
5 raisons pour lesquelles votre contenu ne sera pas classé

le Yoast SEO plugin vous aide à optimiser facilement le texte de vos publications et pages. Les gens l'utilisent pour essayer d'obtenir un meilleur classement. Mais malheureusement, l’optimisation parfaite de votre publication ne la place pas comme par magie en haut des résultats de recherche. Donc, si votre message parfaitement optimisé n’est pas classé, quel pourrait être le problème? Qu'est-ce qui empêche votre contenu d'atteindre cette position de n ° 1 convoitée? Dans cet article, je traiterai de cinq raisons pour lesquelles le contenu ne se classe pas, même s'il a été optimisé avec le plugin Yoast SEO.
1. Il y a trop de concurrence
Dans la plupart des cas, un poste ne se classe pas parce qu’il ya trop de concurrence. Si vous optimisez votre blogpost pour des mots clés et des phrases clés concurrents, tels que [cat behavior], [robot vacuum cleaner], ou [real estate agent], les chances sont élevées, vous ne serez pas classé pour ce terme.
Pour savoir si tel est le problème, consultez les pages de résultats pour votre mot clé. Les sites de haute autorité, tels que Wikipedia ou Amazon, dominent-ils la première page? Voyez-vous de nombreux sites qui se sont déjà fermement établis dans ce créneau? Les chances sont, votre site n'a pas l'autorité que ces autres sites ont (pour le moment). Vous pouvez donc optimiser tout ce que vous voulez, mais malheureusement, cela ne suffit pas pour figurer en bonne place dans les résultats de recherche si votre créneau est trop compétitif.
Comment le réparer:
Si vous voulez vous classer pour des termes très compétitifs, vous devriez essayer un stratégie de mots clés longue queue. Rédigez des articles de blog qui ciblent des mots clés et expressions connexes avant de vous attaquer à la concurrence mots clés. Si ces articles à longue queue commencent à être classés, vous pourrez également vous classer pour des conditions plus compétitives. Une telle stratégie nécessite des efforts à long terme, mais au final, elle portera ses fruits.
Lire la suite: Pourquoi devriez-vous vous concentrer sur les mots clés à longue queue »
2. Votre site a des problèmes techniques
Si votre message n’apparaît pas du tout dans les moteurs de recherche, des problèmes techniques pourraient l’empêcher de figurer dans les résultats de recherche. Des plug-ins en conflit peuvent être à l'origine de problèmes. Nous avons également constaté que certains thèmes empêchent Google d'indexer votre site. Et tandis que Yoast SEO prend en charge de nombreux problèmes techniques sous le capot, il devrait être réglé correctement pour le faire correctement.
Si vous vous classiez bien avant, mais que vous avez soudainement disparu des résultats de la recherche, examinez la sécurité de votre site et assurez-vous de ne pas piraté! Si un site est piraté, le contenu existant diminuera également. Les nouveaux messages ne seront plus aussi facilement classés qu’avant. Tout cela évoluera plutôt lentement, en fonction de la quantité de merde publiée sur votre site, sans que vous le sachiez. Dans la plupart des cas, se faire pirater n’est probablement pas la cause de problèmes de classement. Mais si vous êtes certain qu'aucun des autres problèmes ne concerne votre site, il peut être intéressant de s'y intéresser. Bien sûr, c’est toujours une bonne idée de vous assurer que votre sécurité est au top!
Comment le réparer:
Premièrement, assurez-vous que Yoast SEO est bien configuré correctement. Dans la première étape de l'assistant de configuration Yoast on vous demande si votre site est prêt à être indexé. Si vous répondez «non» et oubliez de le remplacer par «oui» plus tard, votre contenu n’apparaîtra pas dans les résultats de la recherche! Mais si tel est le cas, vous verrez un avertissement dans votre tableau de bord général Yoast SEO, ce qui en facilite la vérification. Pour les articles et les pages individuels qui ne sont pas classés: cochez la case "Avancé" dans la métaboxe Yoast située sous l'article. si les moteurs de recherche sont effectivement autorisés à afficher la publication dans les résultats. N'oubliez pas que, une fois que vous avez modifié un paramètre afin de permettre aux moteurs de recherche d'indexer votre contenu, il peut s'écouler un certain temps avant qu'il ne soit visible.
Si les paramètres de votre plug-in Yoast sont tous corrects, il est temps de creuser davantage. Vérifiez vos plugins et / ou votre thème et assurez-vous que votre sécurité est en ordre!
3. Votre site n’a pas de structure de liens interne appropriée
Une autre raison pour laquelle votre contenu ne figure pas dans les résultats de recherche: un élément crucial de votre stratégie de référencement n’est pas en ordre. Ne sous-estimez pas l’importance de la structure du site – la structure de liaison interne – pour votre stratégie de référencement. Avoir une structure de site claire conduit à une meilleure compréhension de votre site par Google. Si votre structure de liaison interne est faible, les chances de classement élevé sont plus faibles – même lorsque votre contenu est bien optimisé et génial.
Comment le réparer:
Commencez à ajouter ces liens! Assurez-vous que votre important les articles et les pages contiennent le plus de liens internes. Mais n’ajoutez pas de liens au hasard: assurez-vous d’ajouter liens pertinents et connexes qui ajoutent de la valeur pour vos utilisateurs.
Vous pouvez utiliser le Filtre de contenu orphelin Yoast SEO pour trouver des publications sans liens internes entrants. Yoast SEO premium vous aidera encore plus en offrant des suggestions de liens utiles au fur et à mesure que vous écrivez. Et si vous voulez vraiment améliorer la structure de votre site, consultez notre formation sur la structure du site!
Continuer à lire: Structure du site: le guide ultime »
4. Il y a peu de backlinks sur votre site
Si vous venez de commencer avec votre site Web, votre contenu ne sera pas instantanément classé. Même si chaque page est optimisée à la perfection et que chaque puce de Yoast SEO est verte. Pour pouvoir classer, vous aurez besoin de liens provenant d’autres sites. Après tout, Google doit savoir que votre site Web existe.
Comment le réparer:
Pour obtenir plus de backlinks, vous pouvez accéder à d'autres sites Web. Vous devrez faire des relations publiques ou renforcement des liens. Demandez-leur de mentionner votre site ou de parler de votre produit et de créer un lien vers votre site. Vous pouvez aussi utiliser des médias sociaux pour faire passer le mot! Apprenez tout sur les stratégies de création de liens dans notre Entièrement SEO formation!
5. Vous ciblez le mauvais type d'intention
Une dernière chose qui pourrait être la raison pour laquelle votre contenu ne figure pas dans le classement: cela ne correspond pas à l’intention des personnes qui recherchent votre mot clé. Intention de recherche est en train de devenir un facteur de plus en plus important pour les moteurs de recherche: est-ce que les gens veulent acheter quelque chose, aller sur un site web spécifique ou cherchent-ils des informations? Même si vous ciblez une phrase clé plus longue, si votre contenu ne correspond pas à l’intention dominante des chercheurs, les probabilités sont que les moteurs de recherche ne l’afficheront pas dans les résultats, car ce ne sera pas ce que les gens recherchent.
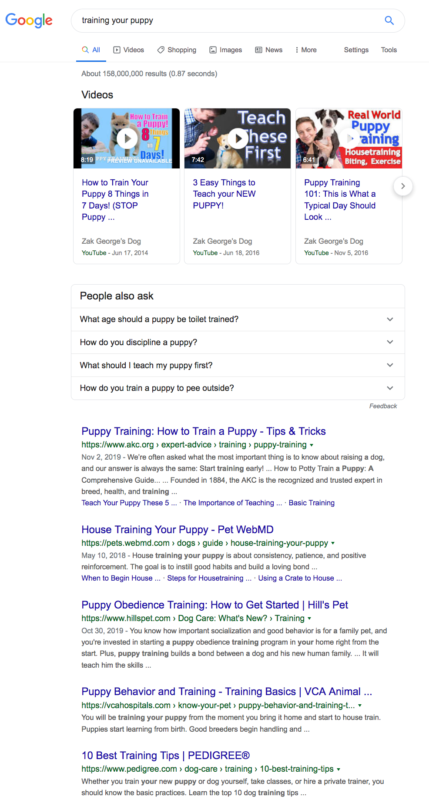
Voyons quelques exemples. Imaginons que vous soyez un dresseur de chiens qui souhaite se classer parmi les services de dressage de chiots. [training your puppy], avec l’intention transactionnelle à l’esprit. Mais si vous regardez les résultats de la recherche, vous verrez qu'il y a des vidéos d'information, et tous les résultats expliquent comment former un chiot vous-même. Donc, les chercheurs ont en réalité une intention informationnelle. Cela peut aussi fonctionner dans l'autre sens. Si vous avez rédigé pour votre blog un guide détaillé sur la création de votre propre décoration de jardin, cherchez à le classer [flower garland garden decoration], vous aurez peut-être du mal à classer ce terme si les gens veulent simplement l’acheter, pas le faire eux-mêmes.
À présent, il convient de noter que tous les termes de recherche n’ont pas un type d’intention dominant. En outre, il n’est pas impossible de classer le contenu avec des intentions différentes. Néanmoins, il peut être intéressant d’examiner cette question si votre contenu optimisé ne figure pas dans les moteurs de recherche.
Comment le réparer:
Malheureusement, vous n’avez pas le pouvoir de changer l’intention des utilisateurs des moteurs de recherche. Mais toi pouvez adaptez votre stratégie de contenu. Si votre contenu optimisé ne fait pas l'objet d'un classement, examinez bien les résultats de la recherche (de préférence en mode privé) et analysez ce que vous voyez. Un type spécifique de résultat est-il dominant? Y a-t-il des images ou des vidéos? Quelles requêtes connexes sont affichées? C'est là que sont vos opportunités. Si vous trouvez principalement une intention d’information pour une requête, vous pouvez rédiger un contenu à ce sujet pour amener les internautes sur votre site, faire de votre marque une source fiable d’informations et garder la priorité sur l’esprit lorsque des internautes souhaitent acheter. Si vous trouvez beaucoup d’images dans les résultats de la recherche, vous devrez peut-être vous concentrer davantage sur image SEO. Prenez ce que vous voyez sur les pages de résultats
Contenu optimisé non classé?
Plusieurs raisons peuvent empêcher un poste de se classer. Si vous l'avez optimisé correctement avec Yoast SEO, la cause la plus commune sera certainement que la concurrence dans un créneau est trop féroce. Malheureusement, le référencement est une stratégie à long terme. Vous devez travailler dur et être patient. Entre-temps, il existe de nombreux autres aspects de votre référencement (structure de site, création de liens) auxquels vous pouvez vous attaquer. Essayez de vous concentrer sur tous les aspects de l'optimisation du site Web, essayez de être ce meilleur résultat. Cela finira par payer!
Source link

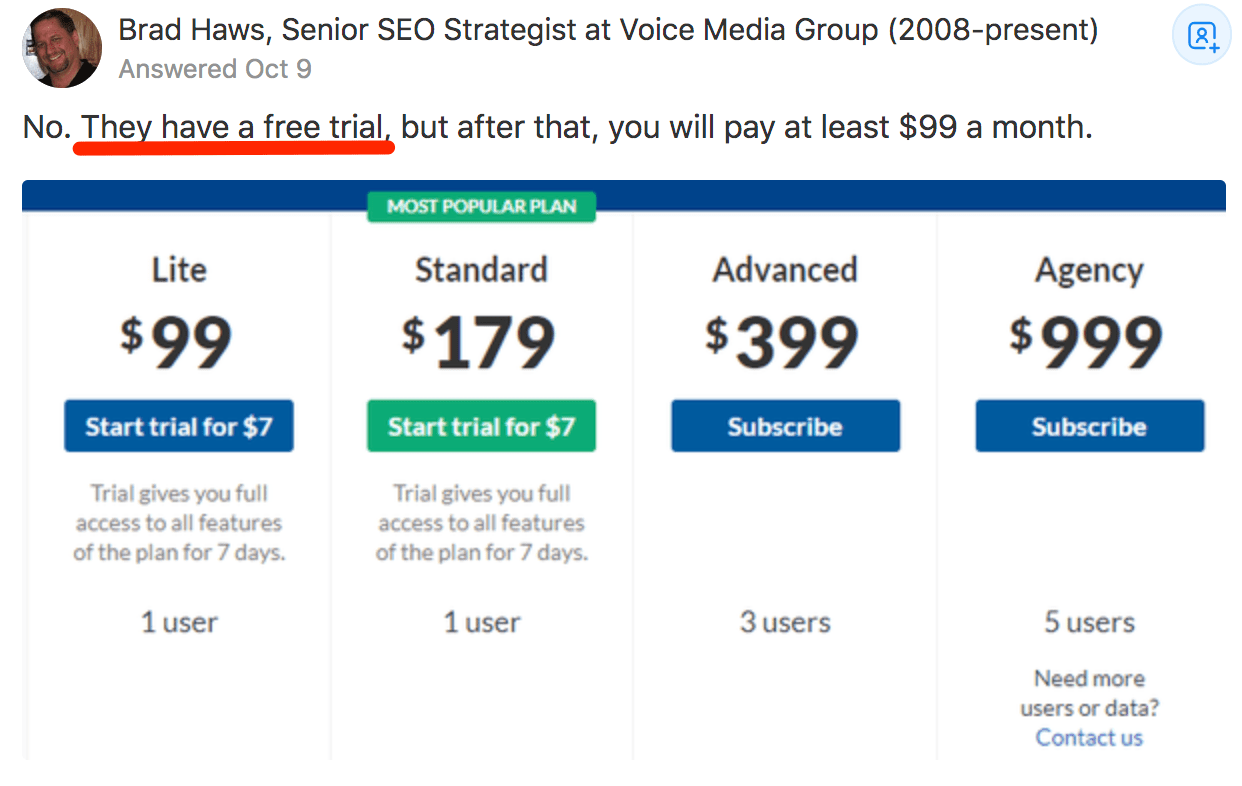
~ 1 million de vues générées. Voici comment reproduire notre succès
Essayez-vous de commercialiser sur Quora sans obtenir les vues et le trafic que vous souhaitez? Vous êtes au bon endroit.
Depuis juillet 2018, je suis actif sur Quora, répondant à au moins cinq questions par semaine sur des sujets liés à Ahrefs, SEOet le marketing numérique. Pendant ce temps, j’ai accumulé des centaines de milliers de vues.
Avant de commencer mon voyage sur Quora, je me suis tourné vers Google pour obtenir de l'aide. Malheureusement, la plupart des guides étaient terribles. Ils ont été écrits par des écrivains qui n’avaient que peu d’expérience sur la plate-forme et qui devaient repasser les conseils d’ailleurs.
J'ai ensuite décidé d'étudier des écrivains populaires sur Quora. Ce que j'ai remarqué, c'est que la plupart d'entre eux répondaient à des questions portant sur les mêmes sujets: conseils de vie, développement personnel et entrepreneuriat.
Avec ces sujets, même une simple liste peut obtenir des dizaines de milliers de vues.
Par contre, les réponses dans mon créneau n’en ont pas autant.
Néanmoins, j'ai décidé de commencer à rédiger des réponses et à comprendre les choses en cours de route.
Dans cet article, je partagerai avec vous tout ce que j’ai appris jusqu’à présent. J’ai également invité mon ami Jason Thibault, fondateur de MassiveKontent, pour partager quelques conseils. Jason a commencé à publier sur Quora en novembre 2018 et a depuis beaucoup expérimenté avec la plate-forme.
Mais avant de commencer, parlons des raisons pour lesquelles nous sommes sur Quora.
Facebook, Instagram, Twitter, LinkedIn, Reddit, Snapchat, Quora et maintenant TikTok. Soyons honnêtes: l’un des plus grands défis des entreprises est de savoir quel canal social utiliser réellement donner la priorité.
Plutôt que de vous convaincre d’être sur Quora (ce qui ne convient pas à tout le monde), j’aimerais partager les raisons de notre décision. Si vous êtes en résonance avec l'un d'entre eux, vous pouvez envisager sérieusement la plate-forme.
1. Soutenir les clients existants et potentiels
Au fur et à mesure que la marque Ahrefs grandit et que notre portée s’élargit, de plus en plus de gens commencent à reconnaître notre nom mais ne savent pas exactement ce que nous faisons. Ou ils pourraient être dans la phase de "considération" de la voyage de l'acheteur et essayons de comparer différentes solutions sur le marché.
Généralement, ces personnes se tournent vers des plateformes ou des forums tiers, tels que Quora, pour poser des questions.
Si nous n’y sommes pas, les Quorans pourraient répondre de manière inexacte aux questions relatives à Ahrefs.
Il est essentiel pour nous de participer afin de pouvoir répondre à ces questions de manière honnête et factuelle.
2. Faire appel à un nouveau et vaste public
Fait amusant: Quora a un audience de 300 millions d'utilisateurs uniques par mois.
Cela place Quora parmi les réseaux sociaux tels que Twitter (335 millions d'utilisateurs actifs par mois), Reddit (330 millions d'utilisateurs actifs par mois) et Pinterest (250 millions d'utilisateurs actifs par mois).
Vos réponses peuvent atteindre un nouveau public qui ne connaît peut-être pas encore votre marque.
3. Générer du trafic de référence à partir de réponses populaires
Quora compte environ 65 millions de mots-clés et reçoit environ 90 millions de visites de recherche par mois.

Si vous pouvez trouver les questions qui se classent bien sur Google et y répondre, vous pouvez générer du trafic de parrainage vers votre site Web (pour plus d'informations à ce sujet plus tard!)
4. Construisez votre marque personnelle
Jimmy Daly, directeur du marketing chez Animalz, a écrit que les marques personnelles sont l'un des plus importants canaux de promotion de contenu.
Les membres d’équipe influents ont le potentiel et le pouvoir d’amplifier la portée de votre contenu. Ceci est vrai pour nous à Ahrefs. Quand Tim, notre CMO partage nos articles sur Twitter:
👊SEO contre. PPC 👊https://t.co/jQg3CGFIzG
^^ Un très bon aperçu de l'ancien dilemme de notre propre chef @siquanong
S'il vous plaît laissez-nous savoir si nous avons oublié de couvrir un argument important. – Tim Soulo (@timsoulo) 30 août 2019
Il obtient généralement plus de portée que notre compte marque:
✍️SEO contre. PPC: Lequel devriez-vous utiliser? par @siquanong
Luttant pour décider si vous devriez investir dans SEO ou PPC? 📈
🔽 Vous êtes au bon endroit!https://t.co/eSontQhbnM– Ahrefs (@ahrefs) 4 septembre 2019
Qu'est-ce que cela signifie en ce qui concerne Quora?
Être actif sur cette plate-forme signifie que vous avez une chance de faire preuve d'un leadership éclairé, de démontrer votre expertise et de développer votre marque personnelle. Vous pouvez également diriger vos abonnés sur Quora vers vos autres comptes sociaux, renforçant ainsi votre présence sur plusieurs plates-formes.
Ceci est inestimable pour la promotion des travaux futurs.
Maintenant que vous avez compris à quel point la participation à Quora peut être intéressante, voyons comment bien le faire sur cette Q unique.EtUne plateforme.
1. Créer une bonne bio
Les gens même cliquez sur votre biographie et découvrez ce que vous faites?
Pour le savoir, j'ai changé le lien dans ma bio Quora d'un lien direct à un lien bit.ly. Cela m'a permis de suivre le nombre de clics que je recevais.
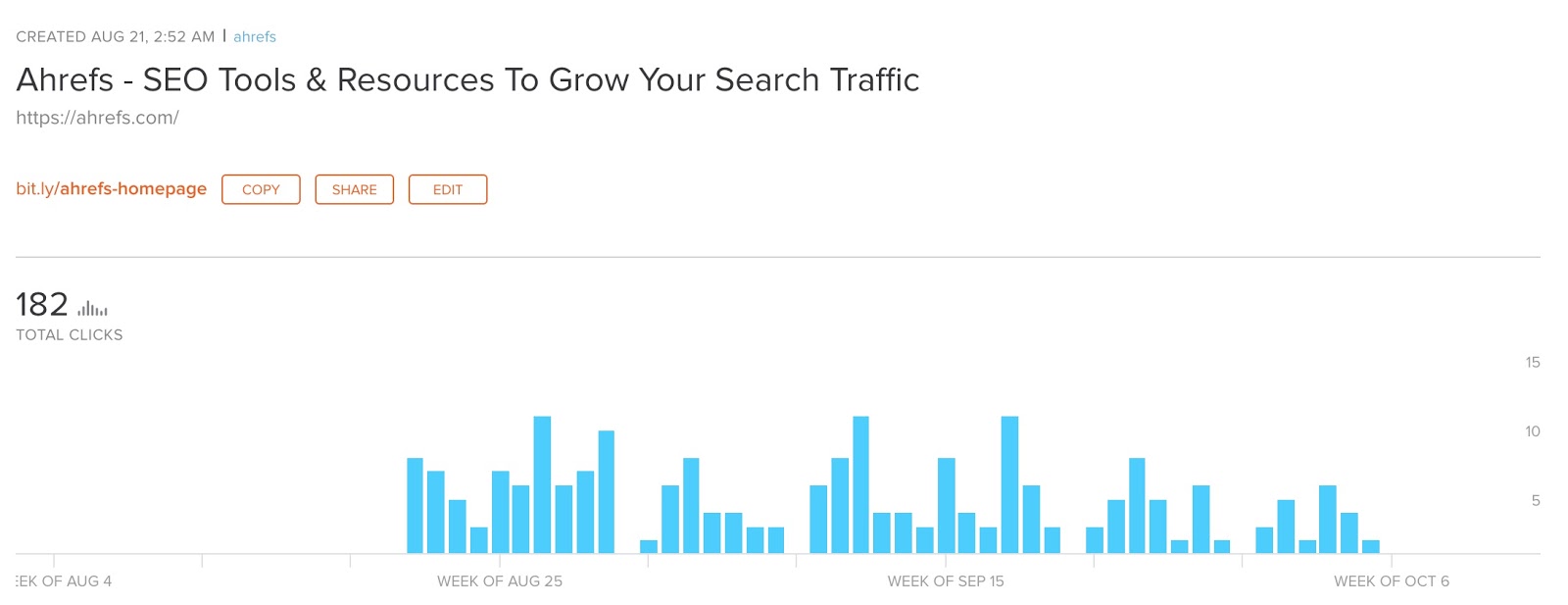
En environ trois mois, j'ai eu 182 clics.
Pas incroyable, mais pas trop mal non plus. On dirait des gens faire consultez votre biographie si elle aime ce que vous faites.
Voici comment ma biographie se lit:
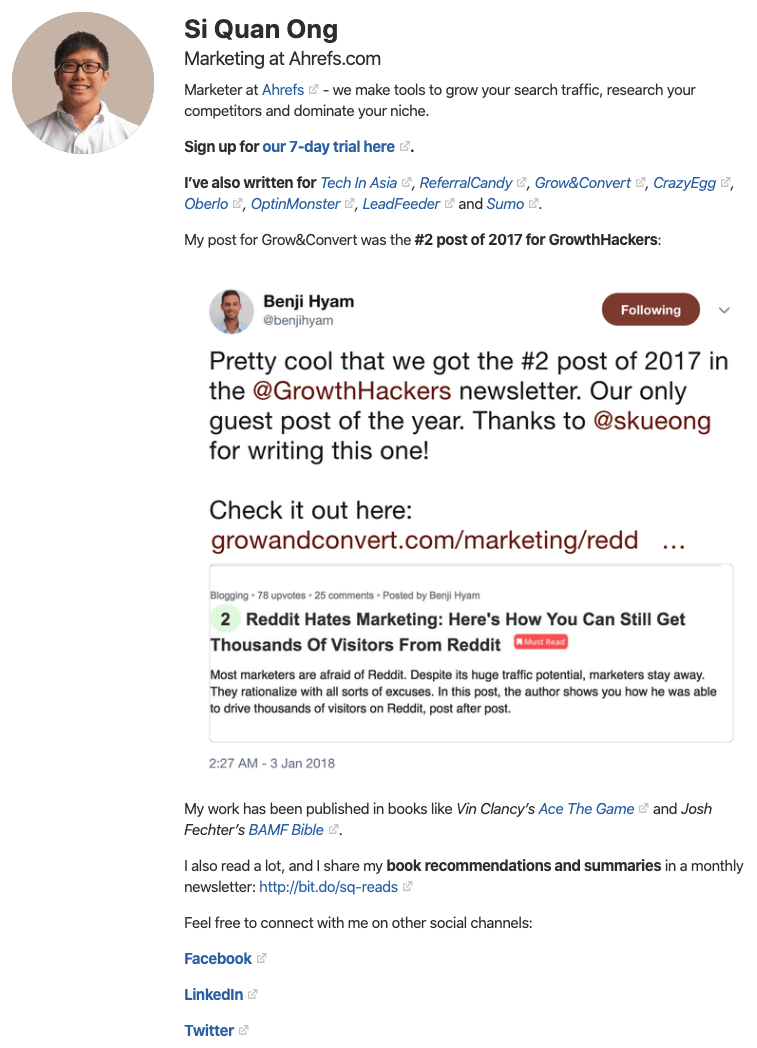
Soyons le décomposer.
- Je me présente et ce que je fais. Cela aide à établir mon expertise et ma crédibilité.
- J'ajoute un appel à l'action (CTA), qui est un lien pour vous inscrire à notre essai.
- Je montre la preuve sociale pour ajouter encore plus de crédibilité à la notion que je suis un expert en la matière.
Enfin, j'ajoute quelques liens à mes comptes sociaux, encourageant mes suiveurs de Quora à me suivre ailleurs:
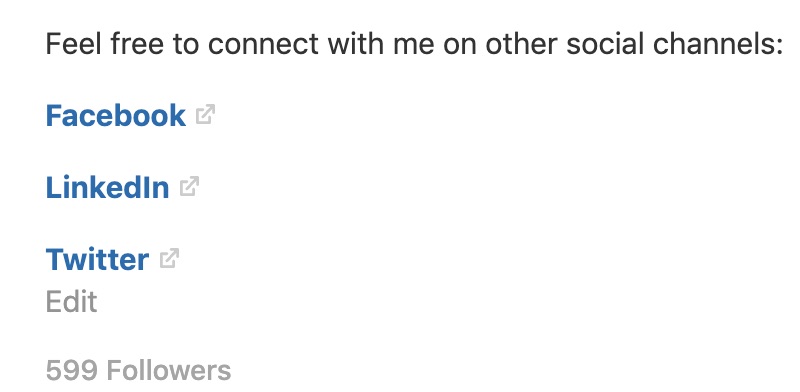
Il n’ya pas de bonne façon d’écrire une bonne biographie. N'hésitez pas à expérimenter et à comprendre ce qui fonctionne pour vous. Je vous encouragerai également à jeter un regard sur ce que font les meilleurs écrivains de votre créneau et de Quora.
2. Identifier les bonnes questions
Principe de Pareto suggère que seulement ~ 20% des questions auxquelles vous pourriez répondre sur Quora vous enverront effectivement du trafic.
Alors, comment trouvez-vous ces questions?
Voici quelques idées:
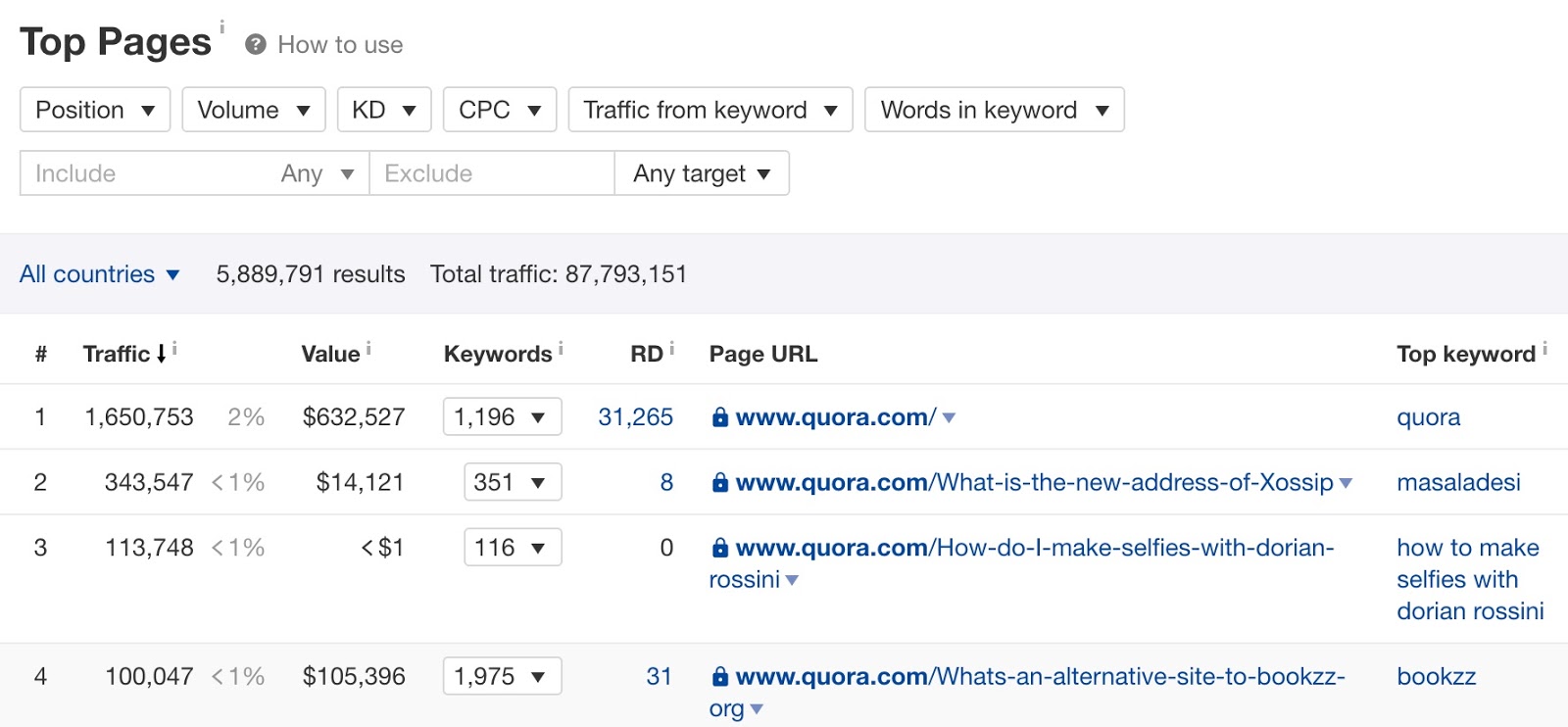
A. Trouvez des questions qui génèrent du trafic de recherche organique
Entrer quora.com dans Ahrefs ’Site Exploreret allez au rapport «Top pages». Cela montre les pages de Quora qui reçoivent le trafic de recherche le plus organique.
Pour affiner la liste, entrez un mot ou une phrase pertinent dans la case «Inclure». Cliquez sur le curseur à côté de chaque page URL pour voir le trafic organique mensuel total estimé sur la page.
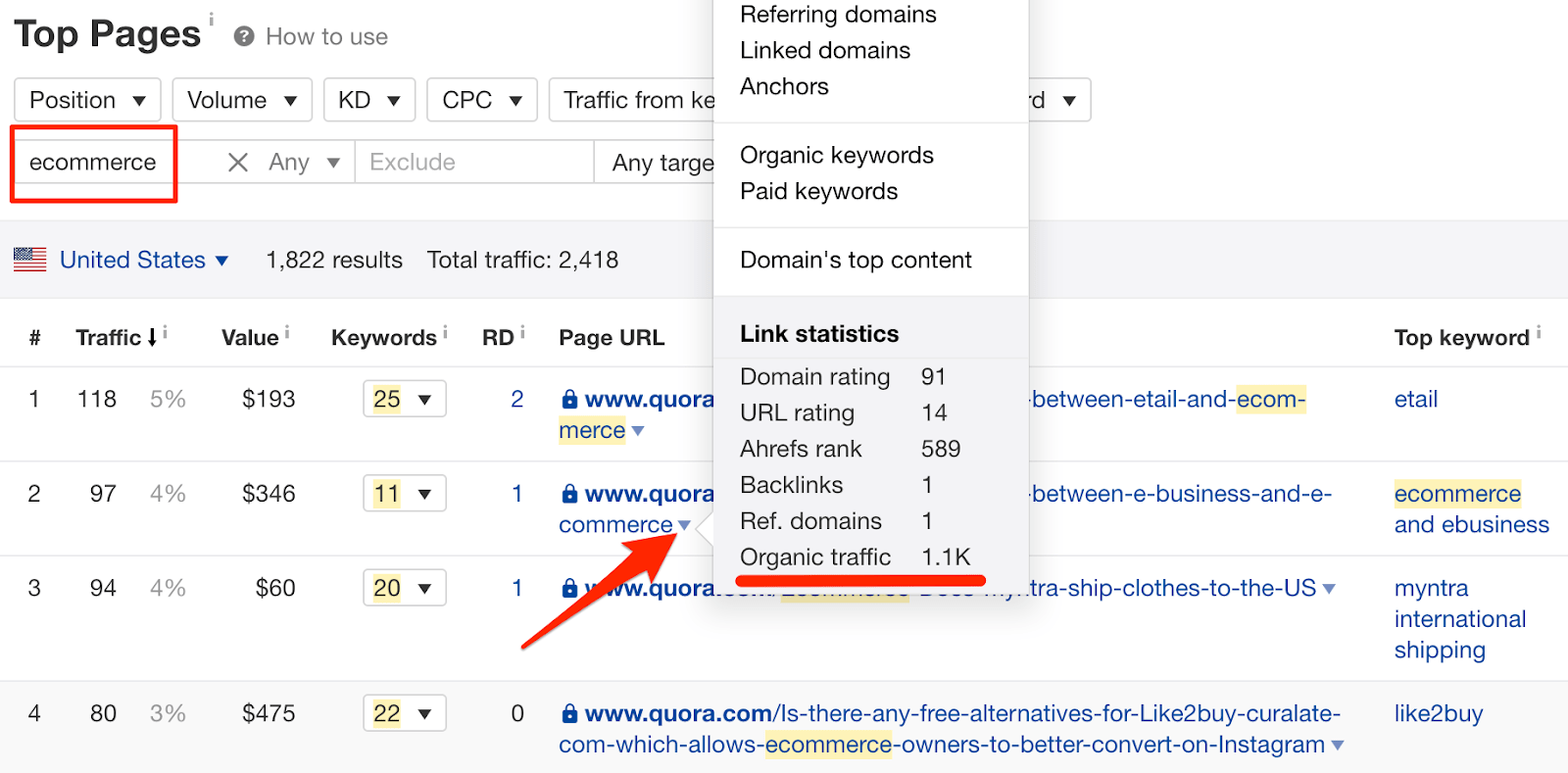
Parcourez la liste et répondez aux questions pertinentes pour votre entreprise.
B. Quora Ads "Hack"
Il est facile de dire combien de fois une question a été vue:
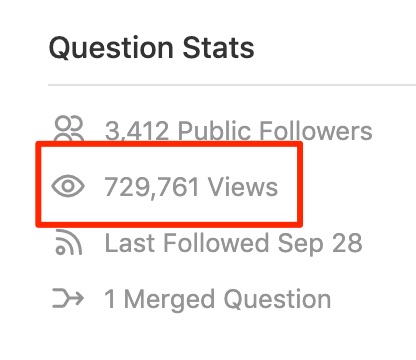
Malheureusement, cette connaissance n'est qu'à moitié utile. Il est parfois vrai que la question était populaire il y a longtemps (par exemple, en 2013), a suscité des tonnes de points de vue et a perdu de son attrait après.
Une mesure plus utile serait le nombre de points de vue que la question est encore recevoir aujourd'hui.
Le problème, cependant, est que Quora ne l’affiche pas explicitement.
Il y a un moyen de contourner cela. Pour aider les annonceurs à comprendre sur quoi ils doivent faire de la publicité, Quora leur indique le nombre de vues hebdomadaires pour des questions pertinentes.
Nous pouvons utiliser cela à notre avantage. Aller à votre Gestionnaire de Quora Ads. Cliquez sur "Créer une campagne".

Sidenote.
Vous devrez configurer votre compte d'annonces Quora si vous ne l'avez pas encore. Ne vous inquiétez pas nous ne dépenserons pas d’argent.
Il vous sera demandé de renseigner les détails de votre campagne. Puisque nous ne sommes intéressés que par la suite, n'hésitez pas à insérer des informations aléatoires ici.
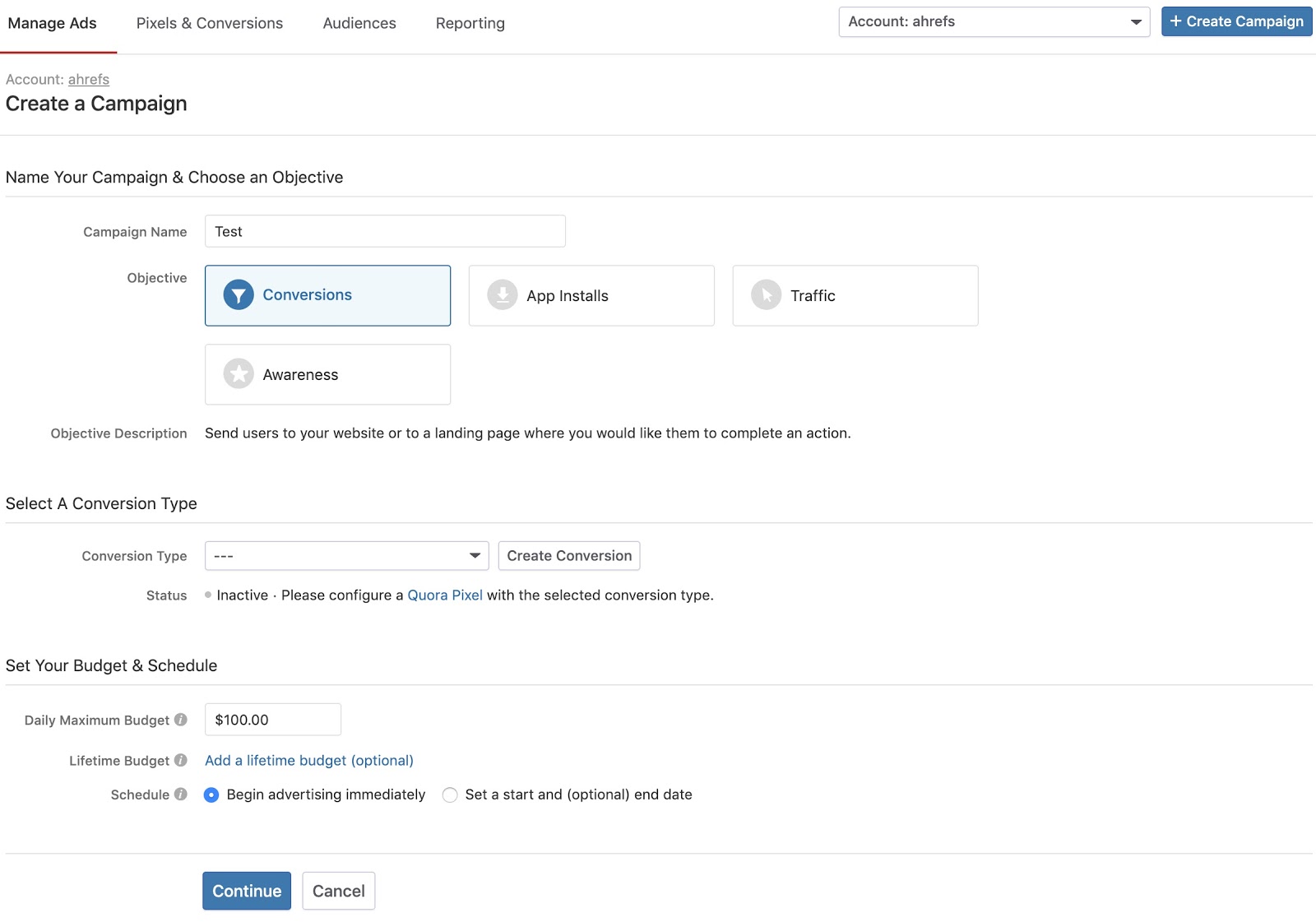
Cliquez sur «Continuer» pour passer à la page suivante. C'est là que commence le plaisir.
Sous «Ciblage primaire», choisissez «Ciblage contextuel», puis «Questions». Ensuite, cliquez sur «Ajout en masse».
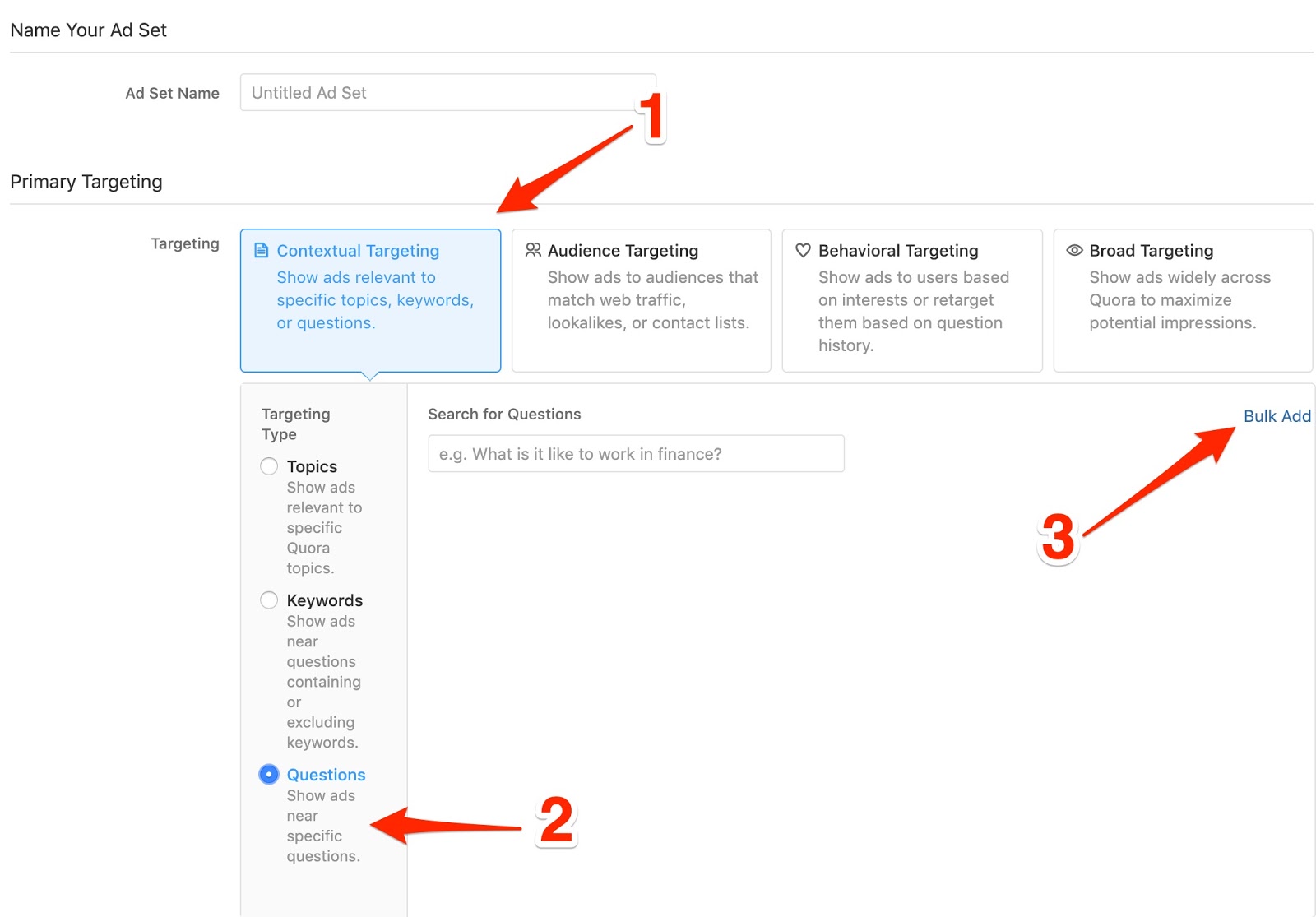
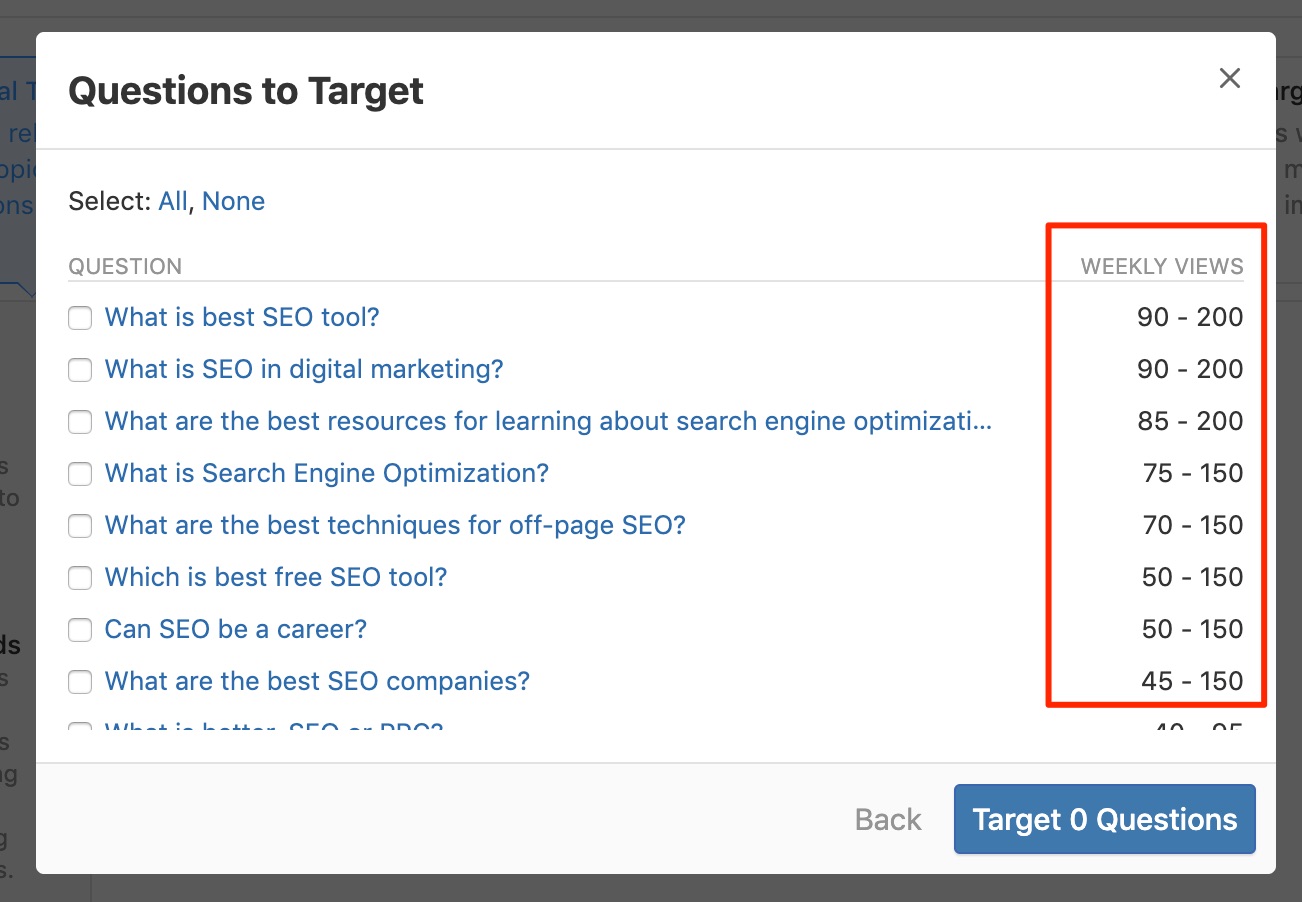
Tapez n'importe quel mot clé pertinent et Quora suggérera des questions à répondre et indiquera le nombre de vues hebdomadaires.
C. Écrivains les plus visités
Je n’avais jamais vu personne mentionner ce «bidouillage» auparavant, alors j’ai pensé que je suis la première personne à l’avoir inventé. #humblebrag
Voici comment ça se passe.
Recherchez un sujet pertinent («Optimisation du moteur de recherche», par exemple) sur Quora. Cliquez sur «Écrivains les plus consultés».
Que vois-tu? Il est probable que certains auteurs obtiennent un nombre de vues disproportionné, même s’ils ne répondent qu’à quelques questions.
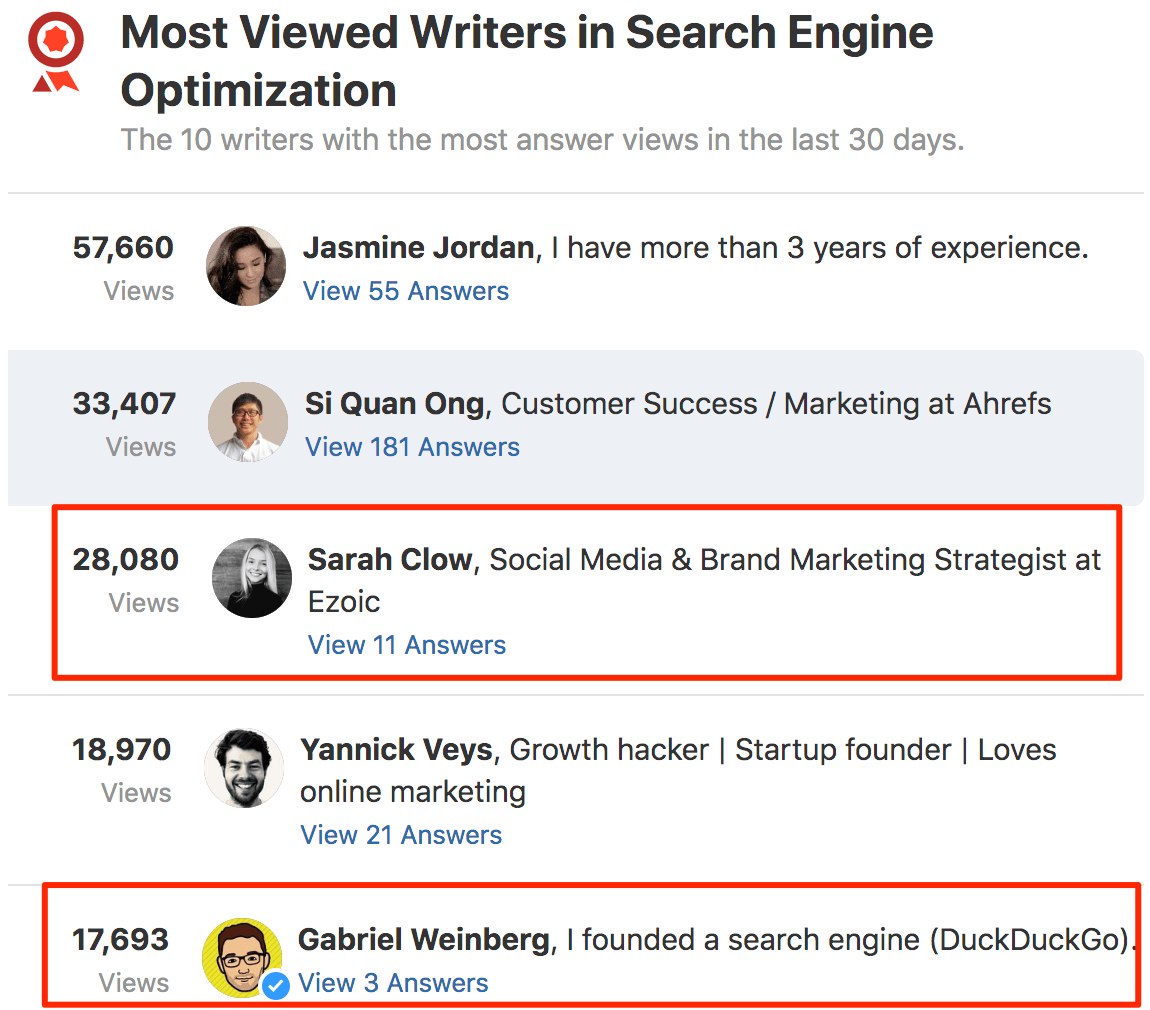
Comme Quora vous dit quelles sont ces questions, vous pouvez y répondre et essayer de reproduire leur succès.
Par exemple, je vais vérifier Sarah Clow, car elle a réussi à accumuler environ 28 000 vues en seulement 11 réponses.
Les yeux dans les yeux révèlent que cette question lui a été transmise:
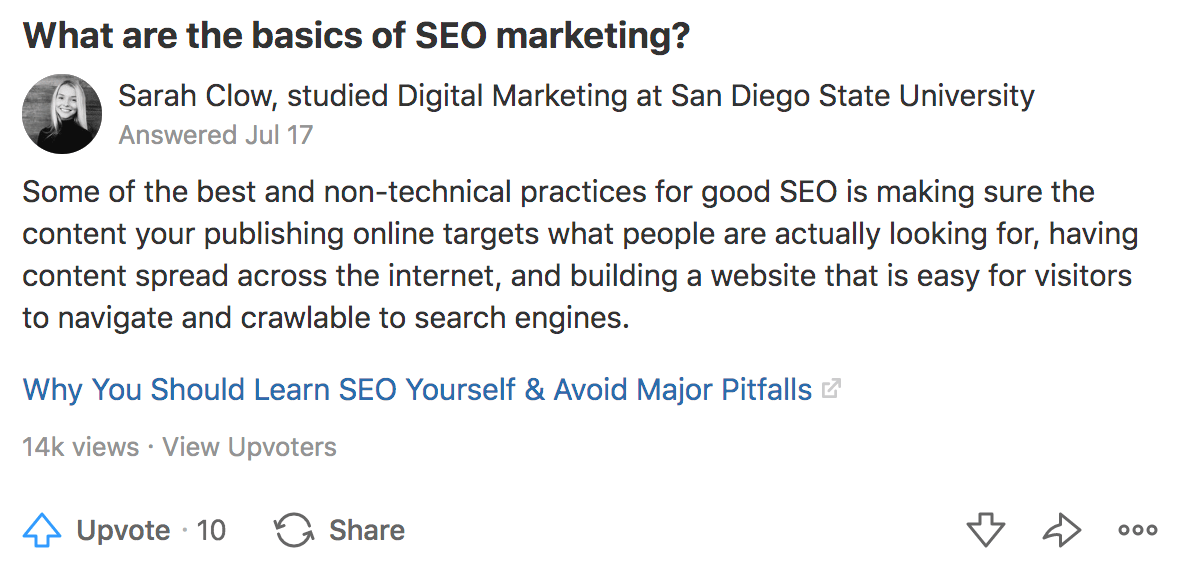
Cette question gagne probablement du terrain et attire l'attention des auteurs de Quora. Puisque la réponse laisse beaucoup à désirer, vous pouvez facilement en écrire une meilleure et essayer de reproduire ses résultats.
D. Suivez l'algorithme Quora
Au fur et à mesure que vous répondez, Quora commencera à vous recommander de nouvelles questions et sujets. Celles-ci apparaissent généralement dans votre onglet "Réponse":
Vous pouvez également vérifier les questions qui apparaissent en haut des flux de sujets:
Ces questions sont probablement populaires dans l'écosystème de Quora et vos réponses peuvent recevoir des milliers de points de vue.
3. Questions de priorité
Certaines questions peuvent générer beaucoup de trafic organique mais sont très compétitives (beaucoup de réponses).

Même si le potentiel de trafic est élevé, il vous sera peut-être impossible de vous démarquer. En tant que tel, vous devrez définir des priorités.
Comment?
Voici quelques idées:
A. Recherchez les questions auxquelles vous connaissez la réponse
Écrire sur Quora est une perte de temps, il est donc utile de concentrer votre temps et votre énergie sur des questions pour lesquelles vous connaissez déjà la réponse. Cela réduit le temps passé à écrire.
Si vous souhaitez aller encore plus loin dans cette idée, recherchez des questions similaires dans les articles de blog déjà écrits. De cette façon, vous pouvez réutiliser le contenu et rédiger des réponses utiles et détaillées très rapidement.
Par exemple, je me suis recyclé notre article sur le temps qu'il faut pour se classer sur Google:
![]()
![]()
![]()
B. Sélectionner des questions basées sur des données
Après avoir utilisé l'une des méthodes ci-dessus pour rechercher des questions potentielles, vous devez avoir un ensemble d'URL. Collez ces URL dans Analyse par lots d’Ahrefs pour saisir l'important SEO métrique.
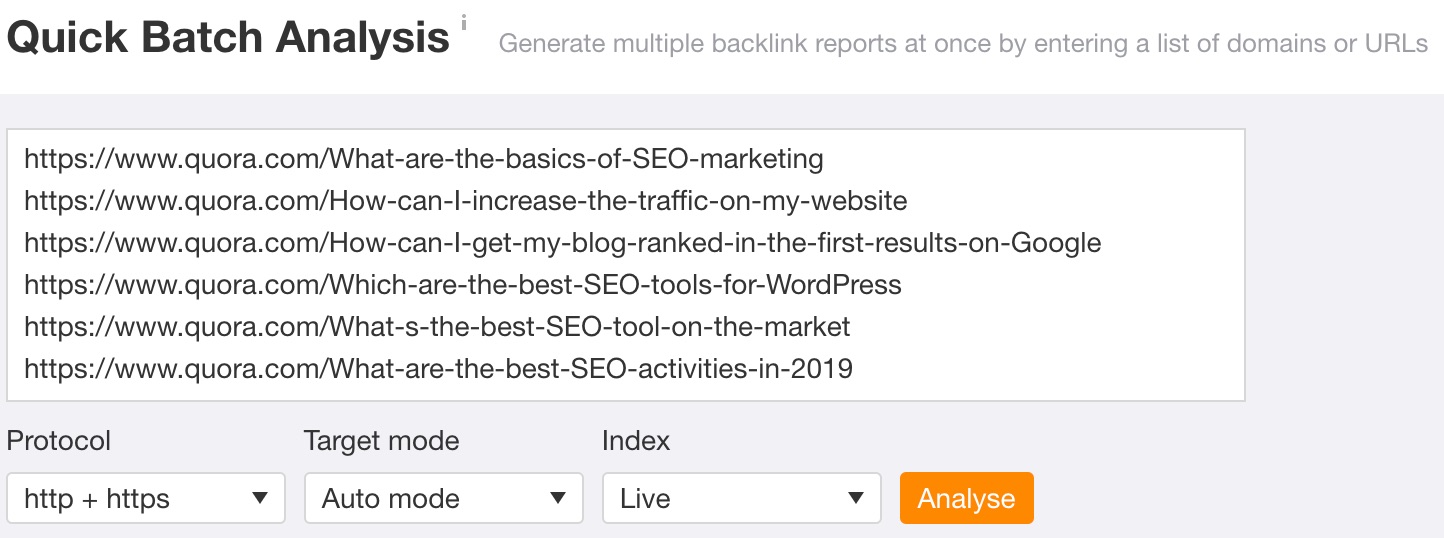
Ensuite, mettez ces URL Quora dans Grenouille hurlante et utilisez l'extraction personnalisée pour saisir des données pertinentes, telles que le nombre de personnes ayant répondu aux questions, les liens avec des concurrents, etc.

Voici le code Regex:
Et le code XPath: //une[contains(@href,'example1.com') or contains(@href,'example2.com')]/ @ href
Sidenote.
N'oubliez pas d'activer le rendu JavaScript pour que Screaming Frog puisse gratter Quora.
À partir de là, vous pourrez hiérarchiser les bonnes questions à répondre en fonction des données que vous avez acquises.
Astuce Pro
Screaming Frog générera également un rapport sur les liens externes rompus pour ces réponses à Quora.
Attaquez-les en faisant une Édition suggérée. Demandez à l'auteur d'envisager de remplacer les liens rompus par un lien vers votre contenu.
4. Répondre aux questions
Pour réussir sur Quora, vous avez également besoin de bonnes réponses qui apportent de la valeur.
Il n'y a pas de manière "magique" de vous apprendre à écrire une bonne réponse. Il n'y a pas de «bidouille» qui dit «écris XYZ phrase "ou" écrire dans abc format ”pour gagner en traction.
Écrire une réponse valable à Quora revient à acquérir de grandes compétences en rédaction. Cela prend de la pratique.
Heureusement, des formules de rédaction existent. Ils peuvent servir de guide de formation et de structure pour vous aider à rédiger une bonne réponse.
J'utilise souvent le AIDA formule.
- UNEttention: capturer leur attention avec quelque chose de accrocheur ou pertinent.
- jeIntérêt: racontez-leur des faits intéressants, des utilisations, des exemples ou des histoires.
- réesire: Faites-leur désirer le produit / service / etc.
- UNEction: Amenez-les à agir.
Par exemple:

Ce guide explique plus sur le AIDA formule. Si vous êtes intéressé par d’autres formules de rédaction, voici un exemple. liste exceptionnelle.
Si vous souhaitez apprendre le copywriting, voici quelques livres que j'ai appris et dont j'ai bénéficié:
Quelques autres conseils pour bien répondre aux questions:
1. Attirer l'attention avec une phrase d'introduction et une image fortes
Le légendaire rédacteur Joseph Sugarman a un axiome qui suit:
La première phrase d'une publicité a pour seul but de vous faire lire la deuxième phrase de la copie.
Par défaut, Quora affiche un aperçu des 200 premiers caractères de votre réponse, ainsi qu'une image.
Si vous voulez que les gens cliquent sur "Plus", vous devez faire en sorte que l'image et la première phrase comptent.
Sidenote.
Si vous publiez une vidéo YouTube dans votre réponse, elle remplace automatiquement votre image par la vignette par défaut.
2. Vérifiez les autres réponses pour comprendre ce que les gens veulent
Jetez un oeil à cette question:
À la surface, vous pouvez supposer que les Quorans recherchent une liste d’exemples. Droite?
Faux.
Ils recherchent des histoires individuelles de marketing formidable:

Ne sautez pas directement dans l’écriture immédiate d’une réponse. Assurez-vous toujours de vérifier d'abord les réponses existantes pour savoir ce que les gens recherchent.
3. Racontez des histoires
Dans les grandes catégories telles que les conseils de vie, les Quorans aiment les récits personnels par opposition aux conseils directs et exploitables.
If you’re playing in those pits, you’ll have to learn how to tell a good story. I’m the first to admit I’m not a fantastic storyteller, but I’ve used a few strategies to improve that skill:
- Use dialogue. I learned this from Josh Fechter. Dialogue helps to immerse your readers in the story.
- In media res. Ever read Fight Club? Then you’ll be familiar with this. This is a storytelling technique that means “open in the midst of the plot.” By starting your story in the middle (the “conflict”), you keep your readers engaged, as they try to deduce what happened earlier, and predict what will happen next.
4. Use controversy to your advantage
Look at this example:
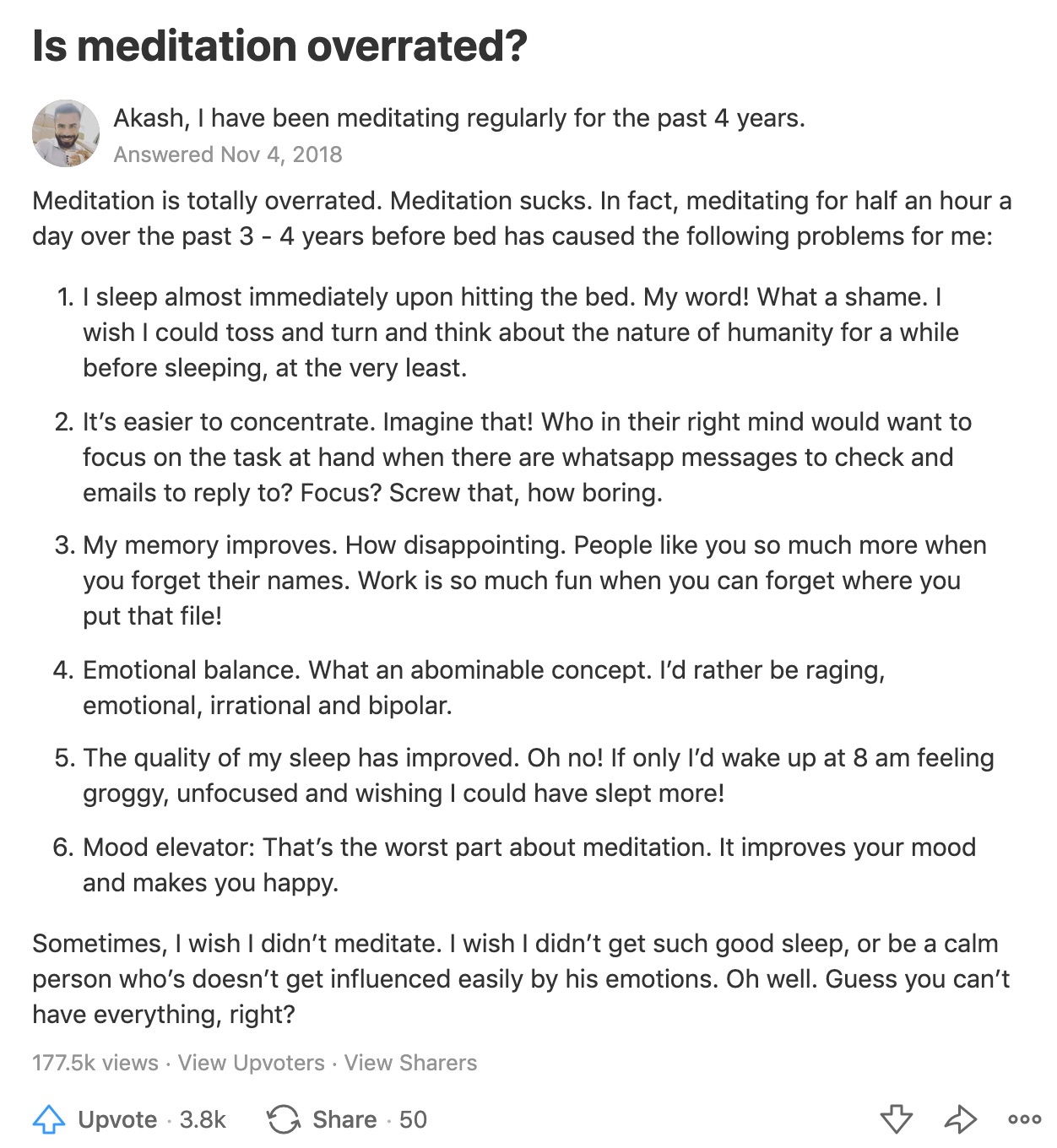
Akash’s answer stands out because it’s opposite to what people expect as an answer to this question. (Plus, Quorans love snark and sarcasm!)
If you can provide an unexpected or unconventional answer, you will likely get plenty of upvotes and views.
As always, don’t abuse this. It’s okay if you genuinely believe the opposite, but Quorans will disregard you if they realize you’re only trying to game the system.
5. Interlink your answers
By linking your answers together, you can keep a reader going down the “Quora rabbit hole.”
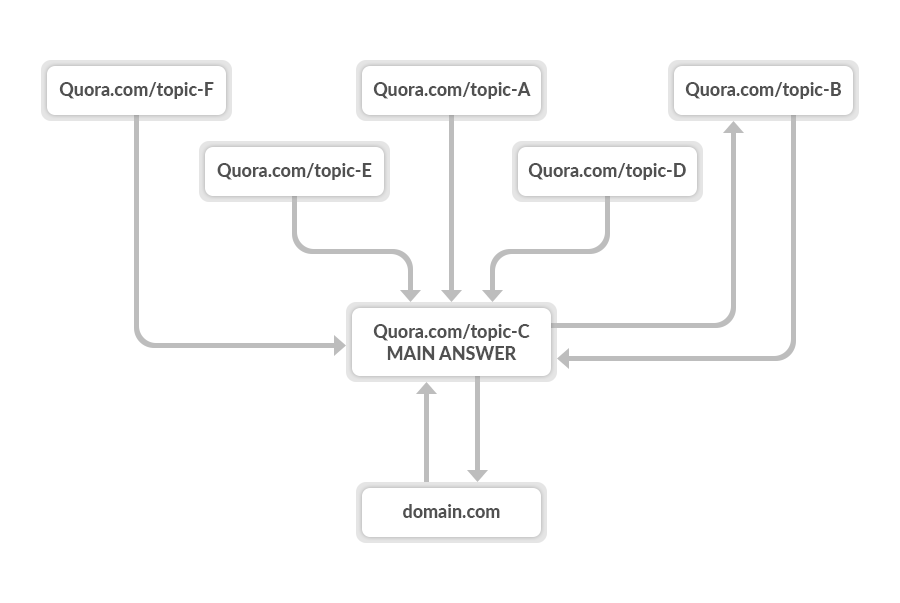
Your main answer (“hub”) should be the one that receives the most views. This answer should also link out to a piece of content on your site (to drive referral traffic.)
Answer 3–5 related questions and link them to your main answer. That way, you can send more readers back to the “hub,” and they might follow the link back to your site.
Sidenote.
Jason recommends doing this. To be transparent, I have not personally tried this. But it makes a lot of sense to me so I may give it a try in the future.
Here are some more tips I couldn’t squeeze in the other categories.
A. Be consistent
This is cliche advice, but social media rewards consistency. Quora is no exception.
The more questions you answer, the more likely it is you’ll appear in people’s feeds, and the more upvotes and views you’ll get.
Quand Jason Lemkin first started, he answered 2–3 questions a day, 5–7 days a week. 53 million views later, he’s still going!
My friend Dean Yeong, Head of Content at Sumo, answered 1–3 questions a day in the first six months to gain traction.
Likewise, I did my best to answer at least one question a day.
It may be tough to write a daily answer in the beginning, but build a habit and keep going. That’s how you stand out.
B. Join “Spaces”
Spaces are Quora’s answer to subreddits and Facebook Groups. You can search for relevant spaces ici.
JD Prater, Quora’s Evangelist, shared one of my answers in his Digital Marketing News and Trends space. As a result, I got hundreds of upvotes and thousands of views:
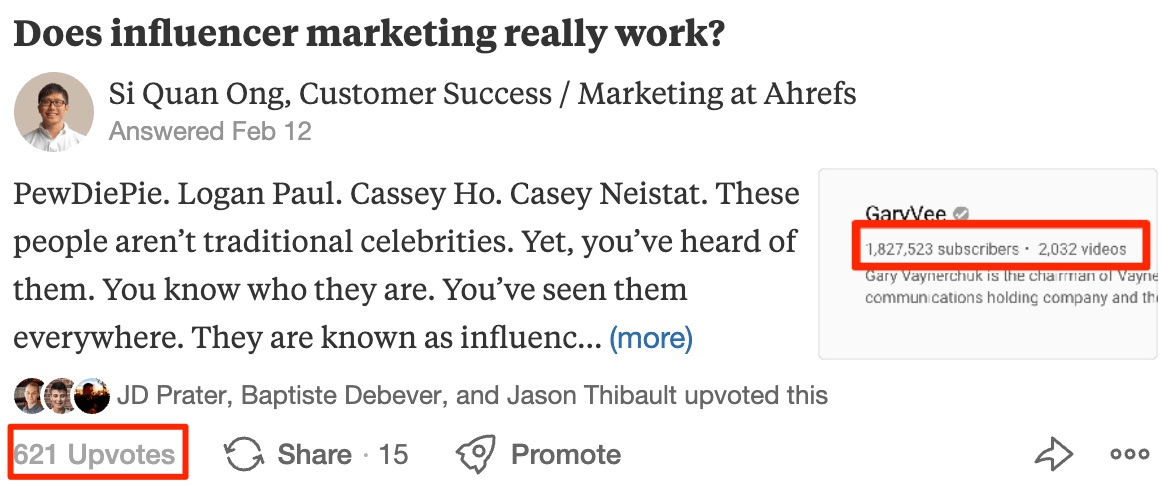
At the time of writing, Spaces is still in beta, and you must be invited to create one. However, you can join and participate.
To do well, treat it like any community. Upvote, comment, and share useful links and Quora answers. Eventually, you might be upgraded to Contributor, Moderator, or even an Admin:

As you gain trust in the community, you can share your content (don’t spam!).
C. Add “Answer Wikis”
You’ll notice some questions have an Answer Wiki:
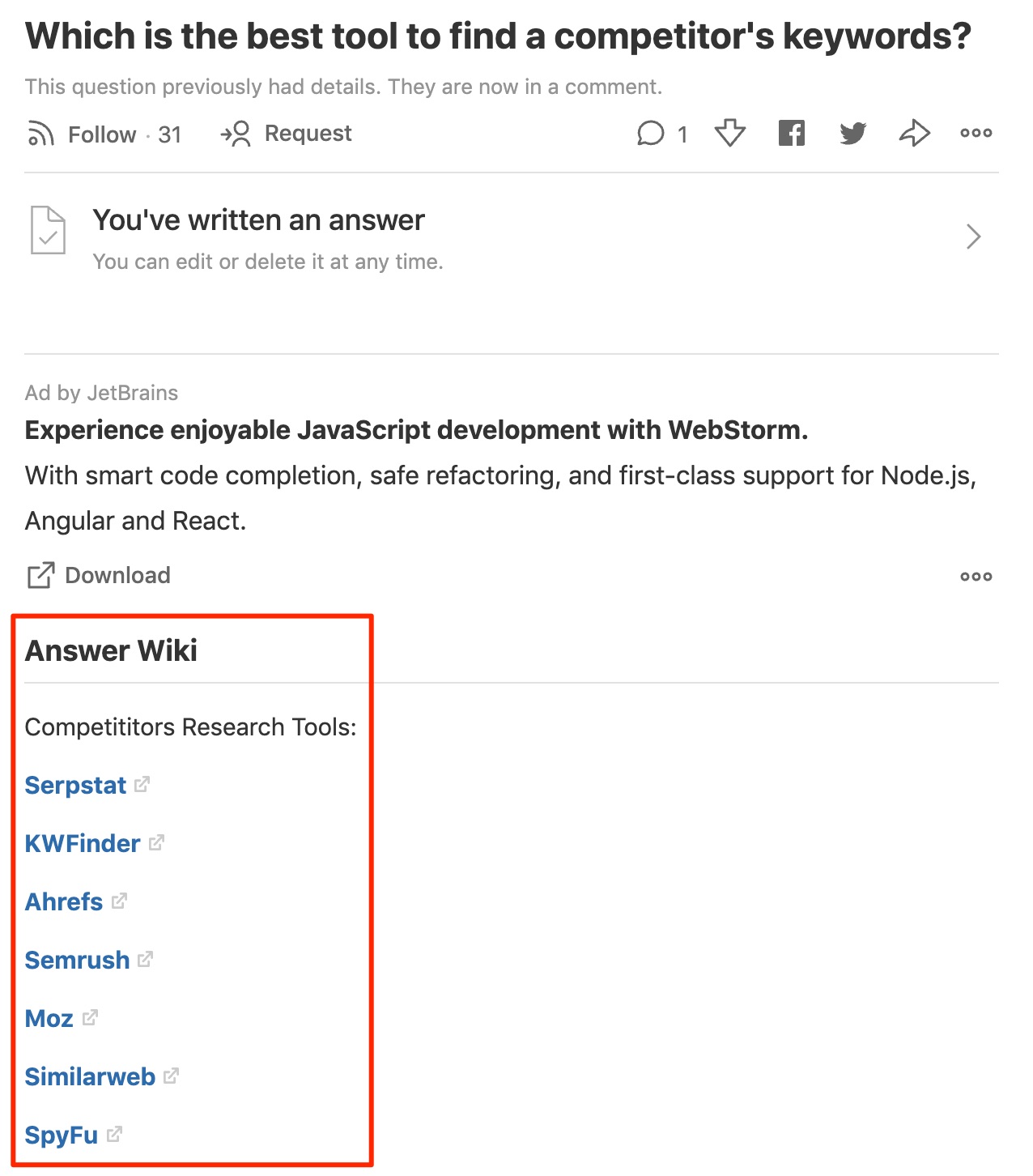
The purpose: aggregate the different answers into one impartial, factual, and comprehensive version. But since anyone can edit the Answer Wiki:
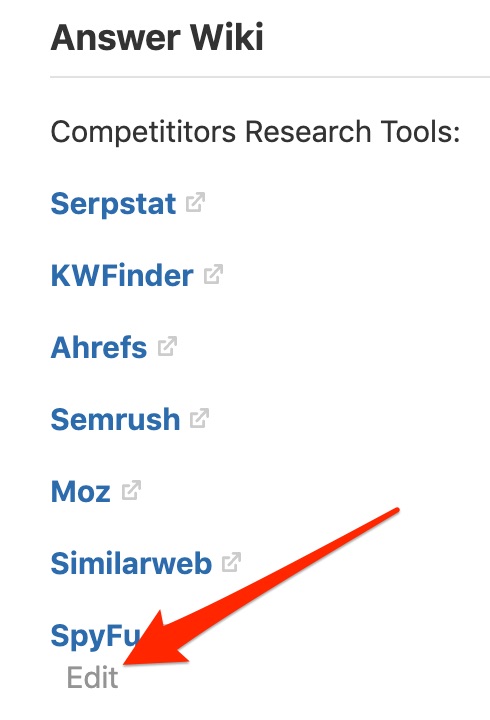
Or create one:
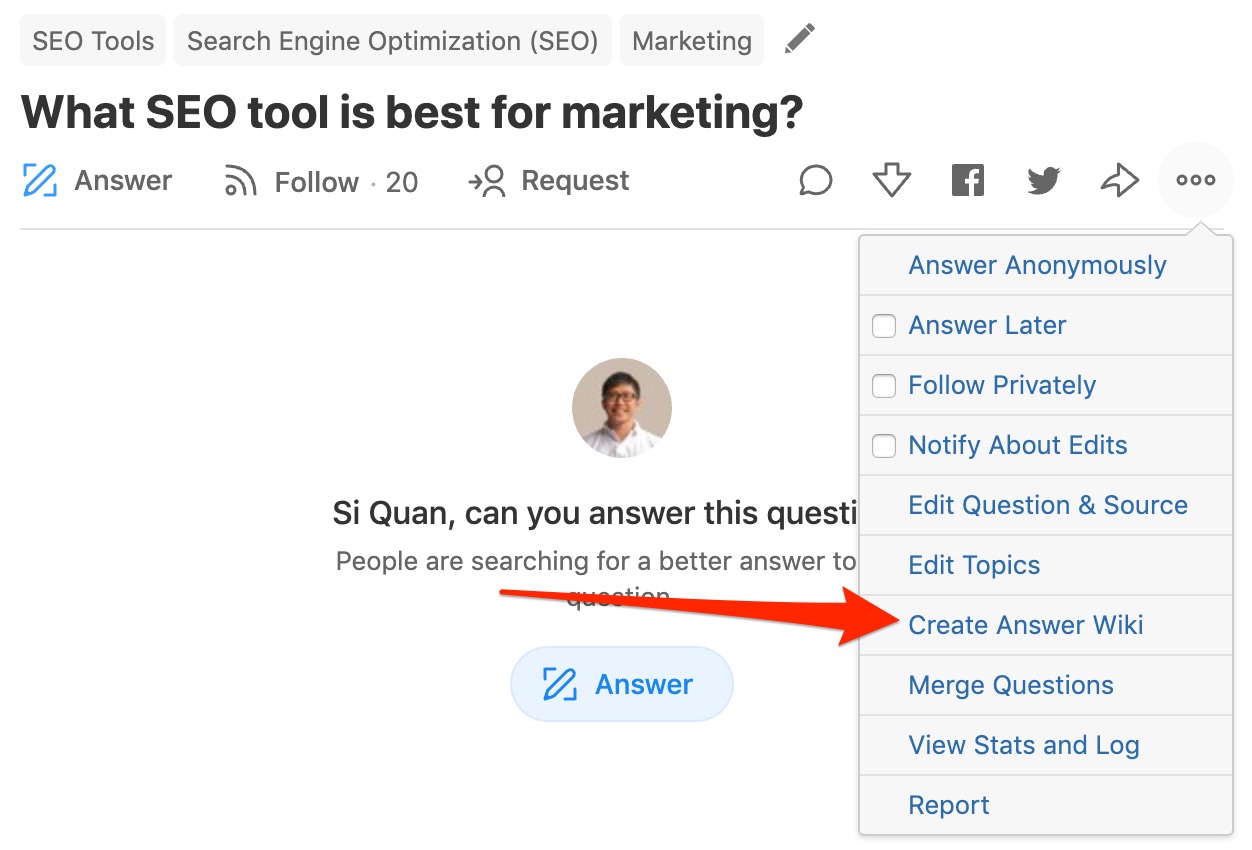
You can use this to your advantage by including links to your website or content.
A caveat: don’t just stuff the entire Answer Wiki with your links. The goal is to make it valuable. If your product or service is relevant to the question, then feel free to add it. If not, don’t squeeze your mention in there.
Plus, Answer Wikis need to be passed for moderation, so you likely won’t get away with link stuffing.
If your answers are doing well organically on Quora, you can consider using Quora Ads to boost their performance.
Voici quelques idées.
1. Quora Promoted Answers
Cette answer from Gabriel Weinberg, Founder of DuckDuckGo has received ~180m views:
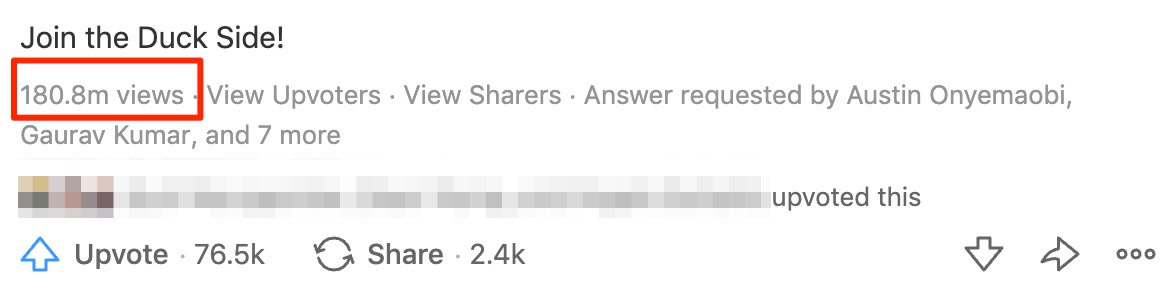
La raison? Quora Promoted Answers.
Quora allows individuals or businesses to sponsor any of their answers to achieve better distribution.
Curious to find out if I could achieve similar results, I decided to run an experiment.
- I looked through my Quora stats to find two questions still gaining views in the previous week;
- I replaced all the links in those answers with bit.ly links;
- I ran a $50-per-promoted-answer campaign (total budget: $100).
Here are the results:

Looks pretty decent, right? Pas assez.
According to Quora, the “Clicks” metric measures how often someone clicks “More” for your answer:
![]()
![]()
![]()
That means: someone might click to see your answer in full, but they might not click on any of the links to your website. Which is exactly what happened.

Pretty abysmal.
Does this mean that “Promoted Answers” don’t work du tout?
I wouldn’t paint it with such a broad brush stroke. After all, this is only a small experiment, and I didn’t test every possibility. Plus, there could be a few reasons why it worked better for Gabriel, but not me:
- He targeted a broader question;
- Gabriel and DuckDuckGo are synonymous (but not Ahrefs and me);
- DuckDuckGo has a fascinating underdog story, and people are naturally interested in them;
- Google and privacy concerns are hot topics on social (and by extension, Quora);
- DuckDuckGo has a much larger brand than us;
- Gabriel has a much larger personal brand than me.
My colleague, Michal, got pretty good results with Promoted Answers when he was at CDN77. So I would encourage you to test and make your own conclusions.
2. Questions Targeting
What else can you do with the set of URLs you extracted earlier?
Create a “Questions Targeting” campaign.
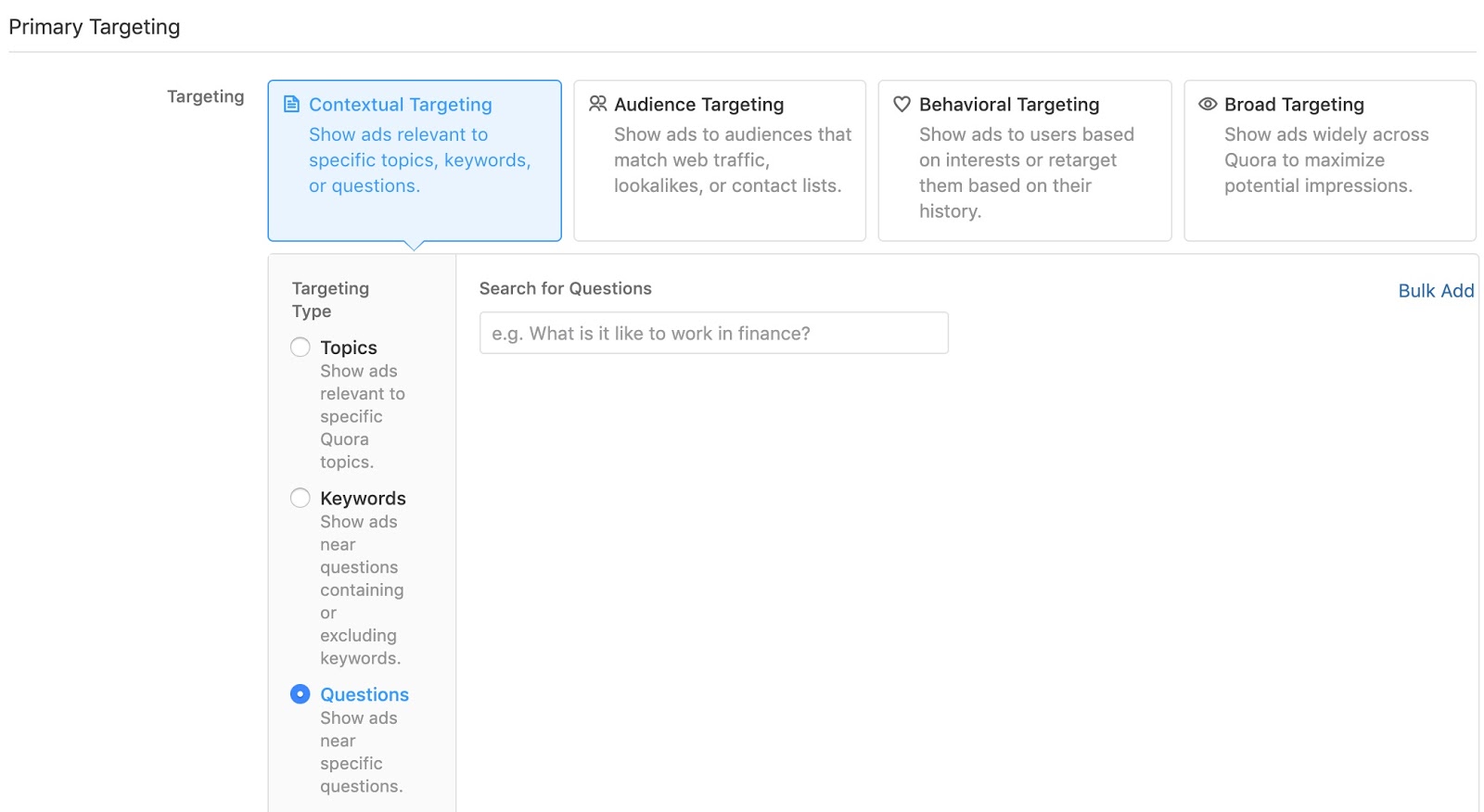
The eventual goal is to have both your ad and organic answer shown on questions that are important to your business.
The benefits are two-fold:
- After seeing your ad, the reader might be more likely to read your answer;
- After reading your answer, the reader might click on your ad.
3. Questions Retargeting
The Quora Ads platform also allows retargeting. In this case, you’ll have to set up the pixel on your website.
![]()
![]()
![]()
Once you’ve set it up, you can use “Questions Retargeting”.
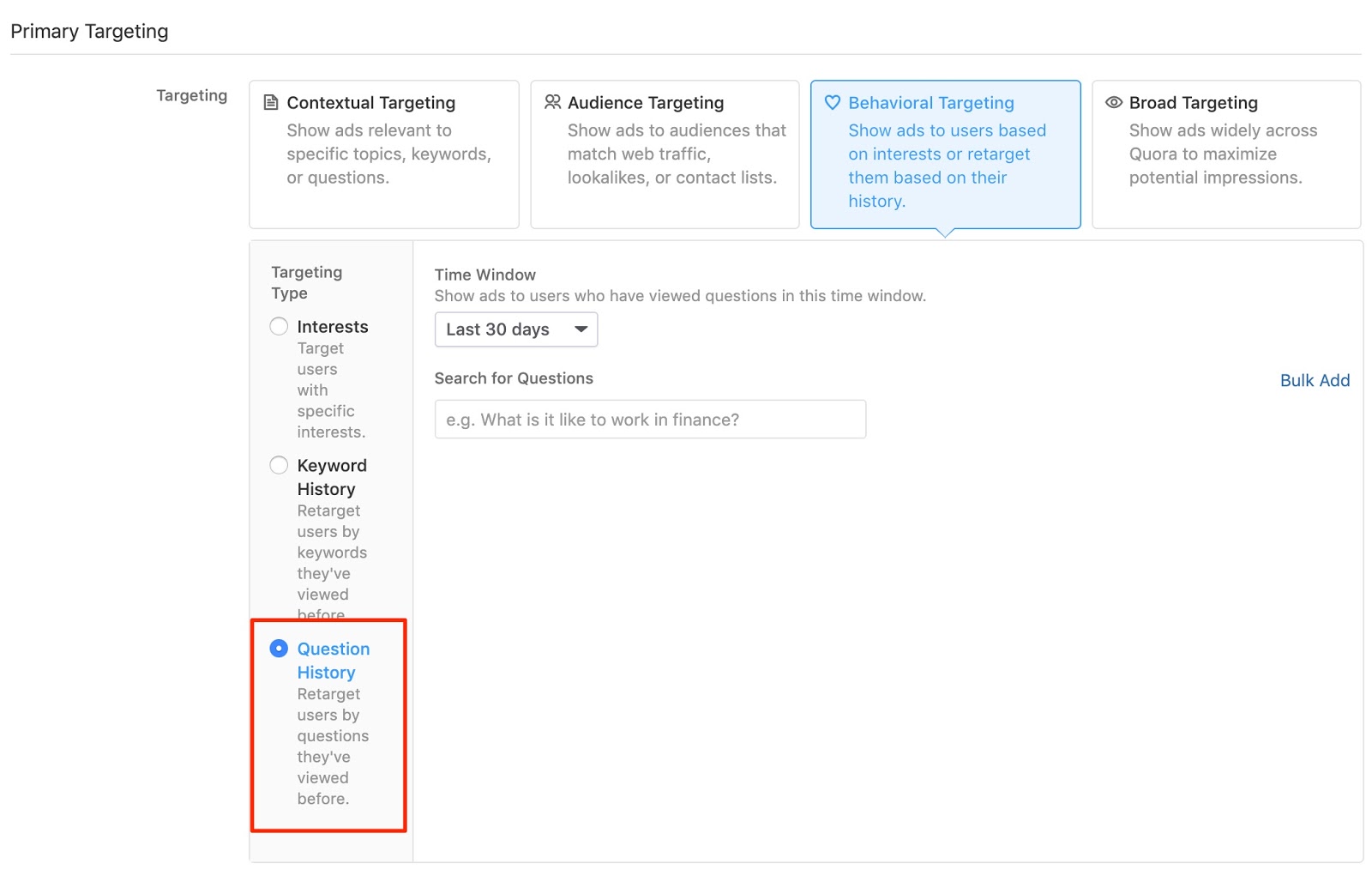
With this, you can leverage your existing list of questions and show your ads throughout Quora to people who have viewed those questions but not clicked through to your website.
One last question: how do I get into the Quora Digest?
The Quora Digest is an email that consists of content Quora thinks you’re interested in.
The easiest way to get in is via Quora ads.
Otherwise, if your answer is popular enough, it may get included in one:

What I’ve noticed non-scientifically: if your answer gets 7–10 upvotes, it’ll be included in a smaller Quora digest. Then, as you get more upvotes, Quora will include it in a larger version (as seen above.)
However, I’ve also noticed that getting included in the Digest is vanity. My answers have been included a few times, but I’ve never seen any increases in upvotes nor views.
Dernières pensées
I was lucky one day to get an answer translated into Italian by a kind soul:

Given that Quora is rapidly expanding into other languages, one thing I’ve not tried is repurposing our translated content or translating my answers into another language.
I do wonder how much extra views or traffic I would be able to get.
Anyway, I hope this guide was useful in helping you tackle Quora.
Is there anything that I’ve missed? Let me know in the comments or on Twitter.

Vous voulez réduire votre taux de rebond, mais qu'est-ce que cela signifie réellement? Moteur de recherche

Combien de fois avez-vous cité une métrique extraite de Google Analytics sans vraiment savoir ce que cela signifiait? Ne crains pas, tu n’es pas seul.
Depuis trop longtemps, les spécialistes du marketing ont eu des idées fausses sur la façon de définir une métrique particulière – le taux de rebond, ce qui la confondait avec le taux de sortie ou en ajoutant des critères inexistants. Nous avons donc mis au point un guide rapide pour vous aider à devenir un passionné de taux de rebond.
Comment le taux de rebond est-il calculé dans Google Analytics?
Le Google Analytics guide d'aide est un bon premier arrêt lorsque vous essayez d'aller au fond des choses. Et avec cela, il vous suffit de vous rappeler deux choses essentielles:
1. Un rebond dans Google Analytics est une session d'une page sur un site web
2. Le taux de rebond d'une page est basé uniquement sur les sessions commençant par cette page.
Qu'est-ce que cela signifie en pratique?
Voici un exemple avec trois sessions:
Imaginez qu'il y ait eu trois sessions d'utilisateurs sur votre site Web. Au cours de ces sessions, les pages suivantes ont été visionnées dans cet ordre:
- Première session: page A> page B> page C> exit
- Deuxième session: page B> page A> page C> exit
- Session trois: page A> sortie
Taux de rebond de la page A = 50%
Taux de rebond de la page B =0%
Taux de rebond de la page C = 0%
Pourquoi? Vous avez peut-être tendance à penser que le taux de rebond de la page A est de 33% car la page a été visionnée trois fois et que l'utilisateur n'est sorti du site Web qu'après avoir consulté la page A. C'est une idée fausse commune, mais cette logique est en réalité la définition du «taux de sortie».
De même, vous pourriez être tenté de penser que le taux de rebond de la page C est de 100%, car toutes les sessions qui ont inclus la page C dans leur parcours ont été immédiatement suivies d’une sortie. Toutefois, seules les pages commençant une session sont incluses dans ces calculs.
Voici un exemple avec cinq sessions:
- Page B> page A> page C> sortie
- Page B> sortie
- Page A> Page C> Page B> sortie
- Page C> sortie
- Page B> page C> page A> sortie
Le taux de rebond de la page C est de 100%. Il a été visité quatre fois, cependant, une seule session a commencé avec. Il est donc le seul à compter de Google Analytics dans ses calculs de taux de rebond.
Qu'est-ce qu'une sortie dans Google Analytics?
En termes simples, une sortie est lorsqu'un utilisateur quitte le site Web d'une manière ou d'une autre.
Cela signifie que si l'un des objectifs de votre site Web est d'inciter les utilisateurs à cliquer sur un détaillant tiers après avoir consulté une page de produit, les utilisateurs devront quitter le site Web pour pouvoir être comptabilisés comme une conversion.
Dans ce cas particulier, vous pourriez théoriquement avoir des pages présentant simultanément un taux de rebond de 100% et un taux de conversion de 100%. Mais réduire le nombre de sessions d'une seule page sur votre site Web est-il vraiment votre objectif?
Sinon, vous voudrez peut-être envisager un indicateur de performance clé différent pour votre entreprise. Pour SEO marketing, c’est souvent le KPI incontournable pour rendre compte des performances, mais d’autres – telles que le taux de sortie – peuvent être plus adaptées aux objectifs de votre site Web.
Comment devrions-nous utiliser le taux de rebond et le taux de sortie pour un reporting efficace?
1. Taux de rebond au niveau du site Web
Au niveau du site Web (le chiffre généralement présent dans le tableau de bord Google Analytics), le taux de rebond ne représente que le pourcentage de sessions d'une seule page par rapport à l'ensemble des sessions.
En raison de ses paramètres par défaut, Google Analytics peut induire en erreur car il indique une flèche décroissante avec une flèche verte, ce qui suggère qu'il est «bon», tandis que toute reprise est marquée en rouge et perçue comme «mauvaise». Cependant, avoir un taux de rebond plus élevé peut être une bonne chose – l’utilisateur n’a peut-être besoin que de visiter une page pour trouver les informations dont il a besoin. Cela dépend entièrement du type de site Web sur lequel vous faites rapport et du contenu qu’il sert (commerce électronique, blogs, informationnel, et les autres).
Les modifications du taux de rebond au niveau du site Web ne doivent pas être utilisées pour évaluer les performances d'un site Web, mais plutôt pour notifier un changement nécessitant une enquête plus approfondie.
2. Taux de rebond au niveau de la page
Si cela augmente pour une page particulière, il est important d'évaluer le type de page pour savoir si le changement est positif ou négatif:
Une liste non exhaustive d'exemples
- Page d'accueil: une augmentation du taux de rebond est généralement négative et signifie que moins d'utilisateurs sont disposés à visiter un site Web au-delà de sa page d'accueil.
- Contenu / article: une augmentation du taux de rebond pourrait signifier que les utilisateurs ont trouvé les informations dont ils ont besoin. Dans ce cas, le taux de rebond seul ne peut pas être utilisé pour déterminer un changement positif ou négatif.
- Page produit: une augmentation du taux de rebond sur les pages contenant des fonctionnalités de commerce électronique doit être analysée en même temps que les modifications apportées récemment aux modèles de site Web afin de garantir que l'expérience utilisateur n'affecte pas négativement l'expérience d'achat.
3. Taux de sortie au niveau du site Web
Au niveau d'un site Web, le taux de sortie ne fournit pas de données très significatives car les utilisateurs devront toujours quitter un site Web à partir de l'une de ses pages à un moment donné.
Google Analytics fournit toujours ce type de données sous l'onglet Comportement, mais il n'est pas recommandé d'utiliser ces informations pour générer des rapports sur les performances Web.
Le taux de sortie au niveau du site Web ne peut être autre que 100%. Toutefois, sachez que Google Analytics utilise une moyenne des taux de sortie pour toutes les pages du site Web afin d’obtenir une «moyenne de site Web».
4. Taux de sortie au niveau de la page (ou ensemble de pages)
C'est là que le taux de sortie brille vraiment. Si vous avez un parcours d'utilisateur idéal pour votre site Web, le taux de sortie peut vous aider à identifier les changements de comportement des utilisateurs. À partir de là, vous pouvez modifier les modèles de pages Web pour amener les utilisateurs d'un point à un autre – en utilisant plusieurs pages et en surveillant le point de sortie des utilisateurs – et ainsi terminer leur parcours.
Maintenant que vous maîtrisez la différence entre taux de rebond et taux de sortie et comment les utiliser efficacement dans vos rapports, il est temps de mettre vos connaissances en pratique. Connectez-vous à Google Analytics et commencez à comprendre ce que ces statistiques signifient réellement pour le site Web.
Lecture connexe

Jim Yu, de BrightEdge, décrit les cinq niveaux de redimensionnement du référencement, du référencement manuel au référencement en temps réel et aux optimisations automatisées.

Hubspot a constaté que 82% d'un sondage auprès des consommateurs laisserait un site Web non sécurisé. Quatre étapes pour commencer à utiliser la sécurité et pourquoi cela aidera votre référencement.

Quiconque s’appuyant sur rel = nofollow pour tenter d’empêcher l’indexation d’une page doit envisager d’utiliser d’autres méthodes pour empêcher l’exploration ou l’indexation des pages.

Faits saillants de l'événement Transformation of Search Summit, comprenant des citations, des statistiques et d'autres informations intéressantes, notamment sur Twitter.
Source link
Meilleur suivi des téléchargements et plus
Aujourd’hui, nous sommes ravis d’annoncer la sortie de Project Delight Phase 3!
Comme dans La phase 1 et Phase 2 de Project Delight, nous avons continué à apporter d’autres améliorations pour vous aider à développer votre entreprise. Notre objectif est que chaque fois que vous utilisez MonsterInsights, toute l'expérience soit un plaisir.
Dans la dernière version, vous trouverez des modifications apportées au suivi des téléchargements de fichiers, des paramètres d’autorisations améliorés, une nouvelle exclusion du suivi des éditeurs, et bien plus encore.
Examinons chaque mise à jour plus en détail…
Suivi amélioré du téléchargement de fichiers
Le suivi des téléchargements de fichiers de MonsterInsights est l’une de nos fonctionnalités les plus populaires car il suit automatiquement les téléchargements, aucun code n’est nécessaire et fournit des informations sur le type de contenu le plus populaire sur votre site.
Mais nous avons réalisé que nous pouvions le rendre encore plus utile pour vous en changer les types de fichiers par défaut que nous suivons.
Nous avons constaté que peu d’utilisateurs utilisaient le suivi de téléchargement de fichiers pour les fichiers .exe, .js et .tgz.
Donc, en fonction de vos commentaires, nous avons supprimé ceux-ci du suivi par défaut. MonsterInsights assure également le suivi par défaut des types de fichiers .docx, .pptx et .xlsx pour offrir une expérience plus agréable.
![]()
Alors que MonsterInsights suivra ces types de fichiers par défaut, vous pouvez toujours personnaliser vos paramètres pour suivre d'autres types de fichiers.
Amélioration des workflows de configuration de MonsterInsights pour les agences
Parfois, les agences pré-installent MonsterInsights afin que leurs clients puissent facilement se connecter, configurer MonsterInsightset que Google Analytics soit prêt à fonctionner.
Auparavant, si ces rôles étaient attribués à des clients non administrateurs, ils ne pourraient pas modifier les paramètres MonsterInsights. C’est parce que le paramètre permettant de modifier les rôles WordPress pouvant modifier les paramètres MonsterInsights a été désactivé jusqu’à ce que Google Analytics soit connecté.
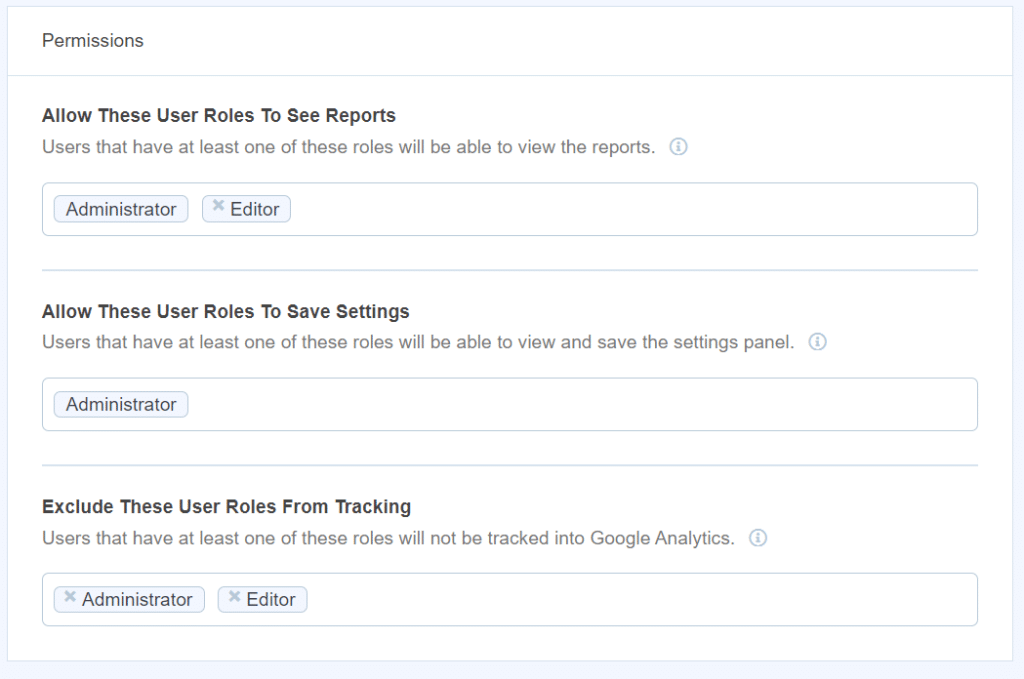
Désormais, ce paramètre peut maintenant être modifié à tout moment, ce qui facilite le flux de travail. Vous pouvez voir notre doc sur Comment autoriser les rôles d'utilisateur à accéder aux rapports et paramètres MonsterInsights pour plus d'informations.
Exclusion des éditeurs du suivi pour la précision des données
Dans notre version précédente, MonsterInsights excluait le suivi des utilisateurs administrateurs (et sur les installations multisites, super administrateur) afin d'empêcher les propriétaires de sites de fausser les données de leur site Web, notamment les rapports démographiques.
Avec cette dernière version, nous avons également exclu les éditeurs du suivi afin de rendre vos données plus précises que jamais.
Si vous souhaitez ajouter ou supprimer des rôles du suivi, vous pouvez utiliser notre exclure les rôles d'utilisateur réglage en naviguant vers le Avancée languette. Puis supprimez les rôles de Exclure ces rôles d'utilisateur du suivi sous Les permissions.
![]()
Amélioration continue de Project Delight
Nous avons également apporté un certain nombre d'améliorations mineures tout au long du plugin, notamment des liens de documentation plus utiles, la résolution de quelques bugs mineurs et l'amélioration du temps de chargement de l'élément de la barre de menu Insights.
Dans le cadre de Project Delight, vous remarquerez que notre mascotte Charlie fournit désormais des informations utiles et des liens directement à partir de votre tableau de bord!
Charlie est également prêt à vous aider lorsque vous consultez vos rapports de tableau de bord MonsterInsights, avec des liens rapides vers le support et la documentation utiles.
Avec cette dernière version, nous avons également mis à jour nos versions recommandées de PHP à 5.6.20 (configuration minimale requise de WordPress) et WordPress à 5.0 ou plus récent.
C’est tout pour cette version!
Tous les changements sont maintenant en direct sur MonsterInsights, alors qu'attendez-vous? Cliquez ici pour commencer à utiliser MonsterInsights aujourd'hui!
De nombreuses fonctionnalités et versions intéressantes sont à votre disposition, alors restez à l'affût des annonces à venir. N'oubliez pas de nous suivre sur Facebook et Twitter pour les dernières mises à jour.
Vous avez une idée pour une future version de Project Delight et souhaitez la partager avec nous? Soumettez-le sur notre Formulaire de commentaires!
Et avant de partir, l’équipe MonsterInsights aimerait vous remercier pour votre soutien continu et pour aider MonsterInsights à être le meilleur plugin Google Analytics WordPress.
![Annonces de magasinage YouTube, pénalités Bing Link, endossements des influenceurs et autres nouvelles [PODCAST]](https://premiumreferencement.com/wp-content/uploads/2019/11/akjn2xmr-5dc481aab68b7-1170x700.png)
Annonces de magasinage YouTube, pénalités Bing Link, endossements des influenceurs et autres nouvelles [PODCAST]
Restez au courant de l'épisode de cette semaine de Marketing O’Clock, qui fait partie du réseau de moteurs de recherche Search Podcast Network.
Greg Finn et Christine «Shep» Zirnheld couvrent l’actualité du marketing numérique dont vous avez parlé toute la semaine et les informations que vous avez peut-être manquées.
Positionnement YouTube pour les annonces d'achat
Joie au monde! Un nouvel emplacement publicitaire a été offert aux annonceurs juste à temps pour la saison des vacances.
Shep vous explique comment faire en sorte que vos annonces puissent être diffusées dans les flux de recherche et les flux d'accueil de YouTube.
Bing annonce de nouvelles sanctions pour spam
Greg nous dit quels types de sites seront affectés par les changements, en les décomposant en termes simples (ou artistes) afin que vous puissiez être préparé.
La FTC publie des directives sur la divulgation d'informations sur les influenceurs
Shep couvre ce que la FTC considère comme un endossement d'influence et des recommandations sur la manière de les divulguer sur les réseaux sociaux.
Greg a lui-même une recommandation sur le choix du nouveau porte-parole de la FTC.
Présentation du rapport de vitesse de la console de recherche Google
Greg nous dit tout ce que nous devons savoir sur ce nouvel outil qui aidera les professionnels du référencement et les webmasters en général.
Dans notre article de la semaine, James Webster s'interroge sur les capacités de Google en matière de correspondance des requêtes pour les campagnes d'achat. Nous ne sommes pas sûrs que l’intention concorde avec l’intention, mais nous adorons les gros bouledogues français.
La qualité des requêtes de recherche a-t-elle toujours été aussi mauvaise depuis les campagnes d'achat ou s'aggrave-t-elle?
Celles-ci et beaucoup d’autres sont venues d’une campagne d’APA sur des lits de chiens…
"Gros bouledogue français"
"Comment empêcher les chats de faire caca sur ma pelouse"#ppcchat– James Webster (@PPC_Webster) 4 novembre 2019
De plus, Uber Eats semble se préparer à vendre des annonces sur sa plate-forme, mais nous avons une autre recommandation non sollicitée sur la façon dont ils peuvent gagner plus d'argent.
Greg nous présente également de nouvelles fonctionnalités pratiques sur Twitter. Si seulement nous pouvions activer «me retirer de cette conversation» dans le monde réel!
Pour plus d'informations sur les histoires de cette semaine, n'oubliez pas de visiter Le temps du marketing site pour lire les notes complètes du spectacle. Assurez-vous de vous abonner où que vous écoutiez des podcasts!
![Annonces Shopping sur YouTube, sanctions Bing Link, endossements des influenceurs & # 038; Plus de nouvelles [PODCAST]](https://cdn.searchenginejournal.com/wp-content/uploads/2019/10/bjpri2wb-5db0b50cc58d0.png)
![Annonces Shopping sur YouTube, sanctions Bing Link, endossements des influenceurs & # 038; Plus de nouvelles [PODCAST]"width =" 149 "height =" 50 "data-srcset =" "data-src =" https://cdn.searchenginejournal.com/wp-content/uploads/2019/10/bjpri2wb-5db0b50cc58d0.png](data:image/svg+xml,%3Csvg%20xmlns=%22http://www.w3.org/2000/svg%22%20viewBox=%220%200%20149%2050%22%3E%3C/svg%3E)
![Annonces Shopping sur YouTube, sanctions Bing Link, endossements des influenceurs & # 038; Plus de nouvelles [PODCAST]](https://cdn.searchenginejournal.com/wp-content/uploads/2019/10/vbdofi25-5db0b512d505d.png)
![Annonces Shopping sur YouTube, sanctions Bing Link, endossements des influenceurs & # 038; Plus de nouvelles [PODCAST]](https://cdn.searchenginejournal.com/wp-content/uploads/2019/10/7c4rxhea-5db0b50bcc3f6.png)
![Annonces Shopping sur YouTube, sanctions Bing Link, endossements des influenceurs & # 038; Plus de nouvelles [PODCAST]](https://cdn.searchenginejournal.com/wp-content/uploads/2019/10/bw6xjswc-5db0b50ee224e.png)
Crédits d'image
Image sélectionnée: Cypress North

Exemple de meilleure pratique pour le référencement • Yoast

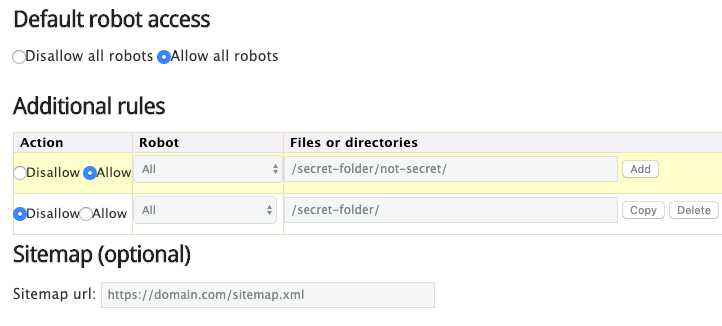
Votre fichier robots.txt est un outil puissant lorsque vous travaillez sur le référencement d'un site Web, mais il doit être manipulé avec précaution. Il vous permet de refuser aux moteurs de recherche l’accès à différents fichiers et dossiers, mais c’est souvent le cas. ne pas le meilleur moyen d'optimiser votre site. Nous expliquerons ici comment, selon nous, les webmasters devraient utiliser leur fichier robots.txt et proposerons une approche de "meilleure pratique" adaptée à la plupart des sites Web.
Vous trouverez un exemple de fichier robots.txt qui fonctionne pour la grande majorité des sites Web WordPress plus bas sur cette page. Si vous voulez en savoir plus sur le fonctionnement de votre fichier robots.txt, vous pouvez lire notre guide ultime de robots.txt.
À quoi ressemble la «meilleure pratique»?
Les moteurs de recherche améliorent continuellement la manière dont ils explorent le Web et indexent le contenu. Cela signifie que ce qui était autrefois la meilleure pratique il ya quelques années ne fonctionne plus et peut même nuire à votre site.
Aujourd'hui, les meilleures pratiques consistent à utiliser le moins possible votre fichier robots.txt. En fait, il est vraiment nécessaire de bloquer les URL dans votre fichier robots.txt lorsque vous rencontrez des problèmes techniques complexes (par exemple, un site Web de commerce électronique de grande taille avec une navigation par facettes) ou lorsqu'il n'y a pas d'autre option.
Bloquer des URL via robots.txt est une approche «brutale» qui peut entraîner plus de problèmes qu’elle ne résout.
Pour la plupart des sites WordPress, l'exemple suivant constitue la meilleure pratique:
# Cet espace est laissé intentionnellement vide
# Si vous voulez savoir pourquoi notre fichier robots.txt ressemble à ceci, lisez ce message: https://yoa.st/robots-txt
Agent utilisateur: *Nous utilisons même cette approche dans notre propre fichier robots.txt.
Que fait ce code?
- le
Agent utilisateur: *instruction indique que les instructions suivantes s’appliquent à tous les robots. - Comme nous ne fournissons aucune autre instruction, nous disons «tous les robots peuvent librement explorer ce site, sans restriction».
- Nous fournissons également des informations aux utilisateurs qui consultent le fichier (vers cette page), afin qu’ils comprennent pourquoi le fichier est «vide».
Si vous devez interdire les URL
Si vous souhaitez empêcher les moteurs de recherche d’analyser ou d’indexer certaines parties de votre site WordPress, il est presque toujours préférable de le faire en ajoutant balises meta robots ou robots en-têtes HTTP.
Notre guide ultime pour les balises meta robots explique comment vous pouvez gérer l’exploration et l’indexation de la bonne manière, et notre plug-in Yoast SEO fournit les outils nécessaires pour vous aider à mettre en oeuvre ces balises sur vos pages.
Si votre site présente des problèmes d’exploration ou d’indexation qui ne peuvent pas être résolus via balises meta robots ou En-têtes HTTP, ou si vous devez empêcher l’accès au robot pour d’autres raisons, vous devriez lire notre guide ultime sur robots.txt.
Notez que WordPress et Yoast SEO empêchent déjà automatiquement l’indexation de certains fichiers et URL sensibles, comme votre zone d’administration WordPress (via un En-tête HTTP x-robots).
Pourquoi cette pratique du «minimalisme»?
Robots.txt crée des impasses
Avant de pouvoir rivaliser sur les résultats de recherche, les moteurs de recherche doivent découvrir, analyser et indexer vos pages. Si vous avez bloqué certaines URL via le fichier robots.txt, les moteurs de recherche ne peuvent plus analyser par ces pages pour découvrir d'autres. Cela peut signifier que les pages clés ne sont pas découvertes.
Robots.txt nie les liens de leur valeur
L'une des règles de base du référencement est que les liens d'autres pages peuvent influer sur vos performances. Si une URL est bloquée, non seulement les moteurs de recherche ne l'exploreront pas, mais ils pourraient également ne pas distribuer de "valeur de lien" pointant vers cette URL, ou par cette URL vers d'autres pages du site.
Google rend entièrement votre site
Auparavant, les utilisateurs bloquaient l'accès aux fichiers CSS et JavaScript pour que les moteurs de recherche restent concentrés sur ces pages de contenu très importantes.
De nos jours, Google récupère tous vos styles et JavaScript et rend vos pages complètement. Comprendre la mise en page et la présentation de votre page est un élément clé de la façon dont elle évalue la qualité. Donc, Google n'aime pas ça du tout lorsque vous lui refusez l'accès à vos fichiers CSS ou JavaScript.
Meilleure pratique de blocage de l'accès à votre wp-comprend répertoire et votre répertoire de plugins via robots.txt n'est plus valide, c'est pourquoi nous avons collaboré avec WordPress pour supprimer les paramètres par défaut. refuser règle pour wp-comprend dans la version 4.0.
De nombreux thèmes WordPress utilisent également des requêtes JavaScript asynchrones – appelées AJAX – pour ajouter du contenu à des pages Web. WordPress bloquait Google par défaut, mais nous avons corrigé cela dans WordPress 4.4.
Vous n'avez généralement pas besoin de créer un lien vers votre sitemap
Le standard robots.txt prend en charge l’ajout d’un lien vers votre ou vos sitemap XML au fichier. Cela aide les moteurs de recherche à découvrir l'emplacement et le contenu de votre site.
Nous avons toujours pensé que c'était redondant. vous devriez déjà en ajoutant votre sitemap à votre Google Search Console et Bing Webmaster Tools comptes afin d'accéder aux données d'analyse et de performance. Si vous avez fait cela, vous n’avez pas besoin de la référence dans votre fichier robots.txt.
Lire la suite: Empêcher l'indexation de votre site: la bonne manière »
Source link

SEO local: Le guide définitif
Comment suivre les classements des packs de cartes
L’une des premières étapes de toute campagne de référencement local consiste à évaluer où vous en êtes.
Plus précisément, vous voulez savoir où vous vous situez dans The Map Pack. Et suivez vos classements Map Pack au fil du temps.
Presque tous les suivis de rang sur la planète ont un suivi de Map Pack.
Le problème, c’est que, avec le référencement local, vous cherchez énormément. En fait, les résultats du pack de cartes peuvent être complètement différents d'un kilomètre à l'autre.
Par exemple, supposons que quelqu'un cherche un «café» sur les 72 e et 2e avenues de New York.

Ces résultats seront extrêmement adaptés à la situation de cette personne.
En fait, cette même recherche effectuée à quelques pâtés de maisons peut faire apparaître un site complètement différent des résultats de Map Pack (ou les mêmes résultats dans un ordre différent).

Si vous suivez uniquement les classements locaux à partir d’un seul endroit (comme «New York»), vous ne voyez qu’un petit échantillon de votre classement dans le monde réel.
C'est pourquoi tu veux obtenir super granulaire avec vos classements locaux. De cette façon, vous pouvez voir où vous vous situez dans toute votre ville ou votre région.
Je recommande un outil appelé Faucon local pour ce genre de suivi détaillé de la carte.

Mais il y en a d'autres, comme Viking local, qui font à peu près la même chose.
En tous cas…
La première étape consiste à choisir le nom de votre entreprise (Remarque: ce flux provient directement de Google Maps. Pour utiliser cet outil, vous avez besoin d’un profil Google My Business déjà configuré).

Ensuite, choisissez un mot clé pour lequel vous souhaitez vérifier votre classement.

Enfin, choisissez le degré de spécificité ou le type de suivi de votre classement.
Par exemple, voici un rayon de suivi de 5 miles (8 km).

Elle est configurée avec une grille 7 x 7, ce qui vous donne une bonne idée de la position de votre entreprise dans cette zone.
(Cette grille peut aller jusqu'à 15 x 15 si vous voulez vraiment voir les limites de votre classement).
Ensuite, il est temps de vérifier le classement.
Une fois que l'outil a fait son travail, vous obtenez une interface visuelle qui affiche votre classement pour chaque position géographique:

Comme vous pouvez le constater, vous obtenez une belle carte interactive qui indique votre classement dans de nombreux endroits de la ville.
Comme vous pouvez le constater, les classements sont meilleurs à la périphérie de la ville… et empirent progressivement au fur et à mesure que vous vous rendez au centre-ville.

Ce n’est pas nécessairement un problème. Il se peut qu’un concurrent ait un emplacement plus central que votre hôtel. Donc, pour quelqu'un qui cherche à partir de cet endroit, Google considère que le concurrent est un meilleur choix.
Cela dit, vous devriez utiliser cet outil pour trouver des endroits où vous devriez «bien» vous classer… mais ne le faites pas.
Par exemple, vous pouvez constater que cette entreprise de pavage locale occupe le premier rang dans l'extrême nord de la ville… à un point près.

Donc, dans ce cas, vous voudriez cliquer sur le résultat pour voir qui vous devance:

Dans ce cas, un concurrent occupe le premier rang.
Mais si vous n'êtes pas satisfait du poste n ° 2, vérifiez l'adresse du concurrent dans sa liste. De cette façon, vous pouvez vérifier leur emplacement physique sur cette carte.

Et lorsque vous indiquez la position du compétiteur sur la carte du classement, vous pouvez comprendre pourquoi vous rencontrez des difficultés pour décrocher la place n ° 1.

L'explication simple est que cet emplacement de recherche est BEAUCOUP plus proche du concurrent. Il est donc parfaitement logique que Google veuille faire de ce concurrent le premier résultat.
Source link

3 orientations sur lesquelles travailler pour booster son site internet
Avoir un site vitrine pour présenter son activité, ses produits et services sur internet permet d’accroître ses revenus en touchant un plus large public. Mais, si votre site web ne génère pas de trafics, vous perdez votre investissement. Pour plus de visibilité pour propulser votre activité sur internet, il y a des points sur lesquels vous devrez vous axer. Découvrez 3 orientations, 3 clés indispensables pour booster votre site internet.
La gestion de votre webmarketing
 Récoltez autant d’adresses mail que vous le pouvez pour constituer une liste conséquente d’abonnés, et envoyez régulièrement des messages sur les nouveautés, de petits aspects qui les interpellaient. Incluez des liens vers votre site pour pousser à en savoir plus, en découvrir plus. Cette tactique appelée émailing est un puissant outil de marketing qui permet de gagner et de fidéliser des visiteurs sur son site.
Récoltez autant d’adresses mail que vous le pouvez pour constituer une liste conséquente d’abonnés, et envoyez régulièrement des messages sur les nouveautés, de petits aspects qui les interpellaient. Incluez des liens vers votre site pour pousser à en savoir plus, en découvrir plus. Cette tactique appelée émailing est un puissant outil de marketing qui permet de gagner et de fidéliser des visiteurs sur son site.
Selon les critères de votre activité, les caractéristiques et centres d’intérêt de vos clients, les outils de marketing varient. Il vous faut donc travailler sur votre clientèle actuelle pour mieux cerner ce qu’ils aiment, ce qu’ils pensent et surtout où les trouver. Cela vous permettra de leur présenter le bon produit au bon moment : le but même du marketing.
Sur ce site, un spécialiste dans l’optimisation de la visibilité sur les moteurs de recherche vous attend pour développer le potentiel de votre site internet. Cet expert free-lance a fait ses preuves avec les résidents en Bretagne et plus particulièrement à Rennes.
L’optimisation de votre contenu
Ce que vous publiez sur votre site déterminera le temps que passeront les internautes sur celui-ci, ainsi que son positionnement sur les moteurs de recherche.
Le titre et le lien principal de votre site internet doivent contenir les mots clés de votre activité et rester simples, faciles à mémoriser pour les visiteurs. Le texte que vous publiez sur votre site se doit de répondre succinctement aux besoins des internautes qui visitent, sans pour autant être trop court ni trop long, selon le thème à aborder. Ne vous contentez pas des mots clés habituels ou phares, insérez d’autres mots clés qui optimisent votre référencement.
De plus, l’utilisation de liens d’autorité et de qualité sur votre site augmentera les redirections vers votre site internet à partir d’autres sites web, dans votre secteur et dans la même langue. N’hésitez pas à ajouter des images, des vidéos, des GIF avec des légendes et des formats adaptés pour mieux illustrer ce que vous dites au public.
Votre activité sur les réseaux sociaux
Les réseaux sociaux drainent plus de monde qu’on ne l’imaginait, et offrent une large audience si le bon public est visé. Créez un compte et une page sur un réseau en tenant compte de votre activité et publiez régulièrement, en faisant du storytelling pour attirer plus de visiteurs sur votre site internet. Positionnez donc sur votre site des boutons de partage sur les réseaux sociaux.
N’hésitez pas non plus à faire la publicité payante : ce sera un petit investissement par rapport à ce que vous gagnerez plus tard grâce au site.

Tout ce que tu as besoin de savoir
Robots.txt est l’un des fichiers les plus simples sur un site Web, mais c’est aussi l’un des plus faciles à gâcher. Un seul personnage hors de propos peut faire des ravages sur votre SEO et empêchez les moteurs de recherche d’accéder à du contenu important sur votre site.
C’est pourquoi les erreurs de configuration de robots.txt sont extrêmement courantes, même parmi les utilisateurs expérimentés. SEO professionnels.
Dans ce guide, vous apprendrez:
Qu'est-ce qu'un fichier robots.txt?
Un fichier robots.txt indique aux moteurs de recherche où ils peuvent et ne peuvent pas aller sur votre site.
En premier lieu, il répertorie tout le contenu que vous souhaitez verrouiller en dehors des moteurs de recherche tels que Google. Vous pouvez également dire à certains moteurs de recherche (pas Google) Comment ils peuvent explorer le contenu autorisé.
note importante
La plupart des moteurs de recherche sont obéissants. Ils n’ont pas l’habitude de casser une entrée. Cela dit, certains n'hésitent pas à choisir quelques verrous métaphoriques.
Google n'est pas l'un de ces moteurs de recherche. Ils obéissent aux instructions d'un fichier robots.txt.
Sachez simplement que certains moteurs de recherche l'ignorent complètement.
À quoi ressemble un fichier robots.txt?
Voici le format de base d’un fichier robots.txt:
Plan du site: [URL location of sitemap] Agent utilisateur: [bot identifier] [directive 1] [directive 2] [directive ...] Agent utilisateur: [another bot identifier] [directive 1] [directive 2] [directive ...]
Si vous n’avez jamais vu l’un de ces fichiers auparavant, cela peut sembler décourageant. Cependant, la syntaxe est assez simple. En bref, vous attribuez des règles aux robots en indiquant leur agent utilisateur suivi par les directives.
Explorons ces deux composants plus en détail.
User-agents
Chaque moteur de recherche s'identifie avec un agent utilisateur différent. Vous pouvez définir des instructions personnalisées pour chacune d’elles dans votre fichier robots.txt. Il y a des centaines d'agents utilisateurs, mais en voici quelques unes utiles pour SEO:
- Google: Googlebot
- Google images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
Sidenote.
Tous les agents utilisateurs sont sensibles à la casse dans le fichier robots.txt.
Vous pouvez également utiliser le caractère générique étoile (*) pour attribuer des directives à tous les agents utilisateurs.
Par exemple, supposons que vous vouliez empêcher tous les robots, à l'exception de Googlebot, d'explorer votre site. Voici comment vous le feriez:
Agent utilisateur: * Interdit: / Agent utilisateur: Googlebot Autoriser: /
Sachez que votre fichier robots.txt peut inclure des directives pour autant d’agents d’utilisateur que vous le souhaitez. Cela dit, chaque fois que vous déclarez un nouvel agent utilisateur, cela agit comme une table rase. En d’autres termes, si vous ajoutez des directives pour plusieurs agents d’utilisateur, les directives déclarées pour le premier agent d’utilisateur ne s’appliquent pas aux deuxième, troisième, quatrième, etc.
L'exception à cette règle est lorsque vous déclarez le même agent d'utilisateur plus d'une fois. Dans ce cas, toutes les directives pertinentes sont combinées et suivies.
IMPORTANT REMARQUE
Les robots d'exploration ne suivent que les règles déclarées sous le ou les agents utilisateurs qui s'applique le plus précisément à eux. C’est pourquoi le fichier robots.txt ci-dessus bloque l’exploration du site par tous les robots sauf Googlebot (et les autres robots Google). Googlebot ignore la déclaration d'agent utilisateur moins spécifique.
Les directives
Les directives sont des règles que vous souhaitez que les agents utilisateurs déclarés respectent.
Directives supportées
Voici les directives actuellement prises en charge par Google, ainsi que leurs utilisations.
Refuser
Utilisez cette directive pour indiquer aux moteurs de recherche de ne pas accéder aux fichiers et aux pages qui se trouvent sous un chemin spécifique. Par exemple, si vous souhaitez empêcher tous les moteurs de recherche d'accéder à votre blog et à ses publications, votre fichier robots.txt peut ressembler à ceci:
Agent utilisateur: * Interdire: / blog
Sidenote.
Si vous ne parvenez pas à définir un chemin après la directive d'annulation, les moteurs de recherche l'ignoreront.
Autoriser
Utilisez cette directive pour permettre aux moteurs de recherche d'analyser un sous-répertoire ou une page, même dans un répertoire autrement non autorisé. Par exemple, si vous souhaitez empêcher les moteurs de recherche d'accéder à toutes les publications de votre blog, à l'exception d'une seule, votre fichier robots.txt peut alors ressembler à ceci:
Agent utilisateur: * Interdire: / blog Autoriser: / blog / allowed-post
Dans cet exemple, les moteurs de recherche peuvent accéder à / blog / allowed-post. Mais ils ne peuvent pas accéder à:
/ blog / autre-post/ blog / yet-another-post/blog/download-me.pdf
Google et Bing prennent en charge cette directive.
Sidenote.
Comme avec la directive interdire, si vous ne parvenez pas à définir un chemin après la directive allow, les moteurs de recherche l'ignoreront.
une note sur les règles contradictoires
À moins que vous ne soyez prudent, les directives d'annulation et d'autorisation peuvent facilement entrer en conflit. Dans l'exemple ci-dessous, nous interdisons l'accès à /Blog/ et permettant l'accès à /Blog.
Agent utilisateur: * Interdit: / blog / Autoriser: / blog
Dans ce cas, le URL / blog / post-titre / semble être à la fois rejeté et autorisé. Alors qui gagne?
Pour Google et Bing, la règle est que la directive contenant le plus de caractères l'emporte. Ici, c’est la directive interdire.
Interdit: / blog / (6 caractères)Autoriser: / blog (5 personnages)
Si les directives autoriser et interdire ont la même longueur, la directive la moins restrictive l'emporte. Dans ce cas, ce serait la directive d'autorisation.
Sidenote.
Ici, /Blog (sans la barre oblique finale) est toujours accessible et analysable.
Cruciale, ce n'est que le cas pour Google et Bing. D'autres moteurs de recherche écoutent la première directive correspondante. Dans ce cas, cela est interdit.
Plan du site
Utilisez cette directive pour spécifier l'emplacement de votre plan Sitemap sur les moteurs de recherche. Si vous ne connaissez pas bien les sitemaps, ils incluent généralement les pages que vous souhaitez que les moteurs de recherche explorent et indexent.
Voici un exemple de fichier robots.txt utilisant la directive sitemap:
Plan du site: https://www.domain.com/sitemap.xml Agent utilisateur: * Interdit: / blog / Autoriser: / blog / post-title /
Quelle est l’importance d’inclure votre ou vos sitemap (s) dans votre fichier robots.txt? Si vous avez déjà envoyé votre candidature via la console de recherche, il est quelque peu redondant pour Google. Cependant, il indique aux autres moteurs de recherche tels que Bing où trouver votre sitemap, donc c’est toujours une bonne pratique.
Notez qu'il n'est pas nécessaire de répéter la directive sitemap plusieurs fois pour chaque agent utilisateur. Cela ne s'applique pas à un seul. Il est donc préférable d’inclure les directives de sitemap au début ou à la fin de votre fichier robots.txt. Par exemple:
Plan du site: https://www.domain.com/sitemap.xml Agent utilisateur: Googlebot Interdit: / blog / Autoriser: / blog / post-title / Agent utilisateur: Bingbot Interdit: / services /
Google les soutiens la directive sitemap, tout comme Ask, Bing et Yahoo.
Sidenote.
Vous pouvez inclure autant de sitemaps que vous le souhaitez dans votre fichier robots.txt.
Directives non supportées
Voici les directives qui sont n'est plus supporté par Google– dont certains, techniquement, ne l'ont jamais été.
Délai d'attente
Auparavant, vous pouviez utiliser cette directive pour spécifier un délai d'analyse en secondes. Par exemple, si vous souhaitez que Googlebot attend 5 secondes après chaque analyse, définissez le délai d'analyse sur 5 comme suit:
Agent utilisateur: Googlebot Délai d'attente: 5
Google ne prend plus en charge cette directive, mais Bing et Yandex faire.
Cela dit, soyez prudent lorsque vous définissez cette directive, surtout si vous avez un grand site. Si vous définissez un délai d’exploration de 5 secondes, vous empêchez les robots d’exploiter 17 280 URL par jour au maximum. Ce n'est pas très utile si vous avez des millions de pages, mais cela pourrait économiser de la bande passante si vous avez un petit site Web.
Noindex
Cette directive n'a jamais été officiellement prise en charge par Google. Cependant, jusqu'à récemment, Google pensait qu'il existait un «code qui gère les règles non prises en charge et non publiées (telles que noindex)». Ainsi, si vous souhaitez empêcher Google d'indexer tous les articles de votre blog, vous pouvez utiliser la directive suivante:
Agent utilisateur: Googlebot Noindex: / blog /
Cependant, le 1er septembre 2019, Google a précisé que cette directive n'est pas supportée. Si vous souhaitez exclure une page ou un fichier des moteurs de recherche, utilisez la balise meta robots ou x-robots. HTTP en-tête à la place.
Pas de suivi
Il s'agit d'une autre directive que Google n'a jamais officiellement prise en charge. Elle permettait aux moteurs de recherche de ne pas suivre les liens sur les pages et les fichiers par un chemin spécifique. Par exemple, si vous souhaitez empêcher Google de suivre tous les liens de votre blog, vous pouvez utiliser la directive suivante:
Agent utilisateur: Googlebot Nofollow: / blog /
Google a annoncé que cette directive n'était pas officiellement prise en charge le 1er septembre 2019. Si vous souhaitez maintenant ne plus suivre tous les liens d'une page, vous devez utiliser la balise méta des robots ou l'en-tête x-robots. Si vous souhaitez empêcher Google de suivre des liens spécifiques sur une page, utilisez l'attribut rel = “nofollow”.
Avez-vous besoin d'un fichier robots.txt?
Avoir un fichier robots.txt n’est pas crucial pour beaucoup de sites Web, surtout les plus petits.
Cela dit, il n’ya aucune bonne raison de ne pas en avoir un. Il vous donne plus de contrôle sur les endroits où les moteurs de recherche peuvent et ne peuvent pas aller sur votre site Web, ce qui peut vous aider dans les domaines suivants:
- Prévenir l'exploration de dupliquer le contenu;
- Garder les sections d'un site Web privées (par exemple, votre site intermédiaire);
- Empêcher l'exploration des pages de résultats de recherche internes;
- Prévenir la surcharge du serveur;
- Empêcher le gaspillage de Google “budget d'analyse. "
- Prévenir images, vidéosEt des fichiers de ressources apparaissant dans les résultats de recherche Google.
Notez que bien que Google n’indexe généralement pas les pages Web bloquées dans le fichier robots.txt, Il n’existe aucun moyen de garantir l’exclusion des résultats de la recherche à l’aide du fichier robots.txt..
Comme Google ditSi le contenu est lié à d’autres endroits sur le Web, il peut toujours apparaître dans les résultats de recherche Google.
Comment trouver votre fichier robots.txt
Si vous avez déjà un fichier robots.txt sur votre site Web, il sera accessible à l'adresse suivante: domaine.com/robots.txt. Accédez au URL dans votre navigateur. Si vous voyez quelque chose comme ceci, alors vous avez un fichier robots.txt:

Comment créer un fichier robots.txt
Si vous ne possédez pas déjà un fichier robots.txt, il est facile de le créer. Ouvrez simplement un document .txt vierge et commencez à taper des directives. Par exemple, si vous souhaitez interdire à tous les moteurs de recherche d’analyser votre / admin / répertoire, cela ressemblerait à quelque chose comme ça:
Agent utilisateur: * Interdit: / admin /
Continuez à élaborer les directives jusqu’à ce que vous soyez satisfait de ce que vous avez. Enregistrez votre fichier sous le nom «robots.txt».
Alternativement, vous pouvez également utiliser un générateur robots.txt comme celui-là.
L'avantage d'utiliser un outil comme celui-ci est qu'il minimise les erreurs de syntaxe. C’est bien parce qu’une erreur peut entraîner une SEO catastrophe pour votre site – il est donc utile de pécher par excès de prudence.
L’inconvénient est qu’ils sont quelque peu limités en termes de personnalisation.
Où placer votre fichier robots.txt
Placez votre fichier robots.txt dans le répertoire racine du sous-domaine auquel il s’applique. Par exemple, pour contrôler le comportement d’exploration sur domain.com, le fichier robots.txt doit être accessible à l’adresse suivante: domaine.com/robots.txt.
Si vous souhaitez contrôler l’exploration sur un sous-domaine tel que blog.domain.com, le fichier robots.txt doit être accessible à l’adresse suivante: blog.domain.com/robots.txt.
Meilleures pratiques du fichier Robots.txt
Gardez cela à l'esprit pour éviter les erreurs courantes.
Utilisez une nouvelle ligne pour chaque directive
Chaque directive doit être placée sur une nouvelle ligne. Sinon, les moteurs de recherche seront confondus.
Mauvais:
Agent utilisateur: * Interdit: / répertoire / Interdit: / autre-répertoire /
Bien:
Agent utilisateur: * Interdit: / répertoire / Interdit: / autre-répertoire /
Utiliser des caractères génériques pour simplifier les instructions
Vous pouvez non seulement utiliser des caractères génériques (*) pour appliquer des directives à tous les agents utilisateur, mais également URL modèles lors de la déclaration de directives. Par exemple, si vous souhaitez empêcher les moteurs de recherche d'accéder aux URL de catégorie de produit paramétrées sur votre site, vous pouvez les répertorier comme suit:
Agent utilisateur: * Interdit: / produits / t-shirts? Interdit: / produits / hoodies? Interdit: / produits / vestes? …
Mais ce n’est pas très efficace. Il serait préférable de simplifier les choses avec un caractère générique comme celui-ci:
Agent utilisateur: * Interdit: / produits / *?
Cet exemple empêche les moteurs de recherche d'analyser toutes les URL du sous-dossier / product / qui contiennent un point d'interrogation. En d'autres termes, toute URL de catégorie de produit paramétrée.
Utilisez “$” pour spécifier la fin d'un URL
Inclure le symbole «$» pour marquer la fin d’un URL. Par exemple, si vous souhaitez empêcher les moteurs de recherche d'accéder à tous les fichiers .pdf de votre site, votre fichier robots.txt peut ressembler à ceci:
Agent utilisateur: * Interdit: /*.pdf
Dans cet exemple, les moteurs de recherche ne peuvent accéder aux URL se terminant par .pdf. Cela signifie qu’ils ne peuvent pas accéder à /file.pdf, mais à /file.pdf?id=68937586 car cela ne se termine pas par “.pdf”.
Utilisez chaque utilisateur-agent une seule fois
Si vous spécifiez le même agent utilisateur à plusieurs reprises, cela ne dérange pas Google. Il combinera simplement toutes les règles des différentes déclarations en une et les suivra toutes. Par exemple, si vous aviez les directives et agents utilisateur suivants dans votre fichier robots.txt…
Agent utilisateur: Googlebot Interdit: / a / Agent utilisateur: Googlebot Interdit: / b /
… Googlebot ne serait pas analyser l'un ou l'autre de ces sous-dossiers.
Cela dit, il est judicieux de déclarer chaque agent utilisateur une seule fois, car cela crée moins de confusion. En d’autres termes, vous êtes moins susceptible de faire des erreurs critiques en gardant les choses ordonnées et simples.
Utilisez la spécificité pour éviter les erreurs non intentionnelles
L'omission de fournir des instructions spécifiques lors de la définition des directives peut entraîner des erreurs facilement omises pouvant avoir un impact catastrophique sur votre système. SEO. Par exemple, supposons que vous avez un site multilingue et que vous travaillez sur une version allemande qui sera disponible dans le sous-répertoire / de /.
Parce que ce n’est pas tout à fait prêt, vous voulez empêcher les moteurs de recherche d’y accéder.
Le fichier robots.txt ci-dessous empêchera les moteurs de recherche d'accéder à ce sous-dossier et à tout ce qu'il contient:
Agent utilisateur: * Interdit: / de
Mais cela empêchera également les moteurs de recherche d’analyser les pages ou les fichiers commençant par / de.
Par exemple:
/ robes de créateurs //delivery-information.html/ depeche-mode / t-shirts //definitely-not-for-public-viewing.pdf
Dans ce cas, la solution est simple: ajoutez une barre oblique finale.
Agent utilisateur: * Interdit: / de /
Utilisez des commentaires pour expliquer votre fichier robots.txt aux humains
Les commentaires aident à expliquer votre fichier robots.txt aux développeurs, voire même à votre avenir. Pour inclure un commentaire, commencez la ligne par un dièse (#).
# Ceci indique à Bing de ne pas explorer notre site. Agent utilisateur: Bingbot Interdit: /
Les robots ignorent tout sur les lignes commençant par un hachage.
Utilisez un fichier robots.txt distinct pour chaque sous-domaine.
Robots.txt contrôle uniquement le comportement d’exploration sur le sous-domaine où il est hébergé. Si vous souhaitez contrôler l’exploration dans un sous-domaine différent, vous aurez besoin d’un fichier robots.txt distinct.
Par exemple, si votre site principal est installé sur domain.com et votre blog est assis sur blog.domain.com, vous auriez alors besoin de deux fichiers robots.txt. L'un doit aller dans le répertoire racine du domaine principal et l'autre dans le répertoire racine du blog.
Exemple de fichiers robots.txt
Vous trouverez ci-dessous quelques exemples de fichiers robots.txt. Celles-ci sont principalement d’inspiration, mais si l’on en trouve une qui correspond à vos exigences, copiez-le dans un document texte, enregistrez-le sous le nom “robots.txt” et chargez-le dans le répertoire approprié.
All-Access pour tous les robots
Agent utilisateur: * Refuser:
Sidenote.
A défaut de déclarer un URL après qu'une directive rend cette directive redondante. En d'autres termes, les moteurs de recherche l'ignorent. C’est pourquoi cette directive d’annulation n’a aucun effet sur le site. Les moteurs de recherche peuvent toujours analyser toutes les pages et tous les fichiers.
Pas d'accès pour tous les robots
Agent utilisateur: * Interdit: /
Bloquer un sous-répertoire pour tous les robots
Agent utilisateur: * Interdit: / dossier /
Bloquer un sous-répertoire pour tous les robots (avec un seul fichier autorisé)
Agent utilisateur: * Interdit: / dossier / Autoriser: / répertoire / page.html
Bloquer un fichier pour tous les robots
Agent utilisateur: * Interdit: /this-is-a-file.pdf
Bloquer un type de fichier (PDF) pour tous les robots
Agent utilisateur: * Interdit: /*.pdf
Bloquer toutes les URL paramétrées pour Googlebot uniquement
Agent utilisateur: Googlebot Interdit: / *?
Comment vérifier votre fichier robots.txt pour les erreurs
Les erreurs de Robots.txt peuvent facilement glisser à travers le filet, il est donc utile de garder un œil ouvert sur les problèmes.
Pour ce faire, recherchez régulièrement les problèmes liés à robots.txt dans le rapport «Couverture» de Console de recherche. Vous trouverez ci-dessous certaines des erreurs que vous pouvez voir, ce qu’elles signifient et comment les corriger.
Besoin de vérifier les erreurs liées à une page donnée?
Coller un URL dans Google URL Outil d'inspection dans la console de recherche. S'il est bloqué par le fichier robots.txt, vous devriez voir quelque chose comme ceci:
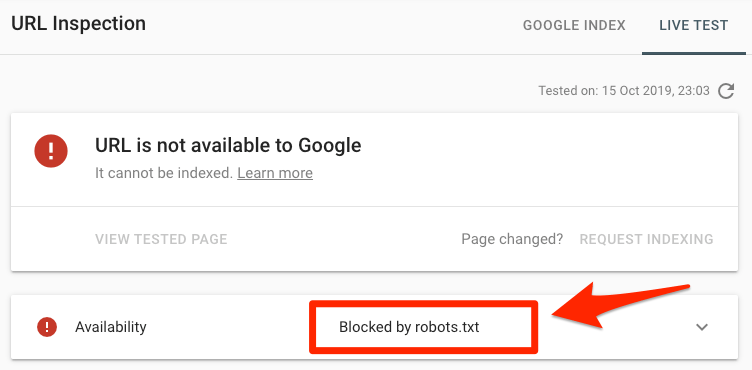
Soumis URL bloqué par robots.txt
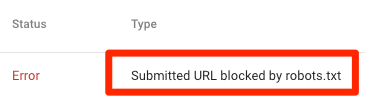
Cela signifie qu'au moins une des URL des plans de votre site soumis est bloquée par le fichier robots.txt.
Si vous créé votre sitemap correctement et exclu canonisé, noindexed, et redirigé pages, puis aucune page soumise ne doit être bloquée par robots.txt. Si tel est le cas, recherchez quelles pages sont affectées, puis ajustez votre fichier robots.txt en conséquence pour supprimer le bloc de cette page.
Vous pouvez utiliser Le test de robots.txt de Google pour voir quelle directive bloque le contenu. Faites attention en faisant ceci. Il est facile de faire des erreurs qui affectent d’autres pages et fichiers.
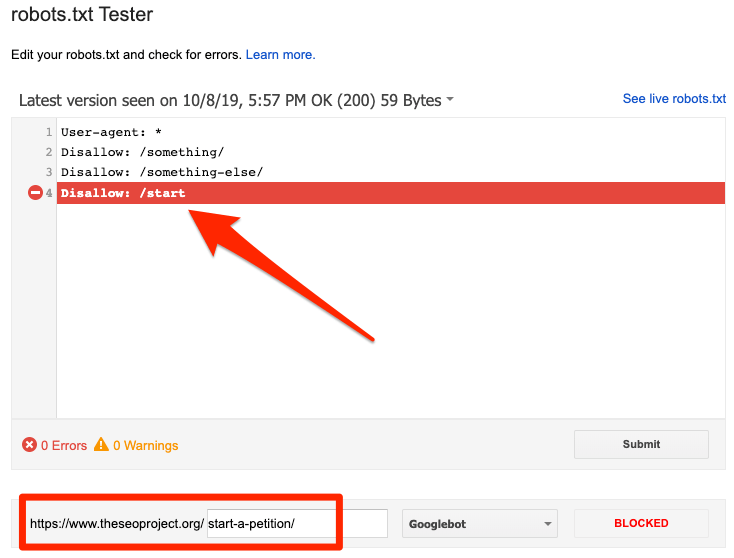
Bloqué par robots.txt
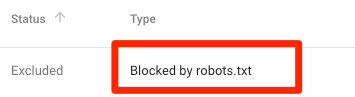
Cela signifie que votre fichier est bloqué par le fichier robots.txt qui n'est pas encore indexé dans Google.
Si ce contenu est important et doit être indexé, supprimez le bloc d'analyse dans le fichier robots.txt. (Cela vaut également la peine de s’assurer que le contenu n’est pas non indexé). Si vous avez bloqué le contenu du fichier robots.txt dans l’intention de l’exclure de l’index de Google, supprimez le bloc d’exploration et utilisez plutôt une balise méta ou un en-tête x-robots. C’est le seul moyen de garantir l’exclusion du contenu de l’index de Google.
Sidenote.
La suppression du bloc d'analyse lors d'une tentative d'exclusion d'une page des résultats de la recherche est cruciale. Si vous ne le faites pas, Google ne verra pas le tag noindex ni HTTP en-tête, donc il restera indexé.
Indexé, bien que bloqué par robots.txt
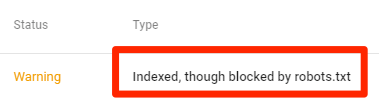
Cela signifie qu'une partie du contenu bloqué par robots.txt est toujours indexée dans Google.
Encore une fois, si vous essayez d’exclure ce contenu des résultats de recherche de Google, le fichier robots.txt n’est pas la bonne solution. Supprimez le bloc d’exploration et utilisez plutôt un balise meta robots ou balise x ‑ robots HTTP entête pour empêcher l'indexation.
Si vous avez bloqué ce contenu par accident et que vous souhaitez le conserver dans l'index de Google, supprimez le bloc d'analyse dans le fichier robots.txt. Cela peut aider à améliorer la visibilité du contenu dans la recherche Google.
FAQ
Voici quelques questions fréquemment posées qui ne rentrent pas naturellement dans notre guide. Faites-nous savoir dans les commentaires si quelque chose manque, et nous mettrons à jour la section en conséquence.
Quelle est la taille maximale d’un fichier robots.txt?
500 kilo-octets (grossièrement).
Où est le fichier robots.txt dans WordPress?
Même endroit: domaine.com/robots.txt.
Comment modifier le fichier robots.txt dans WordPress?
Soit manuellement, soit en utilisant l’un des les nombreux WordPress SEO plugins comme Yoast qui vous permet de modifier le fichier robots.txt à partir du backend de WordPress.
Que se passe-t-il si j'autorise l'accès au contenu non indexé dans le fichier robots.txt?
Google ne verra jamais la directive noindex car il ne peut pas explorer la page.
DYK bloquer une page à la fois avec un fichier robots.txt interdit Et un noindex dans la page n'a pas beaucoup de sens car Googlebot ne peut pas "voir" le noindex? pic.twitter.com/N4639rCCWt– Gary “理” Illyes (@methode) 10 février 2017
Dernières pensées
Robots.txt est un fichier simple mais puissant. Utilisez-le judicieusement, et cela peut avoir un impact positif sur SEO. Utilisez-le au hasard et, eh bien, vous vivrez à le regretter.
Vous avez plus de questions? Laisser un commentaire ou ping moi sur Twitter.

Comment éduquer les clients sur le référencement et gagner leur confiance

J'ai constaté que la plupart de mes clients connaissaient un peu le SEO, mais ils ne savaient pas exactement comment le faire fonctionner pour eux aussi bien qu'il le devrait. Enseigner le référencement aux clients doit faire partie des services de gestion des clients que vous fournissez lors des présentations de vente SEO.
Le référencement est un vaste sujet qui couvre beaucoup de terrain. Le défi consiste à expliquer comment le référencement consiste à communiquer toutes les manières dont vous pouvez améliorer le référencement en des termes que les clients peuvent comprendre, de sorte que cela ne ressemble plus tellement à une langue étrangère.
J’ai constaté que mes clients comprenaient mieux la valeur du référencement lorsque je pouvais les aider à comprendre son importance dans les plans de marketing numérique d’aujourd’hui et à leur en parler sans être trop technique.
J'ai trouvé des moyens efficaces pour lancer Services de référencement et avec leur aide, je développe un plan de référencement personnalisé conçu pour le succès. Les points partagés ci-dessous vous aideront à transmettre de nombreuses informations cruciales à vos clients.
Pourquoi le référencement est nécessaire pour votre entreprise
Lorsque j'enseigne le référencement aux nouveaux clients et leur montre comment démontrer leur valeur, je garde trois choses à l'esprit:
- Expliquez le référencement en utilisant un langage qui leur est familier
- Démontrer que le référencement est toujours d'actualité
- Expliquez la valeur du référencement de la manière la plus simple possible
Pour faire connaissance avec mes clients, j’aimerais commencer par expliquer que le référencement est un outil essentiel du succès, en tant que point de départ d’une conversation plus pointue sur la façon de montrer la valeur du référencement.
Les clients qui ne se dépêchent pas d’embrasser le référencement, à moins de comprendre parfaitement une chose simple: le nouveau mode hors connexion en ligne. Pratiquement toutes les entreprises sont désormais présentes en ligne et les gens ont l'habitude de tout faire en ligne.
Pourquoi faire du référencement? Les clients doivent se concentrer sur le référencement, car les gens vont à Google pour explorer presque tout, des symptômes médicaux aux nouveaux restaurants. Cela souligne à nouveau que online est le nouveau offline. La recherche organique est la principale source de trafic sur la plupart des sites Web, et votre visibilité en ligne dépend en grande partie de votre classement dans Google. Si vous décidez de sortir dîner dans un bon restaurant italien ce soir, vous pourrez naviguer en ligne et trouver des restaurants de votre région dans Google Maps, consulter les photos, le menu et lire les avis.
Points importants à mentionner pour expliquer pourquoi le référencement est important
- La recherche organique est la principale source de trafic Web
- Le référencement crée la confiance dans vos produits et votre entreprise
- Le référencement améliore le cycle d’achat car il place votre entreprise là où le public est
Si la plupart des clients savent ce que signifie le référencement, ils ne sont généralement pas aussi familiarisés avec les termes associés. J'essaie d'évaluer leur base de connaissances en SEO aussi rapidement que possible afin de pouvoir combler leurs lacunes en matière de connaissances.
Pourquoi Educate clients sur le référencement?
Fournir des services de référencement ne consiste pas uniquement à obtenir des résultats, même si c’est une grande partie de celle-ci. Notre société est plus férue de technologie qu'avant. Il est important de donner crédit à nos clients pour ce qu’ils savent et de les éduquer sur les facteurs «en coulisse» avec lesquels ils travaillent. SEO.
Le référencement est un outil précieux et lorsque nous pouvons aider nos clients à mieux comprendre son fonctionnement, ils peuvent en voir plus facilement la valeur. Notre crédibilité et nos moyens de subsistance en tant que professionnels du référencement dépendent de notre capacité à expliquer et à démontrer la valeur.
J'ai récemment eu une conversation avec Eugene Levin, CSO de SEMrush, qui estime qu’il est important d’éduquer les dirigeants dans les entreprises.
Voici ce qu’il a dit
«Nous faisons de notre mieux pour éduquer nos employés et nos clients. Chacun de nos employés doit comprendre le référencement et savoir utiliser SEMrush et tous ses outils. Alors que nous rencontrons souvent les clients, nous rencontrons souvent des tactiques sur mesure qui les aideraient à accroître leur visibilité en ligne et à augmenter leurs ventes. Nous rencontrons les équipes de référencement des entreprises et trouvons des moyens encore plus efficaces d’améliorer les classements en ligne. "
Donner une pensée plus profonde à l'éducation du client
Les compétences en référencement sont importantes, mais n’oubliez pas qu’il est important d’assurer à vos clients que vous êtes un spécialiste qui peut les aider à faire évoluer leurs activités. Vos clients ne seront pas satisfaits si vous leur envoyez des liens uniquement sur des blogs, des vidéos ou des courriels d’information marketing. Il faut du temps, du travail et de l’énergie pour éduquer les clients, mais vos compétences en gestion de client finiront par porter leurs fruits.
Au fur et à mesure que vous passez plus de temps avec vos clients, ils en apprendront un peu plus à chaque fois sur le référencement, ce qui renforcera leur confiance en vous en tant que leur conseiller en référencement et renforcera la confiance mutuelle entre vous. Si vous êtes un expert en référencement, n’oubliez pas qu’ils sont les experts de leur activité. Leur contribution lors de collaborations est un élément essentiel de leur succès ultime en référencement. campagnes.
1. Clarifier les objectifs et les attentes
Je m'assure que les objectifs et le flux de travail sont clairs, de sorte que le rapport concorde avec les livrables mensuels. Ce sont les détails qui prouvent à quel point vous travaillez dur pour vos clients.
2. Partager les rapports
Au cours de la planification visant à améliorer les résultats en matière de référencement, les clients apprendront qu’il leur faut beaucoup plus de temps que prévu. Pour les aider à réaliser cela, je partage toujours des rapports tels que ceux mentionnés ci-dessous:
- Reporting dans les appels
- Courriels
- Rapports avec KPI personnalisés
3. Rendre le référencement facile à comprendre pour vos clients
Tandis que je forme mes clients aussi bien que possible lorsque je les rencontre, je complète mes enseignements par des blogs sur mon site qui correspondent à différents aspects du référencement en tant que ressources s'ils souhaitent en savoir plus sur un aspect particulier du référencement. Au fil du temps, ils se fieront à mon site pour obtenir les dernières informations en matière de référencement, ce qui est un excellent moyen de réutiliser votre contenu. Ils vont probablement même le partager avec d'autres, ce qui aidera à développer votre entreprise.
Chaque client étant dans un endroit différent pour comprendre ses besoins en marketing numérique, j'essaie donc d'adapter mon enseignement à son niveau de compréhension.
Mon processus d’éducation des clients implique une ou plusieurs des étapes suivantes:
- Apprendre ce que le client sait sur le référencement et Internet
- Déterminer leur style d'apprentissage
- Décomposer le sens du référencement et ce qu'il fait
- Choisir une analogie qui a du sens pour eux
4. Évaluez le niveau de compréhension de votre client
Lors de discussions avec les clients, je les regarde dans les yeux. Si je commence à avoir des regards perplexes lorsque je mentionne des éléments tels que les moteurs de recherche et les backlinks, cela m'aide à comprendre si je dois expliquer certains termes techniques ou si je peux proposer une définition simple et passer à autre chose.
5. Comprendre et choisir un style d'apprentissage idéal pour votre client
Je sais qu'il existe trois principaux styles d'apprentissage: verbal, visuel et physique. L'utilisation d'un ou plusieurs de ces styles aide à faire ressortir certains points.
Je sais que certains de mes clients s'en sortent bien lorsque nous discutons en personne ou au téléphone. D'autres clients ont besoin d'un graphique, d'un diagramme ou d'un simple dessin. Les apprenants physiques ont besoin de moi pour démontrer le concept. La meilleure façon de le faire est de leur donner une analogie ou de leur montrer un exemple sur ordinateur.
Les clients novices en technologie peuvent avoir besoin de comprendre ce qu'est le référencement. Je commencerai donc par expliquer que l'acronyme, optimisation des moteurs de recherche, est. J'explique également ce que signifie l'optimisation et comment il est utile de classer les sites Web plus haut sur une page et comment l'autorité donne au moteur de recherche un moyen de classer son importance.
6. Utiliser des analogies pour rendre le référencement accessible
Enfin, une analogie est toujours un excellent outil d’enseignement car elle offre à mes clients un moyen de comparer un concept complexe. Au cours de la discussion, je saisis généralement un commentaire qu'ils ont fait. S'ils ont mentionné qu'ils étaient en retard parce qu'ils devaient rencontrer leur agent d'assurance, je présente un exemple utilisant le même contexte dans lequel je peux montrer comment un agent d'assurance peut utiliser le référencement pour se classer bien sur une page Web.
Son agent d'assurance a un site web. Très probablement, l'agent a un blog et des témoignages. Plus l'agent a de contenu, plus le classement du site. Un classement plus élevé signifie que le site de l'agent tire parti des titres, des descriptions de produits et des résumés. Il aura des photos et des vidéos et un lien vers d'autres pages. Étant donné que l'agent recherche des entreprises locales, il ciblera les clients situés dans un certain rayon du bureau. L’agent peut également avoir un public cible de personnes mariées propriétaires d’une maison. Il est donc important pour elles de faire de la publicité dans des lieux susceptibles d’attirer ce marché plutôt que vers des sites en ligne qui attirent la millénaire.
Pointe supplémentaire
Je passe souvent du temps sur les sites Web de mes clients avant un rendez-vous. Cela me donne d’autres possibilités d’appliquer certains des concepts dont nous discutons au travail que nous pouvons commencer à faire ensemble.
Note de clôture
Je n'avais jamais imaginé que l'enseignement ferait partie de mon travail de marketing numérique. Ce que j’apprécie le plus dans la gestion des clients de mon travail, c’est que je recherche continuellement de nouvelles informations sur le référencement et que cela me donne envie de les partager avec mes clients. C’est gratifiant pour nous deux de partager des détails qui les aideront à réussir.
Lequel de ces conseils pratiqueriez-vous pour éduquer les clients sur le référencement? N'hésitez pas à partager vos réflexions, expériences et conseils dans la section commentaires.
Karina Tama est une collaboratrice de Forbes, Thrive Global et du journal El Distrito. Elle peut être trouvée sur Twitter .
Lecture connexe

Google embauche de vrais humains appelés "Rateurs de qualité de recherche". Le niveau de qualité de la page (QP) est une note attribuée après avoir analysé «dans quelle mesure une page remplit son objectif».

Créer un contenu pratique convivial pour le référencement est un bon moyen d'impliquer votre public, d'alimenter le référencement et d'assumer le parcours client de la notoriété à la vente.

Et si je vous disais que l'accessibilité et le référencement naturel vont de pair? Voyons comment cela peut être fait avec la structure de site et de page, les images, etc.

Cela fait huit ans que le schéma a été introduit, de nombreuses marques n’ont pas encore implémenté ce schéma. Découvrez quelles sont les données structurées avec les échantillons et leurs avantages.
Source link

