nofollow, mais il est bon de savoir qu’il existe également d’autres options. N'oubliez pas que toutes les directives répertoriées ci-dessus sont prises en charge par Google.
Vérifions la comparaison avec Bing:
| Directif | Bing | |
|---|---|---|
| tout | ✅ | ❌ |
| noindex | ✅ | ✅ |
| pas de suivi | ✅ | ✅ |
| aucun | ✅ | ❌ |
| noarchive | ✅ | ✅ |
| nosnippet | ✅ | ✅ |
| max-snippet: | ✅ | ❌ |
| max-image-preview: | ✅ | ❌ |
| max-video-preview: | ✅ | ❌ |
| ne pas traduire | ✅ | ❌ |
| noimageindex | ✅ | ❌ |
| indisponible_après: | ✅ | ❌ |
Vous pouvez utiliser plusieurs directives à la fois et les combiner. Mais si elles sont en conflit (par exemple, «noindex, index») ou si l’un est un sous-ensemble d’un autre (par exemple, «noindex, noarchive»), Google utilisera le plus restrictif. Dans ces cas, il s'agirait simplement de «noindex».
Sidenote.
Les directives d'extraits peuvent être remplacées par données structurées cela permet à Google d’utiliser toutes les informations contenues dans l’annotation. Si vous souhaitez empêcher Google d'afficher des extraits, ajustez l'annotation en conséquence et assurez-vous de ne pas avoir de contrat de licence avec Google.
Une note sur d'autres directives
Vous pouvez également rencontrer des directives spécifiques à d'autres moteurs de recherche. Un exemple serait “noyaca” qui empêche Yandex d'utiliser son propre répertoire pour générer des extraits de résultats de recherche.
D'autres peuvent avoir été utiles et utilisés dans le passé mais sont déjà obsolètes. Par exemple, le “noodp”Directive a été utilisée pour empêcher les moteurs de recherche d'utiliser le projet Open Directory pour générer des extraits.
Maintenant que vous savez à quoi ressemblent toutes ces directives, il est temps de passer à la mise en œuvre effective de votre site Web.
Les balises Meta des robots appartiennent à la section d'une page. C’est assez simple si vous éditez le code en utilisant HTML des éditeurs tels que Notepad ++ ou Brackets. Mais que se passe-t-il si vous utilisez un CMS avec SEO des plugins?
Concentrons-nous sur l’option la plus populaire.
Implémentation de balises META pour robots dans WordPress avec Yoast SEO
Allez à la section «Avancé» sous le bloc d'édition de chaque article ou page. Configurez la balise Meta des robots en fonction de vos besoins. Les paramètres suivants implémenteraient les directives «noindex, nofollow».
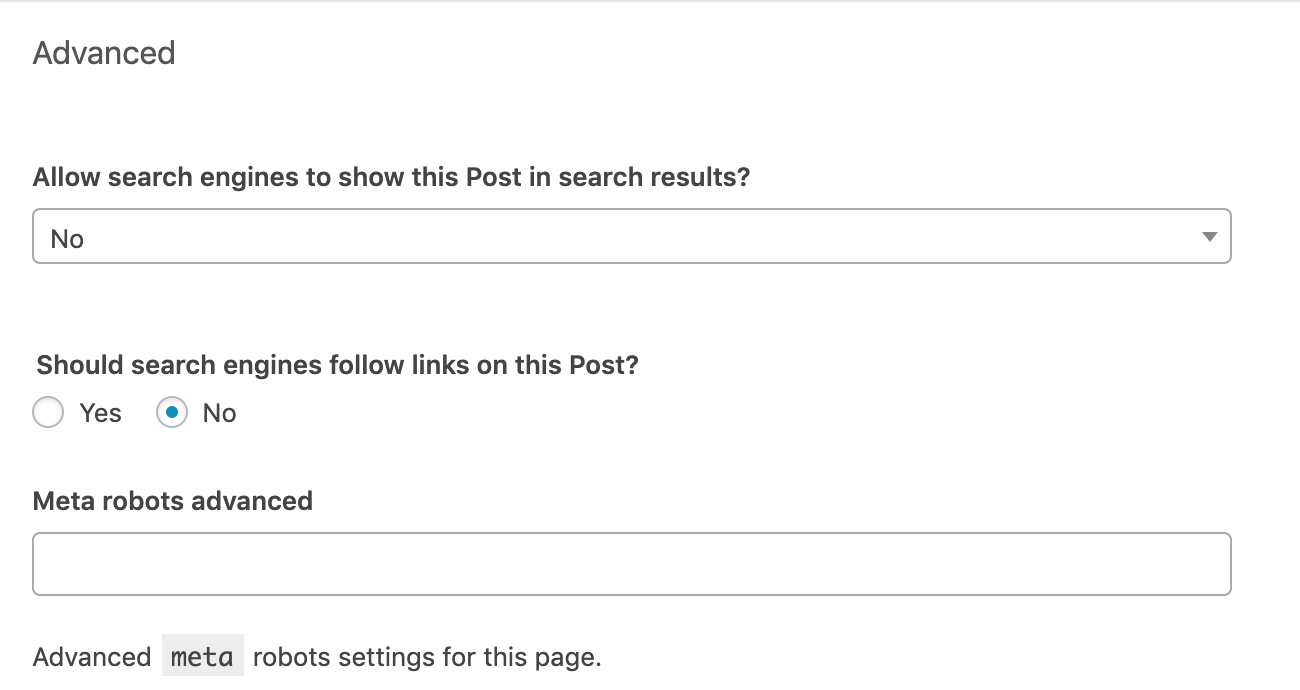
La ligne «Meta robots advanced» vous donne la possibilité de mettre en œuvre des directives autres que noindex et pas de suivi, tel que noimageindex.
Vous avez également la possibilité d'appliquer ces directives à l'échelle du site. Allez à «Apparence de la recherche» dans le menu Yoast. Vous pouvez y configurer des balises méta-robots sur tous les articles, toutes les pages ou uniquement sur des taxonomies ou des archives spécifiques.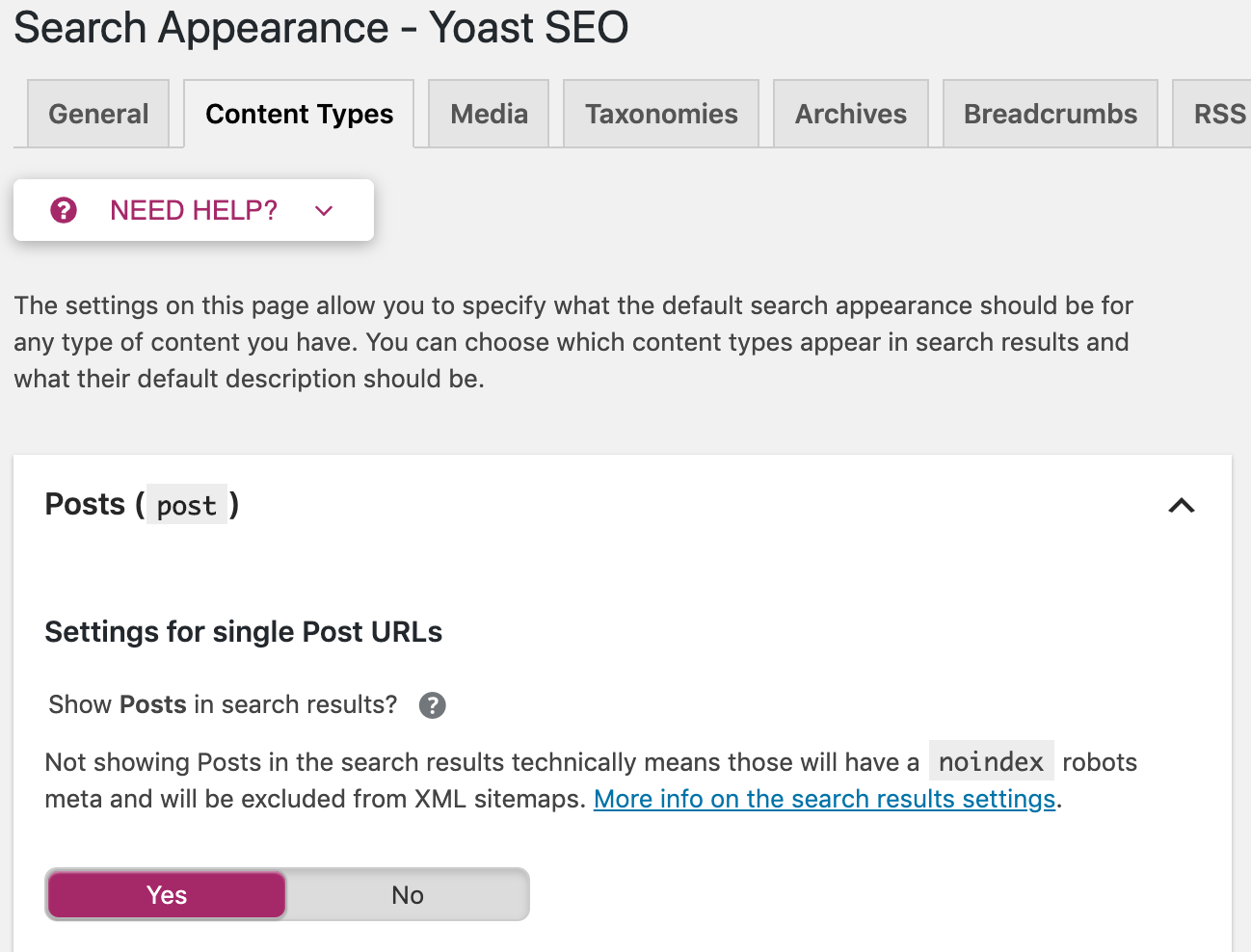
Sidenote.
Yoast n’est pas le seul moyen de contrôler les balises meta robots dans WordPress. Il y a beaucoup de autre WordPress SEO plugins avec des fonctionnalités similaires.
Qu'est-ce qu'un tag X-Robots?
La balise Meta des robots convient parfaitement noindex directives sur HTML pages ici et là. Mais que faire si vous voulez empêcher les moteurs de recherche d’indexer des fichiers tels que des images ou des PDF? C'est à ce moment que les balises x-robots entrent en jeu.
Le X-Robots-Tag est un HTTP en-tête envoyé depuis un serveur web. Contrairement à la balise meta robots, elle n’est pas placée dans le HTML de la page. Voici à quoi cela peut ressembler:
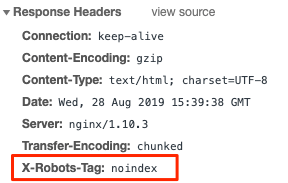
Vérification HTTP les en-têtes est un peu plus compliqué. Vous pouvez le faire à l'ancienne dans le Outils de développement ou utilisez une extension de navigateur telle que ‘Vivre HTTP En-têtes. ’
Le live HTTP En-têtes extension surveille tout HTTP(S) trafic que votre navigateur envoie (en-têtes de demande) et reçoit (en-têtes de réponse). Il est capturé en direct, alors assurez-vous que le plugin est activé. Ensuite, allez à la page ou au fichier que vous souhaitez inspecter et recherchez les journaux dans le plug-in. Cela ressemble à ceci:
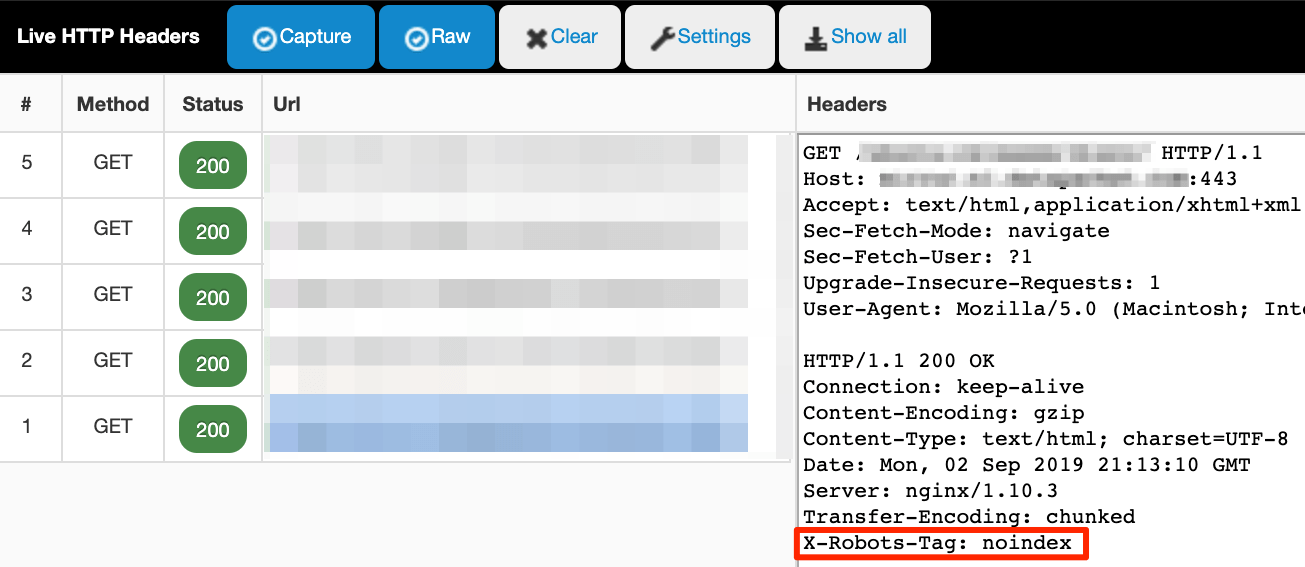
Comment configurer le X-Robots-Tag
La configuration dépend du type de serveur Web que vous utilisez et des pages ou fichiers que vous souhaitez conserver en dehors de l'index.
La ligne de code ressemble à ceci:
Jeu d'en-têtes X-Robots-Tag “noindex”
Cet exemple prend en compte le type de serveur le plus répandu, Apache. Le moyen le plus pratique d’ajouter le HTTP l’en-tête est en modifiant le fichier de configuration principal (généralement httpd.conf) ou .htaccess des dossiers. Sonne familier? C'est l'endroit où redirections arrive aussi.
Vous utilisez les mêmes valeurs et directives pour la balise x-robots en tant que balise meta robots. Cela dit, la mise en œuvre de ces changements devrait être laissée à l'expérimenté. Les sauvegardes sont vos amis car même une petite erreur de syntaxe peut casser tout le site.
PRO POINTE
Si vous utilisez un CDN qui supporte applications sans serveur pour Edge SEO, vous pouvez modifier les balises méta des robots et les balises X ‑ Robots sur le serveur de périphérie sans modifier la base de code sous-jacente.
En ajoutant un HTML snippet ressemble à l'option la plus simple et la plus directe, mais dans certains cas, il est insuffisant.
Fichiers non HTML
Vous ne pouvez pas placer le HTML extrait dans des fichiers non HTML tels que des fichiers PDF ou des images. X-Robots-Tag est le seul moyen.
L’extrait suivant (sur un serveur Apache) configurera noindex HTTP en-têtes sur tous PDF fichiers sur le site.
Jeu d'en-têtes X-Robots-Tag "noindex"
Application de directives à l'échelle
Si vous avez besoin de ne pas indexer un domaine (sous-) domaine complet, un sous-répertoire, des pages avec certains paramètres ou tout autre chose nécessitant une édition en bloc, utilisez x-robots-tags. C'est plus facile.
HTTP Les modifications d'en-tête peuvent être comparées à des URL et à des noms de fichiers à l'aide d'expressions régulières. Édition en vrac complexe dans HTML L'utilisation de la fonction de recherche et de remplacement nécessiterait généralement plus de temps et de puissance de calcul.
Trafic provenant de moteurs de recherche autres que Google
Google prend en charge les balises méta-robots et les balises x-robots, mais ce n'est pas le cas pour tous les moteurs de recherche.
Par exemple, Seznam, un moteur de recherche tchèque ne prend en charge que les balises méta des robots. Si vous souhaitez contrôler la manière dont ce moteur de recherche analyse et indexe vos pages, l'utilisation de balises x-robots ne fonctionnera pas. Vous devez utiliser le HTML extraits.
Comment éviter les erreurs d'analyse et de (dé) indexation
Vous voulez montrer toutes les pages précieuses, éviter dupliquer le contenu, Édite et garde des pages spécifiques en dehors de l’index. Si vous gérez un site Web énorme, budget d'analyse la gestion est une autre chose à laquelle il faut faire attention.
Examinons les erreurs les plus courantes commises par les utilisateurs en ce qui concerne les directives relatives aux robots.
Erreur n ° 1: ajout de directives noindex aux pages interdites dans le fichier robots.txt
Ne refusez jamais l’exploration du contenu que vous essayez de désindexer dans le fichier robots.txt. Cela empêche les moteurs de recherche de redéfinir la page et de découvrir la directive noindex.
Si vous pensez avoir commis cette erreur par le passé, explorez votre site avec Audit du site Ahrefs. Recherchez les pages avec des erreurs «La page Noindex reçoit du trafic organique».
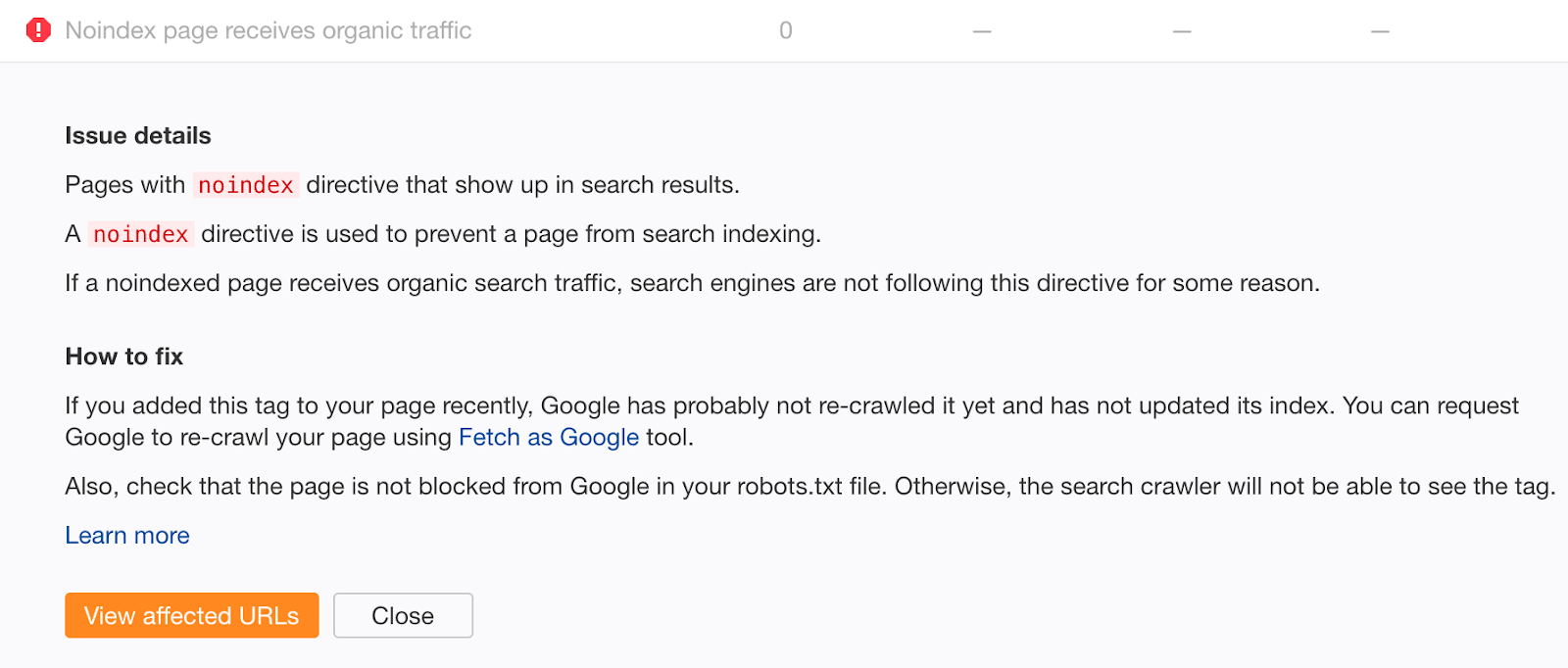
Les pages non indexées qui reçoivent du trafic organique sont clairement toujours indexées. Si vous n'avez pas ajouté la balise noindex récemment, il est probable que cela soit dû à un bloc d'analyse dans votre fichier robots.txt. Recherchez les problèmes et corrigez-les comme il convient.
Erreur # 2: mauvaise gestion des sitemaps
Si vous essayez de désindexer le contenu à l’aide d’une balise meta robots ou x-robots-tag, ne le supprimez pas de votre plan du site jusqu’à ce qu’il soit désindexé avec succès. Dans le cas contraire, il peut être plus lent pour Google de rediriger la page.
@nishanthstephen généralement tout ce que vous mettez dans un sitemap sera récupéré plus tôt – Gary “鯨 理” Illyes (@methode) 13 octobre 2015
Pour potentiellement accélérer davantage le processus de désindexation, définissez la date du dernier modèle dans votre sitemap sur la date à laquelle vous avez ajouté la balise noindex. Cela encourage la réanalyse et le retraitement.
Une autre astuce consiste à envoyer un fichier sitemap avec une date de dernière modification correspondant à la date souhaitée pour encourager la réanalyse. Et retraitement.— 🍌 John (@JohnMu) 16 janvier 2017
Sidenote.
John parle de 404 pages ici. Cela dit, nous partons du principe que cela a également du sens pour d’autres modifications, telles que l’ajout ou la suppression d’une directive noindex.
IMPORTANT REMARQUE
N'incluez pas de pages non indexées dans votre sitemap à long terme. Une fois le contenu désindexé, supprimez-le de votre sitemap.
Si vous craignez que du contenu ancien, désindexé avec succès, subsiste dans votre sitemap, vérifiez l’erreur «Noindex page sitemap» dans Audit du site Ahrefs.
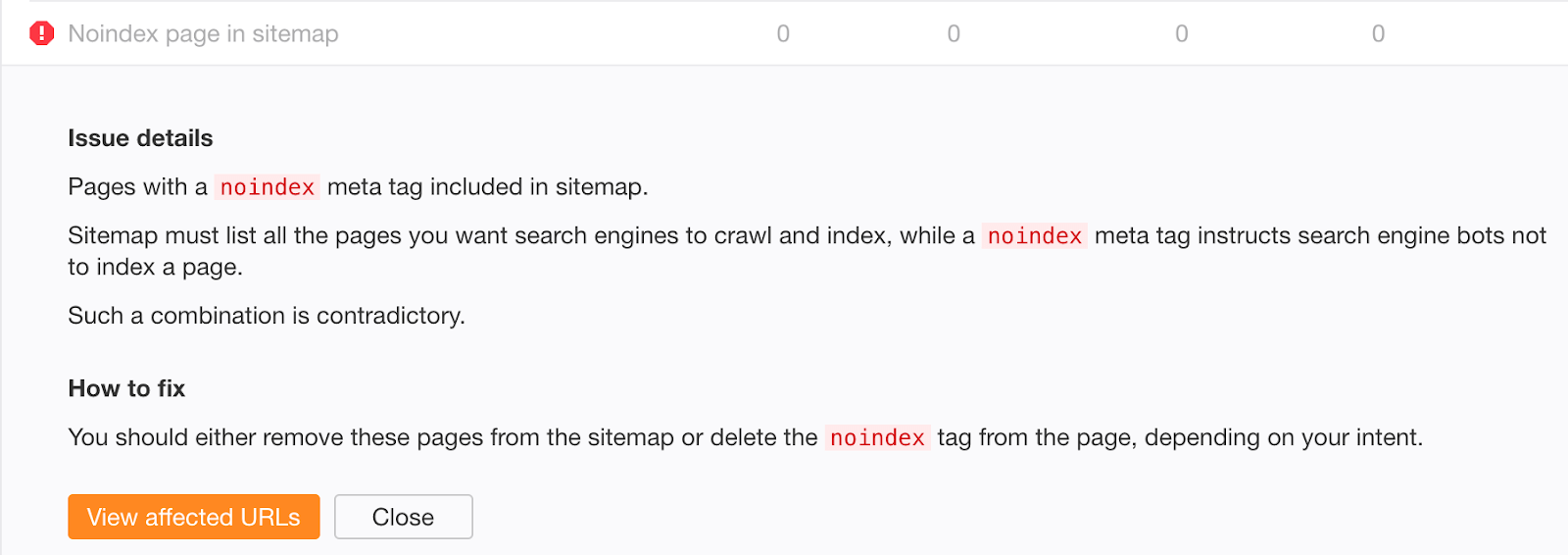
Erreur n ° 3: ne pas supprimer les directives noindex de l'environnement de production
Empêcher les robots d'explorer et d'indexer quoi que ce soit dans l'environnement de transfert est une bonne pratique. Cependant, il arrive parfois que l’on oublie la production et que votre trafic organique plonge.
Pire encore, la baisse de trafic organique pourrait ne pas être perceptible si vous êtes impliqué dans une migration de site en utilisant les redirections 301. Si les nouvelles URL contiennent la directive noindex ou sont interdites dans le fichier robots.txt, vous continuerez à recevoir du trafic organique des anciennes pendant un certain temps. Il faut parfois quelques semaines à Google pour désindexer les anciennes URL.
Lorsque de tels changements se produisent sur votre site Web, gardez un œil sur les avertissements de la “page Noindex” dans Audit du site Ahrefs:
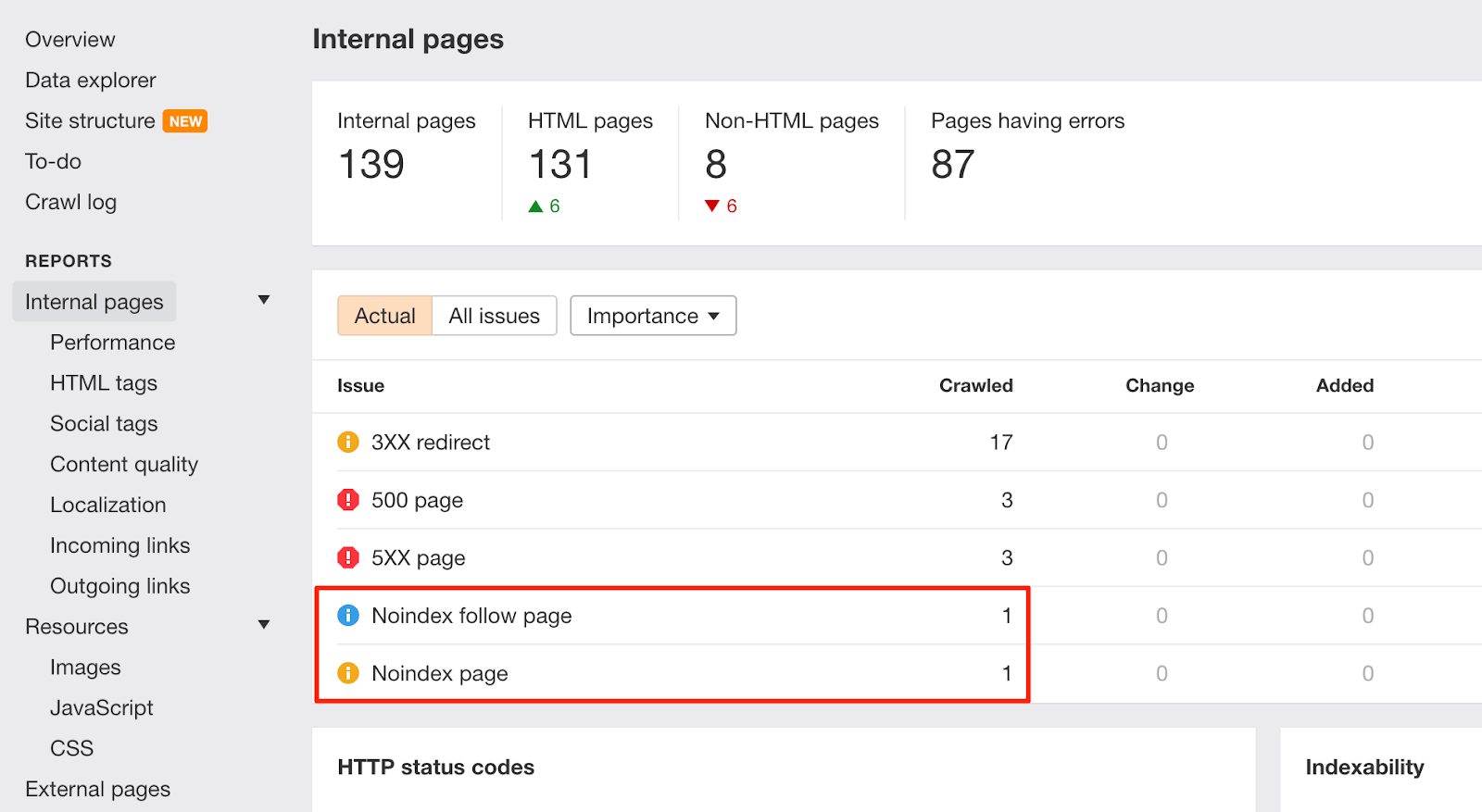
Pour éviter des problèmes similaires à l'avenir, enrichissez la liste de contrôle de l'équipe de développement avec des instructions permettant de supprimer les règles interdites des directives robots.txt et noindex avant de passer en production.
Erreur n ° 4: ajouter des URL «secrètes» à robots.txt au lieu de ne pas les indexer
Les développeurs essaient souvent de masquer les pages concernant les promotions, les remises ou les lancements de produits à venir en interdisant leur accès dans le fichier robots.txt du site. C'est une mauvaise pratique car les humains peuvent toujours afficher un fichier robots.txt. En tant que tels, ces pages sont facilement divulguées.
Corrigez ce problème en gardant les pages «secrètes» en dehors de robots.txt et en ne les indexant pas.
Dernières pensées
Bien comprendre et gérer l’exploration et l’indexation de votre site Web est la pierre angulaire de SEO. Technique SEO Cela peut être assez compliqué, mais les méta-tags des robots ne sont pas à craindre.
J'espère que vous êtes maintenant prêt à appliquer les meilleures pratiques pour des solutions à long terme à grande échelle.
Faites le moi savoir sur Twitter ou dans les commentaires si vous avez des questions.




Comments are closed.